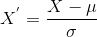Johdanto Ominaisuus Skaalaus
olin viime aikoina työskennellyt datajoukon, joka oli useita ominaisuuksia, jotka kattavat vaihtelevassa määrin suuruusluokkaa, alue ja yksiköt. Tämä on merkittävä este, sillä muutamat koneoppimisen algoritmit ovat erittäin herkkiä näille ominaisuuksille.
olen varma, että suurin osa teistä on kohdannut tämän asian projekteissaan tai oppimismatkallaan., Esimerkiksi yksi ominaisuus on kokonaan kilogrammoina, kun taas toinen on grammoina, toinen litroina ja niin edelleen. Miten voimme käyttää näitä ominaisuuksia, kun ne vaihtelevat niin paljon sen suhteen, mitä ne esittävät?
tässä Käännyin ominaisuuden skaalauksen käsitteeseen. Se on tärkeä osa tietojen esikäsittely vaiheessa, mutta olen nähnyt paljon aloittelijoille unohtaa sen (vahingoksi koneen oppimisen malli).,

Tässä on outoa skaalaus ominaisuus – se parantaa (merkittävästi) suorituskyky jotkut koneoppimisen algoritmeja ja ei toimi lainkaan muille. Mikä voisi olla syynä tähän omituisuuteen?
myös, mikä on ero normalisoinnin ja standardoinnin välillä? Nämä ovat kaksi yleisimmin käytettyä ominaisuus skaalaus tekniikoita koneoppiminen, mutta taso epäselvyyttä on olemassa niiden ymmärrystä. Milloin sinun pitäisi käyttää mitä tekniikkaa?,
vastaan näihin kysymyksiin ja lisää tässä artikkelissa ominaisuuden skaalauksesta. Olemme myös toteuttaa toiminto skaalaus Python antaa sinulle käytännön ymmärrystä siitä, miten se toimii eri koneoppimisen algoritmeja.
Huomautus: oletan, että olet perehtynyt Python-ja Core machine learning-algoritmeihin., Jos olet uusi tässä, suosittelen menossa läpi alla kurssit:
- Python Tietojen Tiede
- Kaikki vapaa Kone Oppimisen Kursseja, joita Analytics-Vidhya
- Applied Machine Learning
Sisällysluettelo
- Miksi meidän Pitäisi Käyttää Ominaisuus Skaalaus?
- mikä on normalisoituminen?
- mitä standardointi on?
- The Big Question-Normalize or Standardize?,
- Toteuttaminen Ominaisuus Skaalaus Python
- Normalisointi käyttäen Sklearn
- Standardisointi käyttämällä Sklearn
- Hakeminen Ominaisuus Skaalaus koneoppimisen Algoritmeja
- K-Nearest Neighbors (KNN)
- Tuki Vektori Regressor
- Päätös Puu
Miksi meidän Pitäisi Käyttää Ominaisuus Skaalaus?
ensimmäinen kysymys, jota meidän on käsiteltävä-miksi meidän on skaalattava muuttujia aineistossamme? Jotkut koneoppimisen algoritmit ovat herkkiä ominaisuus skaalaus, kun taas toiset ovat lähes invariant sitä., Selitän tämän tarkemmin.
gradientin laskeutumiseen perustuvat algoritmit
koneoppimisen algoritmit, kuten lineaarinen regressio, logistinen regressio, neuroverkko jne. gradientin laskeutuminen optimointitekniikkana edellyttää tietojen skaalaamista. Katso kaava kaltevuus laskeutuminen alla:

läsnäolo ominaisuus arvo X-kaava vaikuttaa vaihe koko kaltevuus laskeutuminen. Ero eri ominaisuuksia aiheuttaa eri askelkoot kunkin ominaisuuden., Varmistaa, että kaltevuus laskeutuminen liikkuu sujuvasti kohti minimit ja että vaiheet kaltevuus laskeutuminen on päivitetty samaan tahtiin kaikki ominaisuudet, meidän mittakaavassa tiedot ennen syöttämällä se malli.
Ottaa ominaisuuksia samanlainen asteikko voi auttaa kaltevuus laskeutuminen lähentyä nopeammin kohti minimit.
Matka-Pohjaisia Algoritmeja
Etäisyys algoritmeja, kuten KNN, K-means, ja SVM vaikuttaa eniten erilaisia ominaisuuksia., Tämä johtuu siitä, että kulissien takana he käyttävät datapisteiden välisiä etäisyyksiä määrittääkseen niiden samankaltaisuuden.
esimerkiksi, sanotaan, että meillä on dataa, joka sisältää lukion CGPA kymmeniä opiskelijoita (jotka vaihtelevat 0-5) ja niiden tulevaisuuden tulot (tuhansia Rupiaa):

