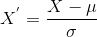Introduction à la mise à l’échelle des fonctionnalités
je travaillais récemment avec un ensemble de données qui avait plusieurs fonctionnalités couvrant différents degrés de magnitude, C’est un obstacle que quelques algorithmes d’apprentissage automatique sont très sensibles à ces fonctionnalités.
je suis sûr que la plupart d’entre vous ont dû faire face à ce problème dans vos projets ou votre parcours d’apprentissage., Par exemple, une fonctionnalité est entièrement en kilogrammes, tandis que l’autre est en grammes, un autre est en litres, et ainsi de suite. Comment Pouvons-nous utiliser ces fonctionnalités quand elles varient si fortement en termes de ce qu’elles présentent?
c’est là que je me suis tourné vers le concept de mise à l’échelle des entités. C’est une partie cruciale de l’étape de prétraitement des données, mais j’ai vu beaucoup de débutants l’ignorer (au détriment de leur modèle d’apprentissage automatique).,

Voici la chose curieuse à propos de la mise à l’échelle des fonctionnalités – elle améliore (de manière significative) les performances de certains algorithmes d’apprentissage automatique et ne fonctionne pas du tout pour les autres. Quelle pourrait être la raison derrière cette bizarrerie?
aussi, Quelle est la différence entre la normalisation et la normalisation? Ce sont deux des techniques de mise à l’échelle des fonctionnalités les plus couramment utilisées dans l’apprentissage automatique, mais leur compréhension présente un niveau d’ambiguïté. Quand devriez-vous utiliser quelle technique?,
je vais répondre à ces questions et plus dans cet article sur la mise à l’échelle des fonctionnalités. Nous allons également implémenter la mise à l’échelle des fonctionnalités en Python pour vous donner une compréhension pratique de la façon dont cela fonctionne pour différents algorithmes d’apprentissage automatique.
remarque: je suppose que vous connaissez les algorithmes Python et core machine learning., Si vous êtes nouveau dans ce domaine, je vous recommande de suivre les cours ci-dessous:
- Python for Data Science
- tous les Cours gratuits D’apprentissage automatique par Analytics Vidhya
- Applied Machine Learning
table des matières
- Pourquoi devrions-nous utiliser la mise à l’échelle des fonctionnalités?
- qu’est-Ce que la Normalisation?
- qu’est-Ce que la Normalisation?
- La Grande Question – normaliser ou standardiser?,
- mise en œuvre de la mise à l’échelle des fonctionnalités en Python
- normalisation à L’aide de Sklearn
- normalisation à L’aide de Sklearn
- application de la mise à l’échelle des fonctionnalités aux algorithmes D’apprentissage automatique
- k-Nearest neighbors (KNN)
- Support Vector Regressor
- Arbre de décision
Pourquoi devrions-nous
la première question que nous devons aborder – pourquoi avons-nous besoin de mettre à l’échelle les variables de notre ensemble de données? Certains algorithmes d’apprentissage automatique sont sensibles à la mise à l’échelle des fonctionnalités tandis que d’autres y sont pratiquement invariants., Laissez-moi expliquer que dans plus de détails.
algorithmes basés sur la descente de Gradient
algorithmes D’apprentissage automatique comme la régression linéaire, la régression logistique, le réseau neuronal, etc. pour utiliser la descente de gradient comme technique d’optimisation, les données doivent être mises à l’échelle. Jetez un oeil à la formule de la descente de gradient ci-dessous:

La présence de la fonction valeur de X dans la formule affectera la taille du pas de la descente de gradient. La différence dans les plages de fonctionnalités entraînera des tailles de pas différentes pour chaque fonctionnalité., Pour s’assurer que la descente de gradient se déplace en douceur vers les minima et que les étapes de descente de gradient sont mises à jour au même rythme pour toutes les fonctionnalités, nous mettons à l’échelle les données avant de les transmettre au modèle.
avoir des caractéristiques sur une échelle similaire peut aider la descente de gradient à converger plus rapidement vers les minima.
algorithmes basés sur la Distance
les algorithmes de Distance tels que KNN, K-means et SVM sont les plus affectés par la gamme de fonctionnalités., En effet, dans les coulisses, ils utilisent les distances entre les points de données pour déterminer leur similitude.
par exemple, disons que nous avons des données contenant les scores CGPA des élèves du secondaire (allant de 0 à 5) et leurs revenus futurs (en milliers de roupies):

