todennäköisyysnäytteenottomenetelmä on mikä tahansa näytteenottomenetelmä, jossa käytetään jonkinlaista satunnaisvalintaa. Jotta satunnaisessa menetelmä, sinun täytyy määrittää joitakin prosessi tai menettely, joka takaa, että eri yksiköiden oman väestöstä on yhtä suuri todennäköisyys tulla valituksi. Ihmiset ovat pitkään harjoiteltu eri muotoja satunnaisessa, kuten poiminta nimi hatusta, tai valita lyhyemmän korren. Nykyään meillä on tapana käyttää tietokoneita satunnaislukujen tuottamisen mekanismina satunnaisvalinnan pohjana.,
Jotkut Määritelmät
Ennen kuin voin selittää eri todennäköisyys menetelmiä, meidän täytyy määrittää joitakin perusehdot. Nämä ovat:
-
N– on useita tapauksia, joissa näytteenotto-kehys -
n– on useita tapauksia, joissa näyte -
NCn= yhdistelmien määrä (subsets) janalkaenN -
f = n/Non näytteenotto-osa
– se on siinä., Näillä termeillä voimme alkaa määritellä erilaisia todennäköisyysnäytteenottomenetelmiä.
yksinkertaista satunnaisotantaa
yksinkertaisin satunnaisotannan muoto on yksinkertainen satunnaisotanta. Aika hankalaa, vai mitä? Tässä on nopea kuvaus yksinkertainen satunnaisotanta:
- Tavoite: valitse
nyksiköt poisNsiten, että kukinNCnon yhtäläinen mahdollisuus tulla valituksi. - – menettely: käytä näytteen valitsemiseen taulukkoa satunnaislukuja, tietokoneen satunnaislukugeneraattoria tai mekaanista laitetta.,
hieman jäykät, jos tarkka määritelmä. Katsotaan, voimmeko tehdä siitä hieman aidomman.

Miten me valita yksinkertainen satunnaisotos? Oletetaan, että olemme tekemässä tutkimusta, jossa on pieni palvelu virasto, joka haluaa arvioida asiakkaiden näkemyksiä palvelun laatua kuluneen vuoden aikana. Ensin on järjestettävä näytteenottorunko. Tämän saavuttamiseksi, käymme läpi viraston tiedot tunnistaa jokaisen asiakkaan viimeisen 12 kuukauden aikana. Jos olemme onnekkaita, virastolla on hyvät tarkat tietokoneistetut tiedot ja se voi nopeasti tuottaa tällaisen listan., Sitten näyte pitää vetää. Päätä, kuinka monta asiakasta haluat lopulliseen otokseen. Esimerkkinä mainittakoon, että haluat valita tutkimukseen 100 asiakasta ja että asiakkaita oli 1000 viimeisen 12 kuukauden aikana. Sitten, näytteenotto-osa on f = n/N = 100/1000 = .10 (tai 10%). Nyt, todella vetää näyte, sinulla on useita vaihtoehtoja. Voit tulostaa luettelon 1000 asiakkaita, repiä sitten erillisiksi suikaleiksi, laita nauhat hattu, sekoita ne kunnolla, sulje silmäsi ja vedä ulos ensimmäinen 100., Mutta tämä mekaaninen menettely olisi työläs ja näytteen laatu riippuisi siitä, kuinka perusteellisesti sekoitit ne ja kuinka satunnaisesti olet saavuttanut. Ehkä parempi menettely olisi käyttää sellaista pallo kone, joka on suosittu monet valtion arpajaisia. Tarvitset kolme sarjaa palloja numeroitu 0-9, yksi sarja kutakin numerot 000 ja 999 (jos emme valitse 000 sanomme, että 1000)., Useita luettelon nimiä 1 ja 1000 ja sitten käyttää pallo kone, valitse kolme numeroa, jotka valitaan kunkin henkilön. Ilmeinen haitta tässä on, että sinun täytyy saada pallo koneita. (Missä niitä tehdään? Onko pallokoneteollisuutta?).