Koska molemmat ominaisuudet ovat eri mittakaavoissa, on mahdollista, että korkeampi weightage annetaan ominaisuuksia, joilla on korkeampi suuruusluokkaa. Tämä vaikuttaa koneen oppimisen algoritmin suorituskykyyn, ja ilmeisesti emme halua algoritmiamme kaasutettavan kohti yhtä ominaisuutta.,
Siksi meidän mittakaavassa meidän tiedot ennen työllistävät etäisyys pohjainen algoritmi niin, että kaikki ominaisuudet edistävät yhtä lailla tulos.,nts A ja B sekä B ja C, ennen ja jälkeen skaalauksen kuten alla:
- Etäisyys AB, ennen kuin skaalaus =>

- Etäisyys BC ennen skaalaus =>

- Etäisyys AB sen jälkeen, kun skaalaus =>

- Etäisyys BC jälkeen skaalaus =>

Skaalaus on tuonut sekä ominaisuuksia kuvaan ja etäisyydet ovat nyt vertailukelpoisempia kuin ne olivat ennen kuin voimme soveltaa skaalaus.,
Puu-Pohjainen Algoritmien
Puu-pohjaisia algoritmeja, toisaalta, ovat melko herkkiä laajuuden ominaisuudet. Ajattele sitä, päätös puu halkaisee solmun vain yhden ominaisuuden perusteella. Ratkaisupuu jakaa solmun ominaisuudella, joka lisää solmun homogeenisuutta. Tämä jako ominaisuus ei vaikuta muita ominaisuuksia.
Niin, ei ole käytännössä mitään vaikutusta loput ominaisuudet split. Tämä tekee niistä invariant mittakaavassa ominaisuuksia!
mikä on normalisointi?,
normalisointi on skaalaustekniikka, jossa arvoja siirretään ja uudelleenskaalataan niin, että ne päätyvät välillä 0-1. Se tunnetaan myös nimellä Min-Max skaalaus.
Tässä on kaava normalisointi:
Tässä, Xmax ja Xmin ovat suurin ja pienin arvot ominaisuus vastaavasti.,
- Kun X: n arvo on pienin arvo sarakkeessa, osoittajaan tulee 0, ja siten X on 0
- toisaalta, kun X: n arvo on suurin arvo sarakkeessa, osoittaja on sama nimittäjä, ja näin ollen X: n arvo on 1
- Jos X: n arvo on välillä pienin ja suurin arvo, sitten X: n arvo on välillä 0 ja 1
Mitä on Standardisointi?
Standardointi on toinen skaalaus tekniikka, jossa arvot on keskittynyt tarkoita yksikkö keskihajonta., Tämä tarkoittaa, että attribuutin keskiarvo muuttuu nollaksi ja tulosjakaumassa on yksikkökohtainen keskihajonta.
Tässä on kaava standardointi:
on siis ominaisuus, arvot ja
on keskihajonta ominaisuus arvot. Huomaa, että tässä tapauksessa arvot eivät rajoitu tiettyyn alueeseen.
nyt, iso kysymys mielessäsi täytyy olla, milloin meidän pitäisi käyttää normalisointia ja milloin meidän pitäisi käyttää standardointia? Otetaan selvää!,
iso kysymys-normalisoida vai standardoida?
Normalisointi vs. standardointi on ikuinen kysymys keskuudessa koneoppimisen tulokkaita. Saanen tarkentaa tässä kohdassa olevaa vastausta.
- normalisointia on hyvä käyttää, kun tietää, että tietojesi jakelu ei seuraa Gaussin jakautumista. Tämä voi olla hyödyllistä algoritmeissa, jotka eivät oleta tietojen jakautumista kuten K-lähimmät naapurit ja Neuroverkkoja.
- standardoinnista taas voi olla apua tapauksissa, joissa tieto seuraa Gaussin jakautumista., Tämän ei kuitenkaan tarvitse välttämättä pitää paikkaansa. Myös, toisin kuin normalisointi, standardointi ei ole rajaava alue. Standardointi ei siis vaikuta heihin, vaikka tiedoissa olisikin poikkeavia tekijöitä.
