Introduction
trier les données signifie les organiser dans un certain ordre, souvent dans une structure de données de type tableau. Vous pouvez utiliser différents critères de commande, les plus courants étant le tri des nombres du moins au plus grand ou vice versa, ou le tri lexicographique des chaînes. Vous pouvez même définir vos propres critères, et nous irons dans les moyens pratiques de le faire à la fin de cet article.,
Si vous êtes intéressé par le fonctionnement du tri, nous couvrirons divers algorithmes, des solutions inefficaces mais intuitives aux algorithmes efficaces qui sont réellement implémentés en Java et dans d’autres langages.
Il existe différents algorithmes de tri, et ils ne sont pas tous aussi efficaces. Nous analyserons leur complexité temporelle afin de les comparer et de voir lesquels fonctionnent le mieux.,
la liste des algorithmes que vous apprendrez ici n’est en aucun cas exhaustive, mais nous avons compilé certains des algorithmes les plus courants et les plus efficaces pour vous aider à démarrer:
- Bubble Sort
- insertion Sort
- Selection Sort
- Merge Sort
- Heapsort
- Quicksort
- tri en Java
Remarque: Cet article ne faites face au tri simultané, car il est destiné aux débutants.
Tri à Bulles
Explication
tri à Bulles fonctionne en permutant les éléments adjacents s’ils ne sont pas dans l’ordre souhaité., Ce processus se répète depuis le début du tableau jusqu’à ce que tous les éléments soient en ordre.
nous savons que tous les éléments sont en ordre lorsque nous parvenons à faire toute l’itération sans échanger du tout – alors tous les éléments que nous avons comparés étaient dans l’ordre souhaité avec leurs éléments adjacents, et par extension, tout le tableau.
Voici les étapes pour trier un tableau de nombres du moins au plus grand:
-
4 2 1 5 3: les deux premiers éléments sont dans le mauvais ordre, nous les échangeons donc.
-
2 4 1 5 3: Les deux éléments sont dans le mauvais ordre, donc nous avons swap.,
-
2 1 4 5 3: Ces deux sont dans le bon ordre, 4 < 5, afin de nous laisser seuls.
-
2 1 4 5 3: Un autre échange.
-
2 1 4 3 5: Voici le tableau résultant après une itération.
étant donné qu’au moins un échange s’est produit lors du premier passage (il y en avait en fait trois), nous devons parcourir à nouveau tout le tableau et répéter le même processus.
en répétant ce processus, jusqu’à ce qu’il n’y ait plus d’échanges, nous aurons un tableau trié.,
la raison pour laquelle cet algorithme est appelé Tri À Bulles est parce que les nombres sont en quelque sorte « bulle » à la « surface. »Si vous parcourez à nouveau notre exemple, en suivant un nombre particulier (4 est un excellent exemple), vous le verrez se déplacer lentement vers la droite pendant le processus.
Tous les nombres se déplacent à leur place respective petit à petit, de gauche à droite, comme des bulles s’élevant lentement d’un plan d’eau.
Si vous souhaitez lire un article détaillé dédié au tri des bulles, Nous sommes là pour vous!,
implémentation
Nous allons implémenter le tri des bulles de la même manière que nous l’avons présenté avec des mots. Notre fonction entre dans une boucle while dans laquelle elle traverse l’ensemble du tableau en échangeant au besoin.
nous supposons que le tableau est trié, mais si nous nous trompons lors du tri (si un échange se produit), nous passons par une autre itération. La boucle while continue ensuite jusqu’à ce que nous parvenions à traverser tout le tableau sans échanger:
lorsque nous utilisons cet algorithme, nous devons faire attention à la façon dont nous énonçons notre condition d’échange.,
par exemple, si j’avais utilisé a >= ail aurait pu se retrouver avec une boucle infinie, car pour des éléments égaux, cette relation serait toujours true, et donc toujours les échanger.
complexité temporelle
Pour comprendre la complexité temporelle du tri à bulles, nous devons examiner le pire scénario possible. Quel est le nombre maximum de fois que nous devons passer à travers l’ensemble du tableau avant de l’avoir trié?, Considérons l’exemple suivant:
5 4 3 2 1Dans la première itération, 5 « bulle à la surface », mais le reste des éléments rester dans l’ordre décroissant. Nous devrions faire une itération pour chaque élément sauf 1, puis une autre itération pour vérifier que tout est en ordre, donc un total de 5 itérations.