kumpikaan näistä mekaanisista menettelyistä ei ole kovin toteuttamiskelpoinen, ja edullisten tietokoneiden kehittämisen myötä on paljon helpompi tapa. Tässä on yksinkertainen menettely, joka on erityisen hyödyllinen, jos sinulla on asiakkaiden nimet jo tietokoneella., Monet tietokoneohjelmat voivat tuottaa sarjan satunnaislukuja. Oletetaan, että voit kopioida ja liittää luettelon asiakkaiden nimet sarakkeeseen EXCEL-taulukkolaskenta. Sitten, sarakkeessa sen vieressä liitä toiminto =RAND() joka on EXCEL on tapa ilmaista satunnainen numero 0 ja 1 soluissa. Lajittele sitten molemmat sarakkeet – nimilista ja satunnaisluku – satunnaislukujen mukaan. Tämä järjestää luettelon satunnaisjärjestyksessä alimmasta suurimpaan satunnaislukuun., Sitten sinun tarvitsee vain ottaa sata ensimmäistä nimeä tähän lajiteltuun luetteloon. aika yksinkertaista. Koko homma voisi onnistua alle minuutissa.
Yksinkertainen satunnaisotanta on yksinkertainen toteuttaa ja se on helppo selittää muille. Koska yksinkertainen satunnaisotanta on oikeudenmukainen tapa valita otos, on järkevää yleistää otoksen tulokset takaisin populaatioon. Yksinkertainen satunnaisotanta ei ole kaikkein tilastollisesti tehokas menetelmä näytteenotto-ja sinä voi, vain koska onni piirtää, ei saada hyvä edustus alaryhmiä väestön., Näiden ongelmien ratkaisemiseksi meidän on siirryttävä muihin näytteenottomenetelmiin.
Ositettu satunnaisotanta
Ositettu satunnaisotanta, myös joskus kutsutaan suhteellinen tai kiintiö satunnaisotanta, liittyy jakamalla perusjoukon homogeenisiin alaryhmiin, ja sitten ottaa yksinkertainen satunnaisotos kunkin alaryhmän. Muodollisemmin:
on useita merkittäviä syitä siihen, miksi voit mieluummin stratifioida näytteenoton kuin yksinkertaisen satunnaisotannan., Ensinnäkin, se vakuuttaa, että pystyt edustamaan paitsi koko väestön, mutta myös keskeisiä alaryhmiä, väestön, erityisesti pieniä vähemmistöryhmiä. Jos haluat pystyä puhumaan alaryhmiä, tämä voi olla ainoa tapa tehokkaasti vakuuttaa et ll pystyä. Jos alaryhmä on erittäin pieni, voit käyttää erilaisia näytteenotto-jakeet (f) sisällä eri kerrostumissa satunnaisesti yli-näyte pieni ryhmä (vaikka sinun sitten on paino sisällä-ryhmä arvioi, käyttäen näytteenotto-murto-kun haluat koko väestön arvioita)., Kun käytämme samaa näytteenottofraktiota ositteissa, suoritamme suhteellista ositettua satunnaisotantaa. Kun käytämme eri näytteenottojen jakeita ositteissa, kutsumme tätä suhteettoman ositettua satunnaisotantaa. Toiseksi ositetulla satunnaisotannalla on yleensä enemmän tilastollista tarkkuutta kuin yksinkertaisella satunnaisotannalla. Tämä pitää paikkansa vain, jos ositteet tai ryhmät ovat homogeenisia. Jos ne ovat, odotamme, että ryhmien sisäinen vaihtelu on vähäisempää kuin koko väestön vaihtelu. Ositettu näytteenotto hyödyntää tätä tosiasiaa.,
