, et sa mise en œuvre en Python
Dans ce blog, nous ‘vais essayer de creuser plus profondément dans la Forêt Aléatoire de la Taxonomie. Ici, nous allons en apprendre davantage sur l’apprentissage d’ensemble et essayer de l’implémenter en utilisant Python.,
Vous pouvez trouver le code ici.
c’est un algorithme d’apprentissage basé sur un arbre d’ensemble. Le classificateur de forêt aléatoire est un ensemble d’arbres de décision à partir d’un sous-ensemble d’ensemble d’entraînement sélectionné au hasard. Il agrège les votes de différents arbres de décision pour décider de la classe finale de l’objet de test.
algorithme D’Ensemble:
les algorithmes D’Ensemble sont ceux qui combinent plusieurs algorithmes de même type ou différents pour classer des objets. Par exemple, en exécutant la prédiction sur naïve Bayes, SVM et Arbre de décision, puis en votant pour la prise en compte finale de la classe pour l’objet de test.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., Les axes horizontaux et verticaux des sorties de l’arbre de décision ci-dessus peuvent être considérés comme des entités x1 et x2. Pour certaines valeurs de chaque fonction, l’arbre de décision sorties une classification de « bleu”, « vert”, « rouge”, etc.
Ces résultats ci-dessus sont agrégés, par le biais de votes de modèle ou d’une moyenne, en un seul
Modèle d’ensemble qui finit par surpasser la sortie de tout arbre de décision individuel.
Caractéristiques et avantages de la forêt aléatoire:
- c’est l’un des algorithmes d’apprentissage les plus précis disponibles. Pour de nombreux ensembles de données, il produit un classificateur très précis.,
- Il fonctionne efficacement sur de grandes bases de données.
- Il peut gérer des milliers de variables d’entrée sans suppression de variable.
- Il donne des estimations des variables qui sont importantes dans la classification.
- Il génère une estimation interne impartiale de l’erreur de généralisation à mesure que le bâtiment forestier progresse.
- C’est une méthode efficace pour estimer les données manquantes et maintient l’exactitude lorsqu’une grande proportion de données manquantes.,
inconvénients de la forêt aléatoire:
- on a observé que les forêts aléatoires s’adaptaient trop à certains ensembles de données avec des tâches de classification / régression bruyantes.
- Pour les données comprenant des variables catégorielles avec un nombre différent de niveaux, les forêts aléatoires sont biaisées en faveur des attributs avec plus de niveaux. Par conséquent, les scores d’importance variable de la forêt aléatoire ne sont pas fiables pour ce type de données.,div>
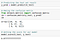
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Nous avons examiné l’algorithme d’apprentissage ensemblé en action et essayé de comprendre ce qui rend la forêt aléatoire différente des autres algorithmes d’apprentissage automatique.