Développez ce à n’importe quel tableau de n éléments, et cela signifie que vous devez faire: n itérations., En regardant le code, cela voudrait dire que notre while boucle peut exécuter le maximum de n fois.
chacune de cesn fois que nous parcourons tout le tableau (for-loop dans le code), ce qui signifie que la pire complexité temporelle serait O(n^2).
Remarque: La complexité temporelle serait toujours O(n^2) s’il n’y avait pas la vérification booléennesorted, qui termine l’algorithme s’il n’y a pas d’échange dans la boucle interne – ce qui signifie que le tableau est trié.,
Tri par Insertion
explication
l’idée derrière le tri par Insertion est de diviser le tableau en sous-rangées triées et non triées.
la partie triée est de longueur 1 au début et correspond au premier élément (le plus à gauche) du tableau. Nous parcourons le tableau et à chaque itération, nous développons la partie triée du tableau d’un élément.
lors de l’expansion, nous plaçons le nouvel élément à sa place dans le sous-tableau trié. Nous le faisons en déplaçant tous les éléments vers la droite jusqu’à ce que nous rencontrions le premier élément que nous n’avons pas à déplacer.,
par exemple, si dans le tableau suivant, la partie en gras est triée dans un ordre croissant, ce qui suit se produit:
-
3 5 7 8 4 2 1 9 6: nous prenons 4 et nous rappelons que c’est ce que nous devons insérer. Depuis 8 > 4, nous décalons.
-
3 5 7 x 8 2 1 9 6: où la valeur de x n’a pas d’importance cruciale, car elle sera écrasée immédiatement (soit par 4 si c’est sa place appropriée, soit par 7 Si nous décalons). Depuis 7 > 4, nous décalons.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Après ce processus, le tri partie a été étendue par un élément, nous avons maintenant cinq au lieu de quatre éléments. Chaque itération le fait et à la fin, nous aurons tout le tableau trié.
Si vous souhaitez lire un article détaillé dédié au tri par Insertion, nous sommes là pour vous!,
implémentation
complexité temporelle
encore une fois, nous devons regarder le pire scénario pour notre algorithme, et ce sera à nouveau l’exemple où tout le tableau est descendant.
en effet, à chaque itération, nous devrons déplacer toute la liste triée par un, qui est O(n). Nous devons le faire pour chaque élément de chaque tableau, ce qui signifie qu’il va être limité par O(n^2).
selection Sort
explication
Selection Sort divise également le tableau en un sous-tableau trié et non trié., Bien que, cette fois, le tri subarray est formé par l’insertion de l’élément minimum de la non triés subarray à la fin du tableau trié, par le remplacement:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Mise
À chaque itération, nous supposons que le premier élément non trié est le minimum et parcourir le reste à voir si il y a un plus petit élément.,
Une fois que nous trouvons le minimum actuel de la partie non triée du tableau, nous l’échangeons avec le premier élément et le considérons comme une partie du tableau trié:
complexité temporelle
trouver le minimum est O(n) pour la longueur du tableau car nous devons vérifier tous les éléments. Nous devons trouver le minimum pour chaque élément du tableau, ce qui rend l’ensemble du processus limité par O(n^2).,
Merge Sort
explication
Merge Sort utilise la récursivité pour résoudre le problème du tri plus efficacement que les algorithmes précédemment présentés, et en particulier il utilise une approche de diviser pour régner.
en utilisant ces deux concepts, nous allons diviser l’ensemble du tableau en deux sous-réseaux, puis:
- trier la moitié gauche du tableau (récursivement)
- trier la moitié droite du tableau (récursivement)
- fusionner les solutions
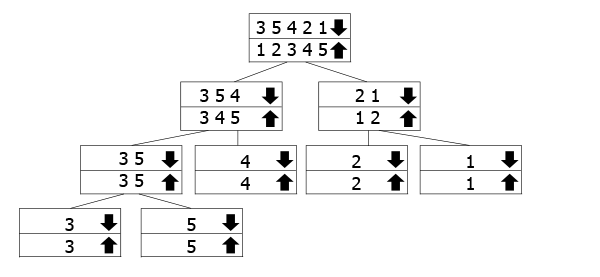
Cet arbre est censé représenter comment fonctionnent les appels récursifs., Les tableaux Marqués de la flèche vers le bas sont ceux pour lesquels nous appelons la fonction, tandis que nous fusionnons ceux de la flèche vers le haut. Vous suivez donc la flèche vers le bas jusqu’au bas de l’arbre, puis remontez et fusionnez.