étant donné que les deux caractéristiques ont des échelles différentes, il y a une chance Cela aura un impact sur les performances de l’algorithme d’apprentissage automatique et, évidemment, nous ne voulons pas que notre algorithme soit biaisé vers une fonctionnalité.,
par conséquent, nous mettons à l’échelle nos données avant d’utiliser un algorithme basé sur la distance afin que toutes les fonctionnalités contribuent également au résultat.,nts A et B, et entre B et C, avant et après la mise à l’échelle comme indiqué ci-dessous:
- Distance AB avant la mise à l’échelle =>

- Distance BC avant la mise à l’échelle =>

- distance AB après la mise à l’échelle =>

- distance BC après la mise à l’échelle =>

la mise à l’échelle a apporté à la fois les caractéristiques dans l’image et les distances sont maintenant plus comparables qu’elles ne l’étaient avant que nous appliquions la mise à l’échelle.,
algorithmes basés sur les arbres
les algorithmes basés sur les arbres, en revanche, sont assez insensibles à l’échelle des fonctionnalités. Pensez-y, un arbre de décision ne divise qu’un nœud basé sur une seule fonctionnalité. L’arbre de décision divise un nœud sur une entité qui augmente l’homogénéité du nœud. Cette division sur une fonctionnalité n’est pas influencée par d’autres fonctionnalités.
Il n’y a donc pratiquement aucun effet des fonctionnalités restantes sur la division. C’est ce qui les rend invariants à l’échelle des fonctionnalités!
qu’est-Ce que la Normalisation?,
la normalisation est une technique de mise à l’échelle dans laquelle les valeurs sont décalées et redimensionnées de sorte qu’elles finissent par se situer entre 0 et 1. Il est également connu sous le nom de mise à l’échelle Min-Max.
Voici la formule pour la normalisation:
Ici, Xmax et Xmin sont les valeurs maximale et minimale de la fonction respectivement.,
- Lorsque la valeur de X est la valeur minimale dans la colonne, le numérateur sera 0, et donc X’ 0
- en revanche, lorsque la valeur de X est la valeur maximale de la colonne, le numérateur est égal au dénominateur et donc la valeur de X’ 1
- Si la valeur de X est comprise entre le minimum et le maximum de la valeur, alors la valeur de X est entre 0 et 1
qu’est-Ce que la Normalisation?
La standardisation est une autre technique de mise à l’échelle où les valeurs sont centrées autour de la moyenne avec un écart type unitaire., Cela signifie que la moyenne de l’attribut devient nulle et que la distribution résultante a un écart type unitaire.
Voici la formule de normalisation:
est la moyenne des valeurs de fonction et
est l’écart-type des valeurs de fonction. Notez que dans ce cas, les valeurs ne sont pas limitées à une plage particulière.
maintenant, la grande question dans votre esprit doit être quand devrions-nous utiliser la normalisation et quand devrions-nous utiliser la normalisation? Voyons!,
la grande Question – normaliser ou standardiser?
normalisation vs standardisation est une question éternelle chez les nouveaux arrivants en apprentissage automatique. Permettez-moi de développer la réponse dans cette section.
- La normalisation est bonne à utiliser lorsque vous savez que la distribution de vos données ne suit pas une distribution gaussienne. Cela peut être utile dans les algorithmes qui ne supposent aucune distribution des données comme les K-voisins les plus proches et les réseaux de neurones.
- La normalisation, en revanche, peut être utile dans les cas où les données suivent une distribution gaussienne., Cependant, cela ne doit pas nécessairement être vrai. De plus, contrairement à la normalisation, la normalisation n’a pas de plage de délimitation. Ainsi, même si vous avez des valeurs aberrantes dans vos données, elles ne seront pas affectées par la normalisation.
Cependant, à la fin de la journée, le choix de la normalisation ou la standardisation dépendra de votre problème et de l’algorithme d’apprentissage automatique que vous utilisez. Il n’y a pas de règle stricte et rapide pour vous dire quand normaliser ou standardiser vos données., Vous pouvez toujours commencer par adapter votre modèle aux données brutes, normalisées et normalisées et comparer les performances pour obtenir de meilleurs résultats.
Il est recommandé d’adapter le détartreur sur les données d’entraînement, puis de l’utiliser pour transformer les données de test. Cela éviterait toute fuite de données pendant le processus de test du modèle. En outre, la mise à l’échelle des valeurs cibles n’est généralement pas requise.