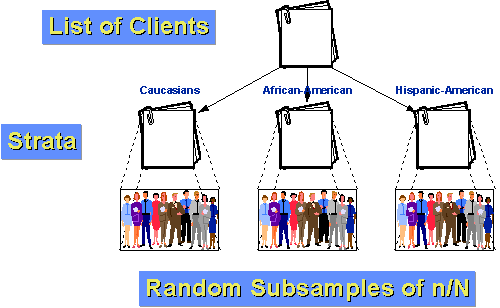
esimerkiksi, katsotaanpa sanoa, että väestö asiakkaita virasto voidaan jakaa kolmeen ryhmään: Valkoihoinen, Afrikkalainen Amerikan ja Hispanic-Amerikkalaiset. Lisäksi oletetaan, että sekä Afrikkalainen-Amerikkalaiset ja Latino-Amerikkalaiset ovat suhteellisen pieni vähemmistö asiakkaista (10% ja 5% vastaavasti)., Jos me vain teimme yksinkertainen satunnaisotos n=100 kanssa näytteenotto-osa 10%, odotamme sattumalta yksin, että me vain saada 10 ja 5 henkilöä kustakin meidän kaksi pienempää ryhmää. Ja sattumalta, voisimme saada vähemmän! Jos osaamme, pystymme parempaan. Ensin selvitetään, kuinka monta ihmistä haluamme olla jokaisessa ryhmässä. Oletetaan, että haluamme vielä ottaa 100 hengen otoksen 1000 asiakkaan joukosta viimeisen vuoden aikana. Mutta ajattelemme, että jotta voisimme sanoa mitään alaryhmistä, tarvitsemme vähintään 25 tapausta kussakin ryhmässä., Otetaan näyte 50 valkoihoisesta, 25 afroamerikkalaisesta ja 25 latinalaisamerikkalaisesta. Tiedämme, että 10 prosenttia väestöstä eli 100 asiakasta on afroamerikkalaisia. Jos satunnaisesti otamme näistä 25, meillä on sisällä stratum näytteenotto fraktio 25/100 = 25%. Samoin tiedämme, että 5% tai 50 asiakkaat ovat latinalaisamerikkalainen. Joten meidän sisällä-stratum näytteenotto fraktio on 25/50 = 50%. Vähennyslaskulla tiedämme, että valkoihoisia asiakkaita on 850. Our within-stratum sampling fraktio niille on 50/850 = about 5.88%., Koska ryhmät ovat yhtenäisempiä ryhmän sisällä kuin koko väestössä, voimme odottaa suurempaa tilastollista tarkkuutta (vähemmän varianssia). Ja, koska olemme ositettu, tiedämme, että meillä on tarpeeksi tapauksia jokaisesta ryhmästä tehdä mielekäs aliryhmä päätelmiä.,e ovat vaiheet sinun täytyy seurata, jotta voidaan saavuttaa systemaattinen satunnaisotos:
- numero yksiköiden väestöstä
1jaN - päätettävä
n(otoksen koko) että et halua tai tarvitse -
k = N/n= aikaväli koko - valitse satunnaisesti kokonaisluku välillä
1jak - sitten ottaa jokainen
kthyksikkö

Kaikki tämä on paljon selkeämpi esimerkki., Oletetaan, että meillä on populaatio, jossa on vain N=100 ihmistä ja että haluat ottaa näytteen n = 20. Systemaattisen näytteenoton käyttämiseksi populaatio on lueteltava satunnaisjärjestyksessä. Näytteenotto-osa olisi f = 20/100 = 20%. tässä tapauksessa, väli koko k, on yhtä kuin N/n = 100/20 = 5. Nyt, valitse satunnainen kokonaisluku 1 to 5. Kuvitelkaa esimerkissämme, että valitsitte 4., Nyt, valitse otos, aloittaa 4th yksikkö luettelosta ja ottaa jokainen k-th yksikkö (joka 5., koska k=5). Et olisi näytealojen 4, 9, 14, 19, ja niin edelleen 100 ja te päätteeksi 20 yksikköä näyte.
