Johdanto
Lajittelu tietojen järjestäminen tarkoittaa sitä tietyssä järjestyksessä, usein array-kuten tietojen rakenne. Voit käyttää erilaisia tilaus-kriteerit, yhteiset niistä on lajittelu numerot ainakin suurimpaan tai päinvastoin, tai lajittelua jouset kirjaimet. Voit jopa määritellä omat kriteerisi, ja käymme läpi käytännön tapoja tehdä se tämän artikkelin loppuun mennessä.,
Jos olet kiinnostunut siitä, miten lajittelu toimii, me kattaa erilaisia algoritmeja, alkaen tehotonta, mutta intuitiivinen ratkaisuja, tehokkaita algoritmeja, jotka ovat tosiasiallisesti toteutettu Java ja muita kieliä.
on olemassa erilaisia lajittelualgoritmeja, eivätkä ne kaikki ole yhtä tehokkaita. Analysoimme niiden ajan monimutkaisuutta, jotta voimme vertailla niitä ja nähdä, mitkä niistä suoriutuvat parhaiten.,
listan algoritmit opit tässä ei suinkaan ole tyhjentävä, mutta olemme koonneet joitakin yleisimmistä ja tehokkaimmista niistä auttaa sinua pääsemään alkuun:
- Bubble-Sort
- lisäyslajittelun
- Valinta Lajitella
- Merge Sort
- Kekojärjestäminen
- Pikalajittelun
- Lajittelu Java
Huomautus: Tässä artikkelissa ei käsitellä samanaikaisesti lajittelu, koska se on tarkoitettu aloittelijoille.
Bubble Lajittele
Selitys
Kupla lajitella toimii vaihtamalla vierekkäisten elementtien jos he eivät ole halutussa järjestyksessä., Tämä prosessi toistaa alusta asti array kunnes kaikki elementit ovat kunnossa.
Me tiedämme, että kaikki elementit ovat paikallaan, kun onnistumme tekemään koko iteraation ilman vaihtamalla lainkaan – sitten kaikki elementit meillä verrattuna olivat halutussa järjestyksessä niiden vieressä elementtejä, ja laajennus, koko joukko.
Tässä ovat vaiheet lajittelu joukko numeroita ainakin suurin:
-
4 2 1 5 3: kaksi ensimmäistä elementit ovat väärässä järjestyksessä, joten me vaihtaa niitä.
-
2 4 1 5 3: kaksi muuta elementtiä ovat myös väärässä järjestyksessä, joten vaihdamme.,
-
2 1 4 5 3: Nämä kaksi ovat oikeassa järjestyksessä, 4 < 5, joten jätämme heidät yksin.
-
2 1 4 5 3: Another swap.
-
2 1 4 3 5: Here ’ s the resulting array after one iteration.
Koska ainakin yksi vaihto tapahtui aikana ensikierron (oikeastaan kolme), meidän täytyy mennä läpi koko joukko uudelleen ja toista sama prosessi.
toistamalla tätä prosessia, kunnes swapeja ei enää tehdä, meillä on lajiteltu joukko.,
syy tämä algoritmi on nimeltään Kupla Lajitella on koska numerot eräänlainen ”kupla” ”pinta.”Jos käyt esimerkkimme läpi uudelleen, tietyn numeron (4 on hyvä esimerkki) jälkeen, näet sen liikkuvan hitaasti oikealle prosessin aikana.
Kaikki numerot siirrä niiden paikkoja, vähän kerrallaan, vasemmalta oikealle, kuten kuplia hitaasti nousee vesistö.
Jos haluat lukea yksityiskohtaisen, oma artikkeli Kupla Lajitella, meillä on sinulle kuulu!,
Toteutus
aiomme toteuttaa Kupla Lajitella samalla tavalla olemme pani sen sanat. Meidän toiminto tulee jonkin aikaa silmukka, jossa se menee läpi koko array swapping tarvittaessa.
oletamme, että array on lajiteltu, mutta jos olemme todistetusti väärässä lajittelussa (jos swap tapahtuu), käymme läpi toisen iteraation. While-loop sitten pitää käynnissä, kunnes onnistumme läpäisemään koko array ilman vaihtamista:
kun käytät tätä algoritmia, meidän täytyy olla varovaisia, miten lausumme swap kunnossa.,
esimerkiksi, jos minulla olisi käyttää a >= a – se olisi voinut päättyä ääretön silmukka, koska tasa-elementtejä, tämä suhde olisi aina true, ja näin ollen aina vaihtaa niitä.
