Combien de gènes dans un génome?
Mode Lecteur
nous avons déjà examiné la grande diversité des tailles des génomes dans le monde vivant (voir le tableau dans la vignette « Quelle est la taille des génomes?”). Comme première étape pour affiner notre compréhension du contenu informationnel de ces génomes, nous avons besoin d’une idée du nombre de gènes qu’ils abritent. Lorsque nous nous référons aux gènes, nous penserons à des gènes codant des protéines excluant la collection sans cesse croissante de régions codant L’ARN dans les génomes.,
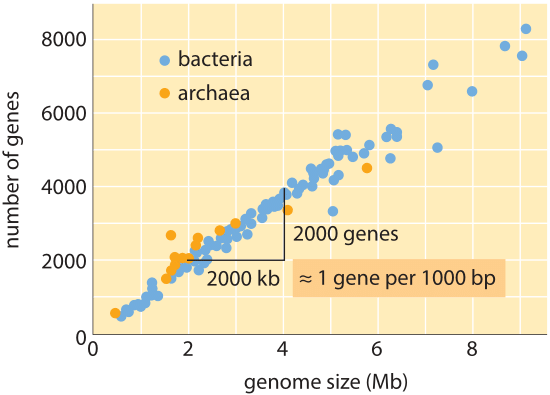
Figure 1: Nombre de gènes en fonction de la taille du génome. La figure montre des données pour une variété de bactéries et d’archées, la pente de la ligne de données confirmant la règle simple relative à la taille du génome et au nombre de gènes. (Adapté de M. Lynch, les Origines de L’Architecture du Génome.,)
sur l’ensemble de l’arbre de vie, bien que les tailles du génome diffèrent jusqu’à 8 ordres de grandeur (de <2 kb pour le virus de L’hépatite D (BNID 105570) à >100 Gbp pour le lungfish marbré (BNID 100597) et 102726)), la gamme dans le nombre de gènes varie de moins de 5 ordres de grandeur (de virus comme MS2 et QB bactériophages ayant seulement 4 gènes à environ cent mille dans le blé). De nombreuses bactéries ont plusieurs milliers de gènes., Cette teneur en gènes est proportionnelle à la taille du génome et à la taille des protéines, comme indiqué ci-dessous. Fait intéressant, les génomes eucaryotes, qui sont souvent mille fois ou plus grands que ceux des procaryotes, contiennent seulement un ordre de grandeur plus de gènes que leurs homologues procaryotes. L’incapacité d’estimer avec succès le nombre de gènes chez les eucaryotes sur la base de la connaissance du contenu génétique des procaryotes était l’un des rebondissements inattendus de la biologie moderne.,
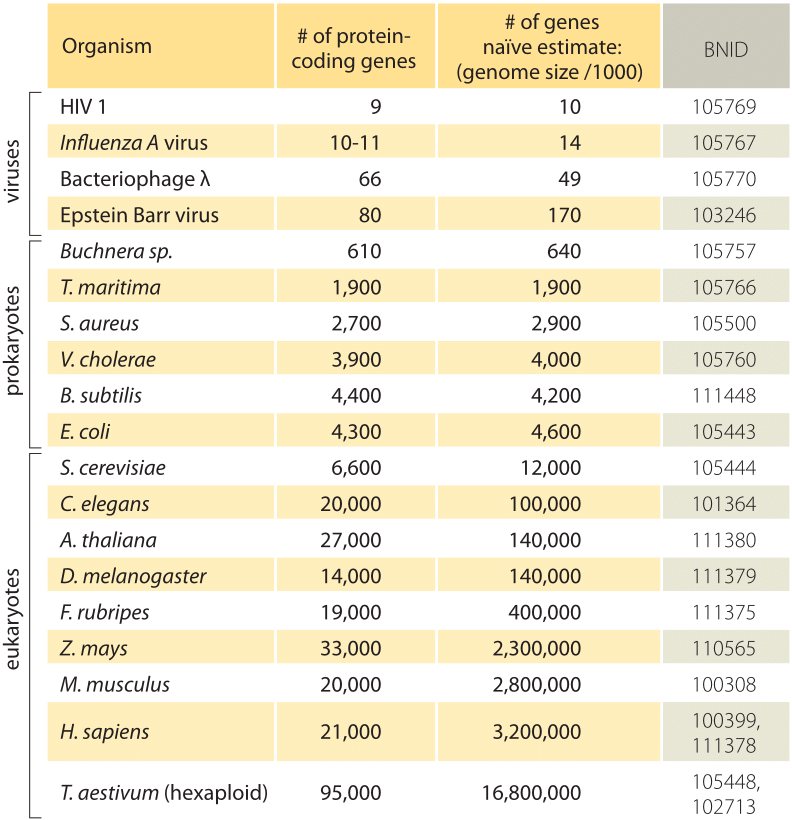
Tableau 1: une comparaison entre le nombre de gènes dans un organisme et une estimation naïve basée sur la taille du génome divisée par un facteur constant de 1000bp/gène, c’est-à-dire le nombre prédit de gènes = Taille du génome / 1000. On constate que cette règle empirique brute fonctionne étonnamment bien pour de nombreuses bactéries et archées, mais échoue lamentablement pour les organismes multicellulaires.
