Une méthode d’échantillonnage probabiliste est toute la méthode d’échantillonnage qui utilise une certaine forme de sélection aléatoire. Afin d’avoir une méthode de sélection aléatoire, vous devez mettre en place un processus ou une procédure qui garantit que les différentes unités de votre population ont des probabilités égales d’être choisies. Les humains ont longtemps pratiqué diverses formes de sélection aléatoire, comme choisir un nom dans un chapeau ou choisir la paille courte. De nos jours, nous avons tendance à utiliser les ordinateurs comme mécanisme de génération de nombres aléatoires comme base de sélection aléatoire.,
quelques définitions
avant de pouvoir expliquer les différentes méthodes de probabilité, nous devons définir quelques termes de base. Ce sont:
-
Nle nombre de cas dans le cadre d’échantillonnage -
nle nombre de cas dans l’exemple -
NCn= le nombre de combinaisons (sous-ensembles) denà partir deN -
f = n/Nest la fraction d’échantillonnage
c’est tout., Avec les termes définis, nous pouvons commencer à définir les différentes méthodes d’échantillonnage probabiliste.
l’Échantillonnage Aléatoire Simple
la forme La plus simple de l’échantillonnage aléatoire est appelé l’échantillonnage aléatoire simple. Assez délicat, hein? Voici la description rapide de l’échantillonnage aléatoire simple:
- Objectif: sélectionner
nunités deNde telle sorte que chaqueNCna une chance égale d’être sélectionné. - Procédure: Utiliser une table de nombres aléatoires, un ordinateur générateur de nombre aléatoire, ou un dispositif mécanique pour sélectionner l’échantillon.,
Une définition quelque peu échasse, si elle est exacte. Voyons si nous pouvons le rendre un peu plus réel.

Comment sélectionner un échantillon aléatoire simple? Supposons que nous faisons des recherches avec une petite agence de services qui souhaite évaluer les opinions des clients sur la qualité du service au cours de la dernière année. Premièrement, nous devons organiser la base d’échantillonnage. Pour ce faire, nous examinerons les dossiers de l’agence pour identifier chaque client au cours des 12 derniers mois. Si nous sommes chanceux, l’agence dispose de bons dossiers informatisés précis et peut rapidement produire une telle liste., Ensuite, nous devons réellement dessiner l’échantillon. Décidez du nombre de clients que vous souhaitez avoir dans l’échantillon final. Par exemple, supposons que vous souhaitiez sélectionner 100 clients à sonder et qu’il y ait eu 1 000 clients au cours des 12 derniers mois. Ensuite, la fraction d’échantillonnage est f = n/N = 100/1000 = .10 (ou 10%). Maintenant, pour dessiner réellement l’échantillon, vous avez plusieurs options. Vous pouvez imprimer la liste des 1000 clients, déchirer puis en bandes séparées, mettre les bandes dans un chapeau, les mélanger vraiment bien, fermer les yeux et retirer les 100 premiers., Mais cette procédure mécanique serait fastidieuse et la qualité de l’échantillon dépendrait de la façon dont vous les avez mélangés et comment vous avez atteint au hasard. Peut-être une meilleure procédure serait d’utiliser le genre de machine à billes qui est populaire avec la plupart des loteries d’état. Vous auriez besoin de trois jeux de boules numérotées de 0 à 9, un pour chacun des chiffres de 000 de 999 (si vous sélectionnez 000 nous appellerons que 1000)., Numérotez la liste des noms de 1 à 1000, puis utilisez la machine à billes pour sélectionner les trois chiffres qui sélectionnent chaque personne. L’inconvénient évident ici est que vous devez obtenir les machines à billes. (Où font-ils ces choses, de toute façon? Y a-t-il une industrie de machines à billes?).