Dans notre exemple, nous avons le tableau 3 5 3 2 1, afin de nous diviser en 3 5 4 et 2 1. Pour les trier, nous les divisons davantage en leurs composants. Une fois que nous avons atteint le fond, nous commençons à fusionner et à les trier au fur et à mesure.,
Si vous souhaitez lire un article détaillé dédié au tri par Fusion, nous sommes là pour vous!
implémentation
la fonction de base fonctionne à peu près comme indiqué dans l’explication. Nous passons simplement des index left Et right qui sont des index de l’élément le plus à gauche et le plus à droite du sous-réseau que nous voulons trier. Initialement, ceux-ci devraient être 0 Et array.length-1, en fonction de l’implémentation.,
La base de notre récursivité garantit que nous quittons lorsque nous avons terminé, ou lorsquerightEtleft se rencontrent. Nous trouvons un point médian mid, et trions les sous-réseaux à gauche et à droite de celui-ci récursivement, fusionnant finalement nos solutions.
Si vous vous souvenez de notre graphique d’arborescence, vous vous demandez peut-être pourquoi ne pas créer deux nouveaux tableaux plus petits et les transmettre à la place. En effet, sur les tableaux très longs, cela entraînerait une consommation de mémoire énorme pour quelque chose qui est essentiellement inutile.,
Le tri de fusion ne fonctionne déjà pas sur place à cause de l’étape de fusion, et cela ne ferait qu’aggraver son efficacité de mémoire. La logique de notre arbre de récursivité reste la même, cependant, nous devons simplement suivre les index que nous utilisons:
pour fusionner les sous-réseaux triés en un seul, nous devrons calculer la longueur de chacun et créer des tableaux temporaires pour les copier, afin que nous puissions changer librement notre tableau principal.
Après la copie, nous parcourons le tableau résultant et lui attribuons le minimum actuel., Parce que nos sous-réseaux sont triés, nous avons juste choisi le moindre des deux éléments qui n’ont pas été choisis jusqu’à présent, et déplacer l’itérateur pour ce sous-réseau vers l’avant:
complexité temporelle
Si nous voulons dériver la complexité des algorithmes récursifs, nous allons devoir obtenir un peu de mathy.
Le Master Theorem est utilisé pour comprendre la complexité temporelle des algorithmes récursifs. Pour les algorithmes Non récursifs, nous pourrions généralement écrire la complexité temporelle précise comme une sorte d’équation, puis nous utilisons la Notation Big-O pour les trier en classes d’algorithmes à comportement similaire.,
le problème avec les algorithmes récursifs est que cette même équation ressemblerait à ceci:
t(N) = at(\frac{n}{B}) + cn^K
l’équation elle-même est récursive! Dans cette équation, a nous dit combien de fois nous appelons récursivité, et b nous dit dans combien de parties de notre problème est divisée. Dans ce cas, cela peut sembler une distinction sans importance car ils sont égaux pour mergesort, mais pour certains problèmes, ils peuvent ne pas l’être.,
le reste de l’équation est la complexité de fusionner toutes ces solutions en une seule à la fin., Le théorème maître résout cette équation pour nous:
$ $
t(n) = \bigg\{
\begin{matrix}
O(N^{log_ba}), & a>b^k \\ o(n^klog n), & A = B^K \\ O(N^K), & a < B^K
\end{Matrix}
If
Si T(n) est l’exécution de l’algorithme lors du tri d’un tableau de la longueur n, le tri par fusion s’exécutera deux fois pour les tableaux qui ont la moitié de la longueur du tableau d’origine.,
Donc, si nous avons a=2, b=2. L’étape de fusion prend O (N) mémoire, donc k=1. Cela signifie que l’équation pour le tri par fusion serait la suivante:
$ $
t(n) = 2t(\frac{n}{2})+cn
Si nous appliquons le théorème principal, nous verrons que notre cas est celui où a=b^kparce que nous avons 2=2^1. Cela signifie que notre complexité est O (nlog n). C’est une complexité temporelle extrêmement bonne pour un algorithme de tri, car il a été prouvé qu’un tableau ne peut pas être trié plus rapidement que O(nlog n).,
bien que la version que nous avons présentée consomme de la mémoire, il existe des versions plus complexes du Tri par fusion qui ne prennent que de L’Espace O(1).
de plus, l’algorithme est extrêmement facile à paralléliser, car les appels récursifs d’un nœud peuvent être exécutés de manière complètement indépendante à partir de branches séparées. Bien que nous n’entrerons pas dans le comment et le pourquoi, car cela dépasse le cadre de cet article, il vaut la peine de garder à l’esprit les avantages de l’utilisation de cet algorithme particulier.,
Heapsort
Explication
Pour bien comprendre pourquoi Heapsort fonctionne, vous devez d’abord comprendre la structure, il est basé sur le tas. Nous parlerons spécifiquement d’un tas binaire, mais vous pouvez généraliser la plupart de cela à d’autres structures de tas.