Ajassa
selvittää, aikavaativuus Kupla Lajitella, meidän täytyy tarkastella pahin mahdollinen skenaario. Mikä on suurin määrä kertoja meidän täytyy kulkea läpi koko array ennen kuin olemme selvittäneet sen?, Harkitse seuraava esimerkki:
5 4 3 2 1ensimmäistä iterointia, 5 ”kupla pintaan,” mutta loput elementit pysyisivät alenevassa järjestyksessä. Meidän olisi pitänyt tehdä yksi iterointia jokaisen elementin, paitsi 1, ja sitten toinen iteraatio tarkistaa, että kaikki on kunnossa, niin yhteensä 5 toistoja.
Laajentaa tätä tahansa joukko n – elementtejä, ja se tarkoittaa, että sinun täytyy tehdä n toistojen., Katsot koodin, se tarkoittaisi, että meidän while loop voi ajaa enintään n kertaa.
Jokainen näistä n kertaa olemme iteroimalla läpi array (for-silmukan koodi), eli pahimman tapauksen aikavaativuus olisi O(n^2).
Huomautus: aikakompleksisuus tulisi aina olla O(n^2) jos se ei olisi ollut sorted boolean tarkista, joka päättyy algoritmi, jos ei ole mitään vaihtosopimukset sisempi silmukka – mikä tarkoittaa, että matriisi on lajiteltu.,
lisäyslajittelun
Selitys
ajatuksena lisäyslajittelu on jakamalla array osaksi lajitellut ja lajittelemattomat subarrays.
lajiteltu osa on alussa pituudeltaan 1 ja vastaa matriisin ensimmäistä (vasemmanpuoleisinta) elementtiä. Me iteroidaan kautta array ja jokaisen iteraation, laajennamme lajiteltu osa array yhdellä elementillä.
laajetessaan asetamme uuden alkuaineen oikeaan paikalleen lajitellun alaraadin sisään. Teemme tämän siirtämällä kaikki elementit oikealle, kunnes kohtaamme ensimmäisen elementin, jota ei tarvitse siirtää.,
esimerkiksi, jos seuraavat array lihavoitu osa on lajiteltu nousevaan järjestykseen, tapahtuu seuraavaa:
-
3 5 7 8 4 2 1 9 6: Voimme ottaa 4 ja muistaa, että se mitä tarvitsemme lisää. Koska 8 > 4, siirrytään.
-
3 5 7 x 8 2 1 9 6: Jossa x: n arvo ei ole ratkaisevan tärkeää, koska se tulee päälle välittömästi (joko 4, jos se on sen oikea paikka tai 7 jos me shift). Koska 7 > 4, siirrytään.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
tämän prosessin Jälkeen, lajiteltu osan laajennettiin, jonka yksi elementti, nyt meillä on viiden sijaan neljä elementtiä. Jokainen iteraatio tekee tämän, ja lopussa koko joukko on lajiteltu.
Jos haluat lukea yksityiskohtaisen, omistettu artikkelin Lisäys Lajitella, meillä on sinulle kuulu!,
Toteutus
Ajassa
Jälleen, meidän on tarkasteltava pahimmassa tapauksessa meidän algoritmi, ja se on jälleen esimerkki, jossa koko joukko on laskeva.
Tämä johtuu siitä, että jokaisessa iteraatiossa joudutaan siirtämään koko lajiteltu lista yhdellä, joka on O(n). Meidän on tehtävä tämä jokaisen elementin jokaisen array, mikä tarkoittaa, että se tulee rajoittumaan O (n^2).