aucune de ces procédures mécaniques n’est très réalisable et, avec le développement d’ordinateurs peu coûteux, il existe un moyen beaucoup plus facile. Voici une procédure simple qui est particulièrement utile si vous avez déjà les noms des clients sur l’ordinateur., De nombreux programmes informatiques peuvent générer une série de nombres aléatoires. Supposons que vous puissiez copier et coller la liste des noms de clients dans une colonne d’une feuille de calcul EXCEL. Ensuite, dans la colonne juste à côté, collez la fonction =RAND() qui est la façon D’EXCEL de mettre un nombre aléatoire entre 0 Et 1 dans les cellules. Ensuite, triez les deux colonnes de la liste des noms et le nombre aléatoire par les nombres aléatoires. Cela réorganise la liste dans un ordre aléatoire du nombre aléatoire le plus bas au nombre aléatoire le plus élevé., Ensuite, tout ce que vous avez à faire est de prendre les cent premiers noms de cette liste triée. assez simple. Vous pourriez probablement accomplir le tout en moins d’une minute.
l’échantillonnage aléatoire Simple est simple à réaliser et est facile à expliquer aux autres. Parce que l’échantillonnage aléatoire simple est juste de manière à sélectionner un échantillon, il est raisonnable de généraliser les résultats de l’échantillon à la population. L’échantillonnage aléatoire Simple n’est pas la méthode d’échantillonnage la plus statistiquement efficace et vous pouvez, juste à cause de la chance du tirage au sort, ne pas obtenir une bonne représentation des sous-groupes dans une population., Pour faire face à ces problèmes, nous devons nous tourner vers d’autres méthodes d’échantillonnage.
échantillonnage aléatoire stratifié
L’échantillonnage aléatoire stratifié, aussi parfois appelé échantillonnage aléatoire proportionnel ou contingentaire, consiste à diviser votre population en sous-groupes homogènes, puis à prélever un échantillon aléatoire simple dans chaque sous-groupe. En termes plus formels:
Il y a plusieurs raisons principales pour lesquelles vous pourriez préférer l’échantillonnage stratifié à l’échantillonnage aléatoire simple., Premièrement, il garantit que vous serez en mesure de représenter non seulement la population globale, mais aussi les sous-groupes clés de la population, en particulier les petits groupes minoritaires. Si vous voulez pouvoir parler de sous-groupes, c’est peut-être le seul moyen de vous assurer efficacement que vous serez en mesure de le faire. Si le sous-groupe est extrêmement petit, vous pouvez utiliser différentes fractions d’échantillonnage (f) dans les différentes strates pour échantillonner de manière aléatoire le petit groupe (bien que vous deviez ensuite pondérer les estimations intra-groupe en utilisant la fraction d’échantillonnage chaque fois que vous voulez des estimations globales de la population)., Lorsque nous utilisons la même fraction d’échantillonnage à l’intérieur des strates, nous effectuons un échantillonnage aléatoire stratifié proportionné. Lorsque nous utilisons différentes fractions d’échantillonnage dans les strates, nous appelons cet échantillonnage aléatoire stratifié disproportionné. Deuxièmement, l’échantillonnage aléatoire stratifié aura généralement plus de précision statistique que le simple échantillonnage aléatoire. Cela ne sera vrai que si les strates ou les groupes sont homogènes. Si c’est le cas, nous nous attendons à ce que la variabilité au sein des groupes soit inférieure à la variabilité pour l’ensemble de la population. L’échantillonnage stratifié capitalise sur ce fait.,