Un tas est un arbre qui satisfait la propriété tas, qui est que, pour chaque nœud, tous ses enfants sont dans un rapport à elle. De plus, un tas doit être presque complet., Quasi complet de l’arbre binaire de profondeur d a un sous-arbre de profondeur d-1 avec la même racine, qui est complet, et dans lequel chaque nœud à gauche en descendant dispose d’un sous-arbre gauche. En d’autres termes, lors de l’ajout d’un nœud, nous choisissons toujours la position la plus à gauche dans le niveau incomplet le plus élevé.
Si le tas est un max-heap, alors tous les enfants sont plus petits que le parent, et s’il s’agit d’un Min-heap, Tous sont plus grands.,
en d’autres termes, lorsque vous descendez l’arbre, vous obtenez des nombres de plus en plus petits (min-tas) ou de plus en plus grands (max-tas). Voici un exemple de max-heap:
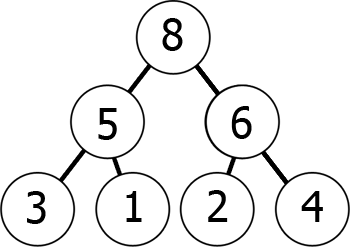
Nous pouvons représenter ce max-heap en mémoire comme un tableau de la manière suivante:
8 5 6 3 1 2 4 Vous pouvez l’envisager comme une lecture du graphique niveau par niveau, de gauche à droite., Ce que nous avons obtenu, c’est que si nous prenons l’élément kth dans le tableau, les positions de ses enfants sont 2*k+1 et 2*k+2 (en supposant que l’indexation commence à 0). Vous pouvez le vérifier par vous-même.
inversement, pour l’élément kth la position du parent est toujours (k-1)/2.
Sachant cela, vous pouvez facilement « max-heapify » tout tableau. Pour chaque élément, vérifiez si l’un de ses enfants est plus petit que lui., S’ils le sont, échangez l’un d’eux avec le parent et répétez récursivement cette étape avec le parent (car le nouvel élément grand peut toujours être plus grand que son autre enfant).
Les feuilles n’ont pas d’enfants, elles sont donc trivialement des tas maximum:
-
6 1 8 3 5 2 4: Les deux enfants sont plus petits que le parent, donc tout reste le même.
-
6 1 8 3 5 2 4: Parce que 5 > 1, on les échange. Nous heapify récursivement pour 5 Maintenant.
-
6 5 8 3 1 2 4: les Deux enfants sont plus petits, donc rien ne se passe.,
-
6 5 8 3 1 2 4: Parce que 8 > 6, on les échange.
-
8 5 6 3 1 2 4: nous avons le tas illustré ci-dessus!
une Fois que nous avons appris à heapify un tableau le reste est assez simple. Nous échangeons la racine du tas avec la fin du tableau et raccourcissons le tableau d’un.,
Nous heapify le raccourcissement de la matrice de nouveau, et répéter le processus:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: échangé
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: échangé
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: échangé
Et ainsi de suite, je suis sûr que vous pouvez voir le modèle émergent.
implémentation
complexité temporelle
lorsque nous regardons la fonctionheapify(), tout semble être fait dans O(1), mais il y a ensuite cet appel récursif embêtant.,
combien de fois cela sera-t-il appelé, dans le pire des cas? Eh bien, dans le pire des cas, il se propagera jusqu’au sommet du tas. Il le fera en sautant vers le parent de chaque nœud, donc autour de la position i/2. cela signifie qu’il fera au pire log n sauts avant d’atteindre le sommet, donc la complexité est O(log n).
parce queheapSort() est clairement O(n) en raison de for-loops itérant à travers tout le tableau, cela rendrait la complexité totale de Heapsort O(nlog n).,
Heapsort est un tri sur place, ce qui signifie qu’il prend O(1) d’espace supplémentaire, par opposition au tri par fusion, mais il présente également quelques inconvénients, tels que son caractère difficile à paralléliser.