implémentation de la mise à l’échelle des fonctionnalités en Python
vient maintenant la partie amusante – mettre en pratique ce que nous avons appris., Je vais appliquer la mise à l’échelle des fonctionnalités à quelques algorithmes d’apprentissage automatique sur L’ensemble de données Big Mart que j’ai pris la plate-forme DataHack.
je vais ignorer les étapes de prétraitement car elles sont hors du champ d’application de ce tutoriel. Mais vous pouvez les trouver soigneusement expliqués dans cet article. Ces étapes vous permettront d’atteindre le haut 20 percentile sur le hackathon leaderboard donc cela vaut la peine de vérifier!
divisons donc d’abord nos données en ensembles de formation et de test:
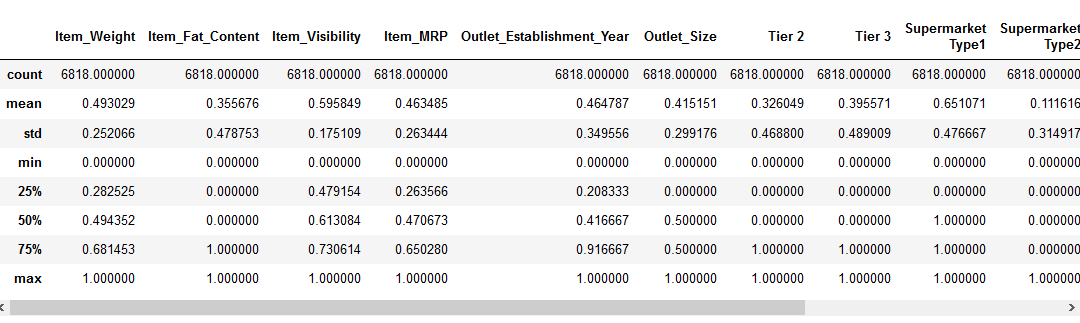
avant de passer à la partie mise à l’échelle des fonctionnalités, examinons les détails de nos données à l’aide du pd.,méthode describe ():
Nous pouvons voir qu’il y a une énorme différence dans la plage de valeurs présentes dans nos caractéristiques numériques: Item_Visibility, Item_Weight, Item_MRP et Outlet_Establishment_Year. Essayons de résoudre ce problème en utilisant la mise à l’échelle des fonctionnalités!
Remarque: vous remarquerez des valeurs négatives dans la fonctionnalité Item_Visibility car j’ai pris la transformation log pour gérer l’asymétrie dans la fonctionnalité.
normalisation avec sklearn
pour normaliser vos données, vous devez importer le MinMaxScalar de la bibliothèque sklearn et l’appliquer à notre ensemble de données., Alors, faisons-le!
nous allons voir comment la normalisation a affecté notre base de données:
Toutes les caractéristiques ont une valeur minimale de 0 et une valeur maximale de 1. Parfait!
essayez le code ci-dessus dans la fenêtre de codage en direct ci-dessous!!
ensuite, essayons de standardiser nos données.
normalisation utilisation de sklearn
pour normaliser vos données, vous devez importer le StandardScalar de la bibliothèque sklearn et l’appliquer à notre ensemble de données., Voici comment vous pouvez le faire:
Vous auriez remarqué que je n’ai appliqué la standardisation qu’à mes colonnes numériques et non aux autres fonctionnalités codées à chaud. Standardiser les entités codées à chaud signifierait affecter une distribution aux entités catégorielles. Vous ne voulez pas le faire!
Mais pourquoi n’ai-je pas fait la même chose en normalisant les données? Parce que les fonctionnalités codées à chaud sont déjà comprises entre 0 et 1. Ainsi, la normalisation n’affecterait pas leur valeur.,
à droite, voyons comment la normalisation a transformé nos données:
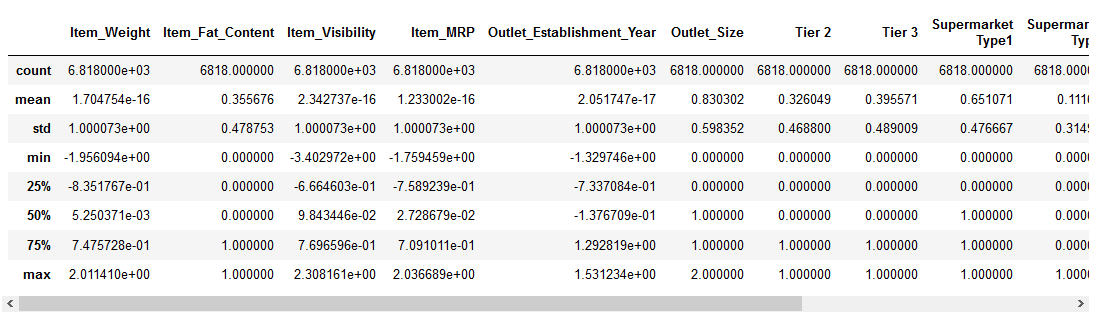
Les caractéristiques numériques sont maintenant centrées sur la moyenne avec un écart-type unitaire. Fantastique!
comparaison de données non mises à l’échelle, normalisées et normalisées
Il est toujours bon de visualiser vos données pour comprendre la distribution présente. Nous pouvons voir la comparaison entre nos données non mises à l’échelle et mises à l’échelle à l’aide de boxplots.
Vous pouvez en savoir plus sur la visualisation de données ici.,
Vous pouvez remarquer comment les fonctionnalités de mise à l’échelle apporte tout en perspective. Les fonctionnalités sont maintenant plus comparables et aura un effet similaire sur les modèles d’apprentissage.
l’Application de la mise à l’Échelle des Algorithmes d’Apprentissage automatique
Il est maintenant temps de former certains algorithmes d’apprentissage automatique sur nos données pour comparer les effets de différentes techniques de mise à l’échelle sur les performances de l’algorithme. Je veux voir l’effet de la mise à l’échelle sur trois algorithmes en particulier: K-voisins les plus proches, régresseur de vecteur de Support et Arbre de décision.,
K-voisins les plus proches
Comme nous l’avons vu auparavant, KNN est un algorithme basé sur la distance qui est affecté par la gamme de fonctionnalités. Voyons comment cela fonctionne sur nos données, avant et après la mise à l’échelle:
Vous pouvez voir que la mise à l’échelle des fonctionnalités a réduit le score RMSE de notre modèle KNN. Plus précisément, les données normalisées fonctionnent un peu mieux que les données normalisées.
remarque: je mesure le RMSE ici parce que ce concours évalue le RMSE.
Support Vector Regressor
SVR est un autre algorithme basé sur la distance., Voyons donc si cela fonctionne mieux avec la normalisation ou la normalisation:

Nous pouvons voir que la mise à l’échelle des fonctionnalités fait baisser le score RMSE. Et les données normalisées ont obtenu de meilleurs résultats que les données normalisées. Pourquoi pensez vous que c’est le cas?
la documentation sklearn indique que SVM, avec le noyau RBF, suppose que toutes les entités sont centrées autour de zéro et que la variance est du même ordre. En effet, une caractéristique avec une variance supérieure à celle des autres empêche l’estimateur d’apprendre de toutes les caractéristiques., Très bien!
Arbre de décision
nous savons déjà qu’un arbre de décision est invariant à la mise à l’échelle des entités. Mais je voulais montrer un exemple pratique de la façon dont il fonctionne sur les données:

Vous pouvez voir que le score RMSE n’a pas bougé d’un pouce lors de la mise à l’échelle des fonctionnalités. Soyez donc assuré lorsque vous utilisez des algorithmes basés sur des arbres sur vos données!,
notes de fin
Ce tutoriel a couvert la pertinence de l’utilisation de la mise à l’échelle des fonctionnalités sur vos données et comment la normalisation et la normalisation ont des effets variables sur le fonctionnement des algorithmes d’apprentissage automatique
gardez à l’esprit qu’il n’y a pas de réponse correcte Tout dépend de vos données et l’algorithme que vous utilisez.
comme prochaine étape, je vous encourage à essayer la mise à l’échelle des fonctionnalités avec d’autres algorithmes et à déterminer ce qui fonctionne le mieux – la normalisation ou la normalisation?, Je vous recommande d’utiliser les données de Vente BigMart à cette fin pour maintenir la continuité avec cet article. Et n’oubliez pas de partager vos idées dans la section commentaires ci-dessous!
Vous pouvez également lire cet article sur notre APPLICATION Mobile