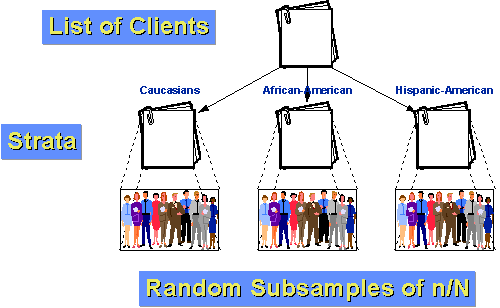
par exemple, disons que la population de clients de notre agence peut être divisée en trois groupes: Caucasien, Afro-Américain et hispano-américain. En outre, supposons que les Afro-Américains et les Hispano-Américains sont des minorités relativement petites de la clientèle (10% Et5% respectivement)., Si nous faisions juste un simple échantillon aléatoire de n=100 avec une fraction d’échantillonnage de 10%, nous nous attendrions par hasard à ce que nous n’obtenions que 10 et 5 personnes de chacun de nos deux petits groupes. Et, par hasard, nous pourrions obtenir moins que cela! Si nous stratifions, nous pouvons faire mieux. Tout d’abord, déterminons combien de personnes nous voulons avoir dans chaque groupe. Disons que nous voulons toujours de prendre un échantillon de 100 de la population de 1000 clients au cours de la dernière année. Mais nous pensons que, pour dire n’importe quoi sur les sous-groupes nous aurons besoin d’au moins 25 cas dans chaque groupe., Alors, échantillonnons 50 Caucasiens, 25 Afro-Américains et 25 Hispano-Américains. Nous savons que 10% de la population, soit 100 clients, sont Afro-Américains. Si nous échantillonnons au hasard 25 d’entre eux, nous avons une fraction d’échantillonnage à l’intérieur de la strate de 25/100 = 25%. De même, nous savons que 5% ou 50 clients sont Hispano-Américains. Ainsi, notre fraction d’échantillonnage à l’intérieur de la strate sera 25/50 = 50%. Enfin, par soustraction, nous savons qu’il y a 850 clients Caucasiens. Notre fraction d’échantillonnage à l’intérieur de la strate pour eux est 50/850 = about 5.88%., Étant donné que les groupes sont plus homogènes à l’intérieur d’un groupe que dans l’ensemble de la population, nous pouvons nous attendre à une plus grande précision statistique (moins de variance). Et, parce que nous avons stratifié, nous savons que nous aurons assez de cas de chaque groupe pour faire des inférences significatives sous-groupes.,e sont les étapes que vous devez suivre afin de parvenir à un échantillon aléatoire systématique:
- le nombre d’unités dans la population à partir de
1deN - décider sur le
n(taille de l’échantillon) que vous souhaitez ou avez besoin -
k = N/n= l’intervalle de la taille - choisir au hasard un nombre entier compris entre
1dek - ensuite, prendre tous les
kthunité

Tout cela sera beaucoup plus clair avec un exemple., Supposons que nous ayons une population qui ne compte que N=100 personnes et que vous souhaitiez prendre un échantillon de n = 20. Pour utiliser l’échantillonnage systématique, la population doit être énumérés dans un ordre aléatoire. La fraction d’échantillonnage serait f = 20/100 = 20%. dans ce cas, la dimension de l’intervalle, k est égal à N/n = 100/20 = 5. Maintenant, sélectionnez un entier aléatoire dans 1 to 5. Dans notre exemple, imaginez que vous ayez choisi 4., Maintenant, pour sélectionner l’échantillon, commencez par l’unité4th dans la liste et prenez chaque uniték-th (tous les 5, car k=5). Vous échantillonneriez les unités 4, 9, 14, 19, etc. à 100 et vous vous retrouveriez avec 20 unités dans votre échantillon.