jotta tämä toimisi, on tärkeää, että yksiköiden väestöstä satunnaisesti tilattu, ainakin osalta ominaisuudet olet mittaus. Miksi haluaisit käyttää järjestelmällistä satunnaisotantaa? Ensinnäkin se on melko helppo tehdä. Sinun tarvitsee vain valita yksi satunnainen numero aloittaa asioita pois., Se voi olla myös tarkempi kuin yksinkertainen satunnaisotanta. Lopuksi, joissakin tilanteissa ei yksinkertaisesti ole helpompaa tapaa tehdä satunnaisotantaa. Jouduin esimerkiksi kerran tekemään tutkimuksen, jossa oli mukana näytteenotto kaikista kirjastossa olevista kirjoista. Kun minut oli valittu, minun piti mennä hyllylle, etsiä kirja ja tallentaa, milloin se viimeksi kiersi. Tiesin, että minun oli melko hyvän otannan muodossa hylly-luettelossa (joka on kortti luettelo, jossa merkinnät ovat järjestetty jotta he esiintyä hyllylle)., Tehdä yksinkertainen satunnaisotos, olisin voinut arvioitu kokonaismäärä kirjoja ja syntyy satunnaisia numeroita piirtää näyte; mutta miten löydän kirja #74,329 helposti, jos on numero on valittu? En osannut oikein laskea kortteja ennen kuin tulin 74 329: ään! Sitominen ei ratkaisisi sitäkään ongelmaa. Olisin voinut esimerkiksi stratifioida korttiluettelolaatikon mukaan ja piirtää yksinkertaisen satunnaisotoksen jokaiseen laatikkoon. En silti laskisi kortteja. Sen sijaan tein systemaattisen satunnaisotoksen. Arvioin koko kokoelman kirjojen määrän. Kuvitellaan, että se oli 100 000., Päätin, että haluan ottaa 1000 näytteen 1000/100,000 = 1%näytteenottojaksosta. Saada näytteenottoväli k, jaoin N/n = 100,000/1000 = 100. Sitten olen valinnut satunnainen kokonaisluku välillä 1 ja 100. Sanotaan, että sain 57.
Seuraavaksi tein pienen puolella tutkimus selvittää, kuinka paksu tuhat korttia on kortti catalog (ottaen huomioon eri-ikäistä kortit)., Sanotaan, että keskimäärin huomasin, että kaksi korttia, jotka olivat erotettu 100 kortit olivat noin .75 tuumaa toisistaan luettelo laatikko. Se tieto antoi minulle kaiken tarvittavan näytteen piirtämiseen. Laskin käsin 57: nneksi ja kirjasin ylös kirjan tiedot. Sitten otin kompassin. (Muistatko ne lukion matematiikan tunniltasi? Ne ovat hauskoja pieniä metallisoittimia, joiden toisessa päässä on terävä tappi ja toisessa kynä, jolla piirrät ympyröitä geometrian luokassa.,), Niin en aseta kompassi .75" juuttunut pin lopussa 57-kortti ja terävä kynä loppuun seuraava kortti (noin 100 kirjat pois). Näin approximated valitsemalla 157th, 257th, 357th, ja niin edelleen. Pystyin suorittamaan koko valintamenettelyn hyvin lyhyessä ajassa käyttämällä tätä järjestelmällistä satunnaisotantaa. Olisin varmaan vielä siellä laskemassa kortteja, jos olisin kokeillut toista satunnaisotantomenetelmää. Minulla ei ole elämää. Sain hyvän korvauksen siitä, että keksin tämän suunnitelman.,)
Klusterin (Alue) satunnaisotanta
ongelma sattumanvaraista otantaa, jolloin meidän on otos väestöstä, joka on maksettu laajalla maantieteellisellä alueella, on, että sinun täytyy kattaa paljon kentällä maantieteellisesti jotta saada kunkin yksiköitä otokseen. Kuvittele, että ottaisit yksinkertaisen satunnaisotoksen kaikista New Yorkin osavaltion asukkaista tehdäksesi henkilökohtaisia haastatteluja. Arvonnan tuurilla päädyt vastaajiin, jotka tulevat eri puolilta osavaltiota. Haastattelijoillanne on paljon matkustettavaa., Juuri tähän ongelmaan keksittiin klusterin tai alueen satunnaisotanta.