Kuitenkin, lopussa päivä, valinta käyttäen normalisointi tai standardointi riippuu ongelman ja koneoppimisen algoritmia käytät. Ei ole vaikeaa ja nopeaa sääntöä kertoa sinulle, milloin normalisoida tai standardoida tietosi., Voit aina aloittaa asentamalla mallisi raakoihin, normalisoituihin ja standardoituihin tietoihin ja vertailla suorituskykyä parhaisiin tuloksiin.
on hyvä käytäntö sovittaa skaalain harjoitustietoihin ja käyttää sitä testaustietojen muuntamiseen. Näin vältettäisiin tietovuodot mallitestausprosessin aikana. Myöskään tavoitearvojen skaalausta ei yleensä tarvita.
Täytäntöönpanossa Ominaisuus Skaalaus Python
– Nyt tulee hauska osa – laskemisesta, mitä olemme oppineet käytännössä., Aion soveltaa ominaisuus skaalaus muutamia koneoppimisen algoritmeja Iso Mart dataset olen ottanut DataHack Alustan.
olen ohita esikäsittely vaiheet, koska ne eivät kuulu tämän opetusohjelman. Mutta löydät ne siististi selitetty tässä artikkelissa. Nämä vaiheet avulla voit päästä alkuun 20 persentile on hackathon leaderboard niin, että kannattaa tarkistaa!
Niin, katsotaanpa ensin jaetaan tietoa osaksi koulutusta ja testaus sarjat:
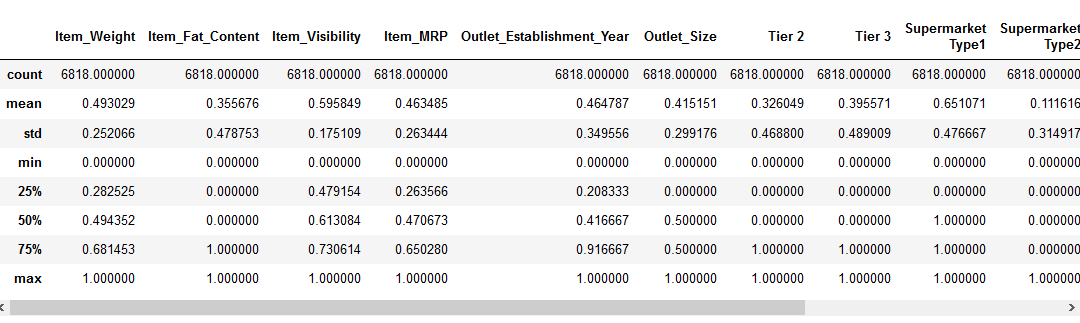
Ennen kuin siirrytään ominaisuus skaalaus-osassa, katsotaanpa vilkaista yksityiskohtaisia tietoja meidän tietoja käyttämällä pd.,kuvaile () – menetelmä:
– Voimme nähdä, että on olemassa valtava ero välillä arvot läsnä meidän numeeriset ominaisuudet: Item_Visibility, Item_Weight, Item_MRP, ja Outlet_Establishment_Year. Yritetään korjata, että käyttämällä ominaisuus skaalaus!
Huomautus: huomaat negatiivisia arvoja Item_Visibility ominaisuus, koska olen ottanut log-muunnos käsitellä vinous ominaisuus.
Normalisointi käyttäen sklearn
normalisoida tiedot, sinun täytyy tuoda MinMaxScalar päässä sklearn kirjasto ja soveltaa sitä meidän aineisto., Tehdään se!
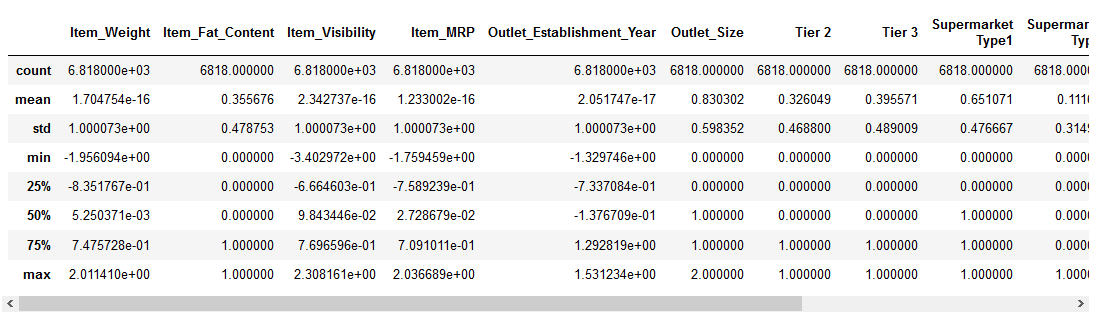
katsotaanpa, miten normalisointi on vaikuttanut meidän aineisto:
Kaikki ominaisuudet nyt on minimiarvo on 0 ja maksimiarvo 1. Täydellistä!
kokeile yllä olevaa koodia alla olevassa live-koodausikkunassa!!
Seuraavaksi yritetään yhtenäistää meidän tiedot.
Standardointi käyttäen sklearn
yhtenäistää tiedot, sinun täytyy tuoda StandardScalar päässä sklearn kirjasto ja soveltaa sitä meidän aineisto., Tässä on, miten voit tehdä sen:
olisit huomannut, että en vain soveltaa standardointia minun numeerisia sarakkeita ja ei muita Yksi-Kuuma Koodattu ominaisuuksia. Yhden kuuman koodatun ominaisuuden standardointi merkitsisi jakautumisen määrittämistä kategorisille piirteille. Et halua tehdä sitä!
mutta miksi en tehnyt samaa normalisoidessani tietoja? Koska yhden Hot koodatut ominaisuudet ovat jo välillä 0-1. Normalisointi ei siis vaikuttaisi niiden arvoon.,
– Selvä, katsotaanpa, miten standardointi on muuttanut meidän tiedot:
numeeriset ominaisuudet ovat nyt keskitetty keskiarvo yksikkö keskihajonta. Mahtavaa!
Vertaamalla unscaled, normalisoitu ja standardoituja tietoja
Se on aina hyvä visualisoida tietosi ymmärtää jakelu läsnä. Voimme nähdä vertailun meidän unscaled ja skaalattu tiedot käyttäen boxplots.
voit lukea lisää datan visualisoinnista täältä.,
Voit huomata, miten skaalaus ominaisuuksia tuo kaiken oikeisiin mittasuhteisiin. Ominaisuudet ovat nyt vertailukelpoisempia ja vaikuttavat samalla tavalla oppimismalleihin.
Hakeminen Skaalaus koneoppimisen Algoritmeja
– nyt on aika kouluttaa joitakin koneoppimisen algoritmeja meidän tietojen verrata vaikutuksia eri skaalaus tekniikoita suorituskyvyn algoritmi. Haluan nähdä skaalauksen vaikutuksen erityisesti kolmeen algoritmiin: K-lähimmät naapurit, Support Vector Regressor ja Decision Tree.,
k-lähimmät naapurit
kuten aiemmin näimme, KNN on etäisyyteen perustuva algoritmi, johon ominaisuuksien valikoima vaikuttaa. Katsotaanpa, miten se toimii meidän tiedot, ennen ja jälkeen skaalauksen:
Voit nähdä, että skaalaus ominaisuuksia on tuonut alas RMSE pisteet meidän KNN-malli. Erityisesti normalisoitu data toimii hieman paremmin kuin standardoitu data.
Huom: olen mittaaminen RMSE täällä, koska tämä kilpailu arvioi RMSE.
Tukivektorin Regressori
SVR on toinen etäisyyteen perustuva algoritmi., Joten katsotaanpa tarkistaa, onko se toimii paremmin normalisointi tai standardointi:
– Voimme nähdä, että skaalaus ominaisuuksia ei tuoda alas RMSE pisteet. Ja standardoidut tiedot ovat toimineet paremmin kuin normalisoidut tiedot. Miksi luulet niin?
sklearnin dokumentaatiossa todetaan, että SVM olettaa RBF-ytimen kanssa, että kaikki ominaisuudet keskittyvät nollan ympärille ja varianssi on samaa luokkaa. Tämä johtuu ominaisuus, jonka varianssi on suurempi kuin muut estää estimaattori päässä oppia kaikki ominaisuudet., Hienoa!
päätöspuu
tiedämme jo, että päätöspuu on invariantti ominaisuus skaalaus. Mutta halusin näyttää käytännön esimerkki siitä, miten se toimii tiedot:
Voit nähdä, että RMSE pisteet ei ole edennyt tuuman skaalaus ominaisuuksia. Joten voit olla varma, kun käytät puupohjaisia algoritmeja tietosi!,
End Huomautuksia
Tämä opetusohjelma kattaa merkitystä käyttämällä skaalaus ominaisuus teidän tiedot ja miten normalisointi ja standardisointi ovat vaihtelevia vaikutuksia työ -, kone oppimisen algoritmeja,
– Pitää muistaa, että ei ole oikea vastaus, kun käyttää normalisointi yli standardointi ja päinvastoin. Kaikki riippuu tiedoistasi ja käyttämästäsi algoritmista.
seuraavassa vaiheessa kannustan kokeilemaan ominaisuuksien skaalausta muiden algoritmien kanssa ja selvittämään, mikä toimii parhaiten – normalisointi vai standardointi?, Suosittelen, että käytät BigMart myyntitiedot tähän tarkoitukseen ylläpitää jatkuvuutta tämän artikkelin. Ja älä unohda jakaa oivalluksia alla olevassa kommenttiosiossa!
Voit myös lukea tämän artikkelin meidän Mobile APP