pour que cela fonctionne, il est essentiel que les unités de la population soient ordonnées de manière aléatoire, du moins en ce qui concerne les caractéristiques que vous mesurez. Pourquoi voudriez-vous jamais utiliser l’échantillonnage aléatoire systématique? Pour une chose, il est assez facile à faire. Il vous suffit de sélectionner un seul nombre aléatoire pour commencer les choses., Il peut également être plus précis que le simple échantillonnage aléatoire. Enfin, dans certaines situations, il n’existe tout simplement pas de moyen plus simple de procéder à un échantillonnage aléatoire. Par exemple, une fois, j’ai dû faire une étude de l’échantillonnage de tous les livres dans une bibliothèque. Une fois sélectionné, je devrais aller sur l’étagère, localiser le livre et enregistrer la dernière fois qu’il a circulé. Je savais que j’avais une assez bonne base d’échantillonnage sous la forme de la liste des étagères (qui est un catalogue de cartes où les entrées sont disposées dans l’ordre dans lequel elles se produisent sur l’étagère)., Pour faire un simple échantillon aléatoire, j’aurais pu estimer le nombre total de livres et générer des nombres aléatoires pour dessiner l’échantillon; mais comment trouver facilement le livre #74,329 si c’est le nombre que j’ai sélectionné? Je ne pouvais pas très bien compter les cartes jusqu’à ce que je suis arrivé à 74,329! Stratifier ne résoudrait pas ce problème non plus. Par exemple, j’aurais pu stratifier par tiroir de catalogue de cartes et dessiner un échantillon aléatoire simple dans chaque tiroir. Mais je serais toujours coincé à compter les cartes. Au lieu de cela, j’ai fait un échantillon aléatoire systématique. J’ai estimé le nombre de livres dans toute la collection. Imaginons que c’était 100 000., J’ai décidé que je voulais prendre un échantillon de 1000 pour une fraction de sondage de 1000/100,000 = 1%. Pour obtenir l’intervalle d’échantillonnage k, j’ai divisé N/n = 100,000/1000 = 100. Puis j’ai sélectionné un nombre entier aléatoire entre 1 et 100. Disons que j’ai 57.
ensuite, j’ai fait une petite étude latérale pour déterminer l’épaisseur d’un millier de cartes dans le catalogue de cartes (en tenant compte des âges variables des cartes)., Disons qu’en moyenne, j’ai trouvé que deux cartes séparées par 100 étaient séparées d’environ .75 pouces dans le tiroir du catalogue. Cette information m’a donné tout ce dont j’avais besoin pour dessiner l’échantillon. J’ai compté jusqu’au 57e à la main et enregistré les informations du livre. Ensuite, j’ai pris une boussole. (Rappelez-vous ceux de votre classe de mathématiques du secondaire? Ce sont les drôles de petits instruments en métal avec une épingle pointue à une extrémité et un crayon à l’autre que vous avez utilisé pour dessiner des cercles en classe de géométrie.,) Ensuite, j’ai réglé la boussole à .75", collé l’extrémité de la broche à la 57e Carte et pointé avec l’extrémité du crayon vers la carte suivante (environ 100 livres). De cette façon, j’ai approximé la sélection des 157e, 257e, 357e, etc. J’ai pu accomplir toute la procédure de sélection en très peu de temps en utilisant cette approche d’échantillonnage aléatoire systématique. Je serais probablement toujours là à compter les cartes si j’avais essayé une autre méthode d’échantillonnage aléatoire. (D’accord, donc je n’ai pas de vie. J’ai été bien indemnisé, ça ne me dérange pas de dire, pour avoir mis au point ce schéma.,
échantillonnage aléatoire par grappes
le problème avec les méthodes d’échantillonnage aléatoire Lorsque nous devons échantillonner une population qui est décaissée dans une vaste région géographique est que vous devrez couvrir beaucoup de terrain géographiquement afin d’accéder à chacune des unités que vous avez échantillonnées. Imaginez prendre un échantillon aléatoire simple de tous les résidents de l’État de New York afin de mener des entretiens personnels. Par la chance du tirage au sort, vous vous retrouverez avec des répondants qui viennent de tout l’état. Vos intervieweurs vont avoir beaucoup de voyages à faire., C’est précisément pour ce problème que l’échantillonnage aléatoire par grappes ou zones a été inventé.