l’estimation la plus simple du nombre de gènes dans un génome se déroule en supposant que l’ensemble du génome code pour les gènes d’intérêt., Pour faire de nouveaux progrès avec l’estimation, Nous devons avoir une mesure du nombre d’acides aminés dans une protéine typique que nous prendrons à environ 300, conscient cependant du fait que comme les génomes, les protéines viennent dans une grande variété de tailles elles-mêmes comme est révélé dans la vignette sur ce sujet, ”quelles sont les tailles des protéines?”. Sur la base de cette Maigre hypothèse, nous voyons que le nombre de bases nécessaires pour coder notre protéine typique est d’environ 1000 (3 paires de bases par acide aminé)., Par conséquent, dans cet état d’esprit, le nombre de gènes contenus dans un génome est estimé à la taille du génome/1000. Pour les génomes bactériens, cette stratégie fonctionne étonnamment bien comme on peut le voir dans le tableau 1 et la Figure 1. Par exemple, lorsqu’elle est appliquée à L’E. coli K-12, génome de 4,6 x 106 PB, cette règle empirique conduit à une estimation de 4600 gènes, ce qui peut être comparé à la meilleure connaissance actuelle de cette quantité qui est de 4225. En parcourant une douzaine de bactéries représentatives et de génomes archéaux dans le tableau, on observe un pouvoir prédictif tout aussi frappant à environ 10%., D’autre part, cette stratégie échoue spectaculairement lorsque nous l’appliquons aux génomes eucaryotes, ce qui aboutit par exemple à l’estimation que le nombre de gènes dans le génome humain devrait être de 3 000 000, une surestimation brute. Le manque de fiabilité de cette estimation aide à expliquer l’existence du pool de Paris Genesweep qui, dès le début des années 2000, avait des gens pariant sur le nombre de gènes dans le génome humain, les estimations des gens variant de plus d’un facteur dix.,
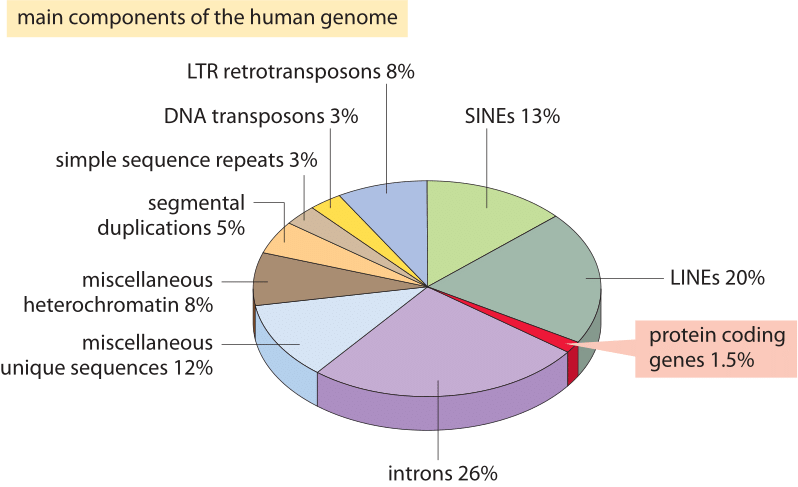
Figure 2: Les différents séquence d’éléments qui composent le génome humain. Environ 1,5% du génome est constitué des ≈20 000 séquences codantes de protéines qui sont entrecoupées par les introns non codants, ce qui représente environ 26%. Les éléments transposables sont la fraction la plus importante (40-50%) comprenant par exemple des éléments nucléaires intercalés longs (lignes) et des éléments nucléaires intercalés courts (SINEs). La plupart des éléments transposables sont des restes génomiques, qui sont actuellement disparus. (BNID 110283, adapté de T. R. Gregory Nat Rev Genet., 9: 699-708, 2005 basé sur International Human Genome Sequencing Consortium. Séquençage Initial et analyse du génome humain. Nature 409: 860 2001.)