Quicksort
explication
Quicksort est un autre algorithme de division et de conquête. Il choisit un élément d’un tableau comme pivot et trie tous les autres éléments qui l’entourent, par exemple des éléments plus petits à gauche et plus grands à droite.
Cela garantit que le pivot est à sa place après le processus., Ensuite, l’algorithme fait récursivement la même chose pour les parties gauche et droite du tableau.
implémentation
complexité temporelle
la complexité temporelle de Quicksort peut être exprimée avec l’équation suivante:
$ $
t(n) = t(k) + t(n-k-1) + O(N)
le pire scénario est lorsque le plus grand ou le plus petit élément est toujours choisi pour pivot. L’équation ressemblerait alors à ceci:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
Cela s’avère être O(n^2).,
cela peut sembler mauvais, car nous avons déjà appris plusieurs algorithmes qui s’exécutent en temps O(nlog n) Comme leur pire cas, mais Quicksort est en fait très largement utilisé.
en effet, il a un très bon temps d’exécution moyen, également limité par O(nlog n), et est très efficace pour une grande partie des entrées possibles.
l’une des raisons pour lesquelles il est préférable de fusionner le tri est qu’il ne prend pas d’espace supplémentaire, que tout le tri est effectué sur place et qu’il n’y a pas d’appels d’allocation et de désallocation coûteux.,
comparaison des performances
cela étant dit, il est souvent utile d’exécuter plusieurs fois tous ces algorithmes sur votre machine pour avoir une idée de leurs performances.
ils fonctionneront différemment avec différentes collections qui sont triées bien sûr, mais même dans cet esprit, vous devriez être en mesure de remarquer certaines tendances.
exécutons toutes les implémentations, une par une, chacune sur une copie d’un tableau mélangé de 10 000 entiers:
Nous pouvons évidemment voir que le tri par bulles est le pire en matière de performances., Évitez de l’utiliser en production si vous ne pouvez pas garantir qu’il ne gérera que de petites collections et qu’il ne bloquera pas l’application.
HeapSort et QuickSort sont les meilleurs en termes de performances. Bien qu’ils produisent des résultats similaires, QuickSort a tendance à être un peu mieux et plus cohérent – ce qui vérifie.
tri en Java
interface Comparable
Si vous avez vos propres types, cela peut devenir fastidieux d’implémenter un algorithme de tri séparé pour chacun. C’est pourquoi Java fournit une interface vous permettant d’utiliser Collections.sort() sur vos propres classes.,
Pour ce faire, votre classe doit implémenter l’ Comparable<T> interface T est votre type, et de remplacer une méthode appelée .compareTo().
cette méthode renvoie un entier négatif si this est plus petit que l’élément argument, 0 s’ils sont égaux, et un entier positif si this est plus grand.
dans notre exemple, nous avons créé une classe Student, et chaque étudiant est identifié par un id et une année où ils ont commencé leurs études.,
nous voulons les trier principalement par générations, mais aussi secondairement par id:
Et voici comment l’utiliser dans une application:
sortie:
interface de comparateur
Nous pourrions vouloir trier nos objets d’une manière peu orthodoxe pour un but spécifique, mais nous ne voulons pas classe, ou nous pourrions trier une collection d’un type intégré d’une manière non par défaut.
pour cela, nous pouvons utiliser l’interfaceComparator., Par exemple, prenons notre classe Student, et trions uniquement par ID:
Si nous remplaçons l’appel de tri dans main par ce qui suit:
Arrays.sort(a, new SortByID());Sortie:
comment tout cela fonctionne
Collection.sort() fonctionne en appelant la méthode Arrays.sort() sous-jacente, tandis que le tri lui-même utilise le tri par insertion pour les tableaux inférieurs à 47 et quicksort pour le reste.,
Il est basé sur une implémentation spécifique à deux pivots de Quicksort qui évite la plupart des causes typiques de dégradation en performances quadratiques, selon la documentation JDK10.
Conclusion
Le tri est une opération très courante avec les jeux de données, qu’il s’agisse de les analyser davantage, d’accélérer la recherche en utilisant des algorithmes plus efficaces qui s’appuient sur les données triées, de filtrer les données, etc.
Le tri est pris en charge par de nombreux langages et les interfaces obscurcissent souvent ce qui arrive réellement au programmeur., Bien que cette abstraction soit la bienvenue et nécessaire pour un travail efficace, elle peut parfois être mortelle pour l’efficacité, et il est bon de savoir comment implémenter divers algorithmes et connaître leurs avantages et inconvénients, ainsi que comment accéder facilement aux implémentations intégrées.