dans l’échantillonnage en grappes, nous procédons comme suit:
- diviser la population en grappes (généralement le long des frontières géographiques)
- échantillonner aléatoirement les grappes
- mesurer toutes les unités au sein des grappes échantillonnées
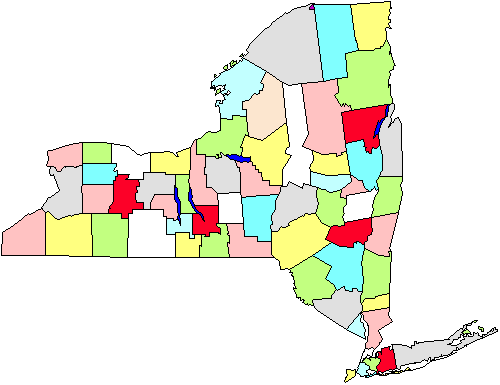
Par exemple, dans la figure, nous voyons une carte des comtés de L’État de New York. Disons que nous devons faire une enquête sur les gouvernements municipaux qui nous obligera à aller personnellement dans les villes., Si nous faisons un simple échantillon aléatoire à l’échelle de l’état, nous devrons couvrir l’ensemble de l’état géographiquement. Au lieu de cela, nous décidons de faire un échantillonnage en grappes de cinq comtés (marqués en rouge sur la figure). Une fois que ceux-ci sont sélectionnés, nous allons à chaque gouvernement de la ville dans les cinq zones. Il est clair que cette stratégie nous aidera à économiser sur notre Kilométrage. L’échantillonnage de grappes ou de zones est donc utile dans des situations comme celle-ci, et se fait principalement pour l’efficacité de l’administration., Notez également que nous n’avons probablement pas à nous soucier d’utiliser cette approche si nous menons un sondage par courrier ou par téléphone, car cela n’a pas autant d’importance (ou coûte plus cher ou augmente l’inefficacité) où nous appelons ou envoyons des lettres.
échantillonnage en plusieurs étapes
Les quatre méthodes que nous avons couvertes jusqu’à présent-simple, stratifiée, systématique et en grappes – sont les stratégies d’échantillonnage aléatoire les plus simples. Dans la plupart des recherches sociales appliquées réelles, nous utiliserions des méthodes d’échantillonnage qui sont considérablement plus complexes que ces variations simples., Le principe le plus important ici est que nous pouvons combiner les méthodes simples décrites précédemment de diverses manières utiles qui nous aident à répondre à nos besoins d’échantillonnage de la manière la plus efficace possible. Lorsque nous combinons des méthodes d’échantillonnage, nous appelons cet échantillonnage en plusieurs étapes.
par exemple, considérons l’idée d’échantillonner les résidents de L’État de New York pour des entretiens en face à face. Il est clair que nous voudrions faire un certain type d’échantillonnage en grappes comme première étape du processus. Nous pourrions échantillonner les cantons ou les secteurs de recensement dans tout l’état., Mais dans l’échantillonnage en grappes, nous mesurerions ensuite tout le monde dans les grappes que nous sélectionnons. Même si nous échantillonnons des secteurs de recensement, nous ne pourrons peut-être pas mesurer tous ceux qui se trouvent dans le secteur de recensement. Nous pourrions donc mettre en place un processus d’échantillonnage stratifié au sein des clusters. Dans ce cas, nous aurions un processus d’échantillonnage en deux étapes avec des échantillons stratifiés dans des échantillons de grappes. Ou, considérons le problème de l’échantillonnage des élèves dans les écoles. Nous pourrions commencer par un échantillon national de districts scolaires stratifiés par économie et niveau d’éducation., Dans certains districts, nous pourrions faire un simple échantillon aléatoire d’écoles. Dans les écoles, nous pourrions faire un simple échantillon aléatoire de classes ou de notes. Et, dans les classes, nous pourrions même faire un simple échantillon aléatoire d’étudiants. Dans ce cas, nous avons trois ou quatre étapes dans le processus d’échantillonnage, et nous utilisons à la fois stratifié et l’échantillonnage aléatoire simple. En combinant différentes méthodes d’échantillonnage, nous sommes en mesure d’obtenir une riche variété de méthodes d’échantillonnage probabiliste qui peuvent être utilisées dans un large éventail de contextes de recherche sociale.