Qu’est-ce qui explique cet échec spectaculaire de l’estimation la plus naïve et que nous apprend-il sur l’information organisée dans les génomes? Les génomes eucaryotes, en particulier ceux associés aux organismes multicellulaires, sont caractérisés par une foule de caractéristiques intrigantes qui perturbent l’image de codage simple exploitée dans l’estimation naïve., Ces différences dans l’utilisation du génome sont illustrées dans la Figure 2 qui montre le pourcentage du génome utilisé à d’autres fins que le codage des protéines. Comme le montre la Figure 1, les procaryotes peuvent compacter efficacement leurs séquences codantes de protéines de telle sorte qu’elles sont presque continues et que moins de 10% de leurs génomes sont assignés à de l’ADN non codant (12% chez E. coli, BNID 105750) alors que chez l’homme, plus de 98% (BNID 103748) est non codant.,
la découverte de ces autres utilisations du génome constitue quelques-unes des informations les plus importantes sur L’ADN, et la biologie plus généralement, des 60 dernières années. Une de ces utilisations alternatives pour l’immobilier génomique est le génome régulateur, à savoir, la façon dont de grands morceaux du génome sont utilisés comme cibles pour la liaison des protéines régulatrices qui donnent lieu au contrôle combinatoire si typique des génomes dans les organismes multicellulaires., Une autre des principales caractéristiques des génomes eucaryotes est l’organisation de leurs gènes en introns et exons, les exons exprimés étant beaucoup plus petits que les introns intermédiaires et épissés. Au-delà de ces caractéristiques, il y a des rétrovirus endogènes, reliques fossiles d’anciennes infections virales et étonnamment, plus de 50% du génome est occupé par l’existence d’éléments répétitifs et de transposons, dont diverses formes peuvent peut-être être interprétées comme des gènes égoïstes qui ont des mécanismes pour proliférer dans un génome hôte., Certains de ces éléments répétitifs et transposons sont encore actifs aujourd’hui alors que d’autres sont restés une relique après avoir perdu la capacité de proliférer davantage dans le génome.
En conclusion, les génomes peuvent être divisés en deux classes principales: compact et expansif. Les premiers sont denses en gènes, avec seulement environ 10% de région non codante et une proportionnalité stricte entre la taille du génome et le nombre de génomes. Ce groupe s’étend aux génomes de taille allant jusqu’à environ 10 Mbp, couvrant les virus, les bactéries, les archées et certains eucaryotes unicellulaires., Cette dernière classe ne montre pas de corrélation claire entre la taille du génome et le nombre de gènes, est composée principalement d’éléments non codants et couvre tous les organismes multicellulaires.