ryväsotanta, me seurata näitä ohjeita:
- jakaa väestön klustereihin (yleensä mukana maantieteelliset rajat)
- satunnaisesti näyte klustereissa
- mittaa kaikki yksiköt sisällä otokseen valittujen klustereiden
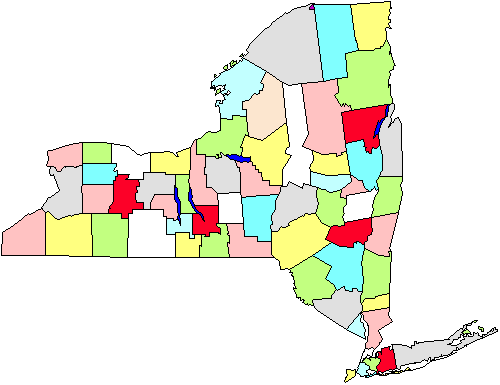
esimerkiksi kuvassa näemme kartta maakunnat New Yorkin osavaltiossa. Sanotaan, että meidän täytyy tehdä kysely kaupunginhallituksista, joka vaatii meitä menemään kaupunkeihin henkilökohtaisesti., Jos teemme yksinkertaisen satunnaisotoksen, meidän on katettava koko osavaltio maantieteellisesti. Sen sijaan päätämme tehdä klusterin näytteenotto viisi maakunnat (merkitty punaisella kuvassa). Kun nämä on valittu, menemme jokaiseen kaupunginhallitukseen viidellä alueella. On selvää, että tämä strategia auttaa meitä säästämään ajokilometreillä. Klusterin tai alueen näytteenotto on siis hyödyllistä tällaisissa tilanteissa, ja se tehdään ensisijaisesti hallinnon tehokkuuden vuoksi., Huomaa myös, että meidän ei luultavasti tarvitse huolehtia tämän lähestymistavan käyttämisestä, jos teemme posti-tai puhelintutkimusta, koska sillä ei ole niin paljon merkitystä (tai se maksaa enemmän tai lisää tehottomuutta), johon soitamme tai lähetämme kirjeitä.
monivaiheinen näytteenotto
tähän mennessä käsittelemämme neljä menetelmää-yksinkertainen, ositettu, järjestelmällinen ja klusteri – ovat yksinkertaisimpia satunnaisotantastrategioita. Useimmissa todellisissa soveltavissa yhteiskunnallisissa tutkimuksissa käyttäisimme otantamenetelmiä, jotka ovat huomattavasti monimutkaisempia kuin nämä yksinkertaiset vaihtelut., Tärkein periaate on, että voimme yhdistää yksinkertaisia menetelmiä aiemmin kuvattu useita hyödyllisiä tapoja, jotka auttavat meitä osoitteen otanta tarpeet mahdollisimman tehokkaalla ja tarkoituksenmukaisella tavalla mahdollista. Kun yhdistämme näytteenottomenetelmiä, kutsumme tätä monivaiheista näytteenottoa.
Ajatellaanpa esimerkiksi, että New Yorkin osavaltion asukkaita otettaisiin kasvokkaisiin haastatteluihin. Olisi selvää, että haluaisimme tehdä jonkinlaisen klusterinäytteen prosessin ensimmäisenä vaiheena. Saatamme ottaa mallia kaupunkilaisista tai väestönlaskennoista koko osavaltiossa., Mutta klusterinäytteiden otossa me sitten menisimme mittaamaan kaikki valitsemissamme klustereissa. Vaikka ottaisimme näytteitä, emme ehkä pysty mittaamaan kaikkia, jotka ovat väestönlaskennassa. Voisimme järjestää osittaisen näytteenoton klustereihin. Tällöin meillä olisi kaksivaiheinen näytteenottoprosessi, jossa olisi ositettu näyte klusterinäytteiden sisällä. Tai, harkitse ongelma näytteenotto oppilaita alakouluissa. Voisimme aloittaa kansallisesta otoksesta koulupiirejä, jotka on stratifioitu taloustieteen ja koulutustason mukaan., Valituissa kaupunginosissa voisimme tehdä yksinkertaisen satunnaisotoksen kouluista. Kouluissa saatamme tehdä yksinkertaisen satunnaisotoksen luokista tai arvosanoista. Ja tunneilla saatamme tehdä jopa yksinkertaisen satunnaisotoksen oppilaista. Tässä tapauksessa meillä on kolme tai neljä vaihetta näytteenottoprosessissa ja käytämme sekä ositettua että yksinkertaista satunnaisotantaa. Yhdistämällä eri näytteenottomenetelmiä voimme saavuttaa runsaasti erilaisia todennäköisyyspohjaisen näytteenotto menetelmiä, joita voidaan käyttää monenlaisia sosiaalisia tutkimus yhteyksissä.