Valinta Lajittele
Selitys
Valinta Lajitella myös jakaa array osaksi lajitellun ja lajittelemattoman subarray., Tosin, tällä kertaa, lajiteltu subarray on muodostettu asettamalla pienin osa lajittelematon subarray lopussa lajitellun array, vaihtamalla:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Toteutus
jokaisen iteraation, voimme olettaa, että ensimmäinen lajittelemattoman elementti on pienin ja kerrata läpi loput nähdä, jos siellä on pienempi elementti.,
Kun huomaamme, nykyinen vähintään lajittelemattoman osa array, me vaihtaa sen ensimmäisen elementin ja pitävät sitä osa lajitellaan array:
Ajassa
Löytää minimi on O(n) pituus array, koska meidän täytyy tarkistaa kaikki elementit. Meidän on löydettävä pienin kukin alkio, jolloin koko prosessi rajaamalla O(n^2).,
Merge Sort
Selitys
Merge-Sort käyttää rekursio ratkaista ongelma lajittelu tehokkaammin kuin algoritmit aikaisemmin esitetty, ja erityisesti se käyttää hajota ja hallitse lähestymistapa.
Käyttämällä näitä molempia käsitteitä, me murtaa koko joukko kahteen subarrays ja sitten:
- Lajitella vasen puoli array (rekursiivisesti)
- Eräänlainen oikea puoli array (rekursiivisesti)
- Yhdistää ratkaisuja
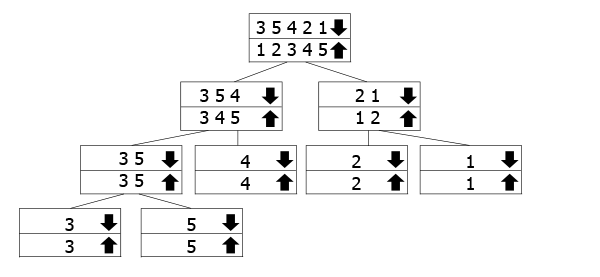
Tämä puu on tarkoitettu edustamaan, miten rekursiokutsua työtä., Nuolella merkityt ryhmät ovat niitä, joita kutsumme funktioksi, samalla kun yhdistämme ylös nuolia. Seuraat nuolta puun pohjaan ja palaat yhdistymään.
Tässä esimerkissä, meillä on array 3 5 3 2 1, niin se jaetaan 3 5 4 ja 2 1. Lajittelemme ne ja jaamme ne niiden osiin. Kun olemme päässeet pohjalle, alamme yhdistyä ja lajittelemme niitä.,
Jos haluat lukea yksityiskohtaisen, omistettu artikkeli Yhdistää Tavallaan, meillä on sinulle kuulu!
toteutus
ydintoiminto toimii melko lailla selityksen mukaisesti. Olemme vain ohimennen indeksit left ja right jotka ovat indeksejä vasemmalle-eniten ja oikea-suurin osa subarray haluamme lajitella. Aluksi, nämä pitäisi olla 0 ja array.length-1, riippuen toteutuksesta.,
pohjan meidän rekursio varmistaa, me poistua, kun olemme valmis, tai kun right ja left tavata toisiaan. Löydämme midpoint mid, ja lajittelemme subarrayt vasemmalle ja oikealle siitä rekursiivisesti, lopulta yhdistämällä ratkaisumme.
Jos muistat puugrafiikkamme, saatat ihmetellä, miksi emme luo kahta uutta pienempää matriisia ja anna niitä eteenpäin sen sijaan. Tämä on koska on todella pitkä paneelit, tämä aiheuttaisi valtavia muistin kulutus jotain, joka on käytännössä tarpeetonta.,
Merge Sort jo ei toimi-paikka, koska yhdistämisen vaihe, ja tämä vain pahentaa sen muistin tehokkuutta. Logiikka meidän puu rekursio muuten pysyy samana, vaikka, meidän täytyy vain seurata indeksit käytämme:
yhdistää lajitella subarrays yhteen, meidän täytyy laskea pituus kunkin ja tehdä väliaikainen taulukot kopioida niitä, jotta voisimme vapaasti muuttaa tärkein array.
kopioinnin jälkeen käymme tuloksena olevan matriisin läpi ja määritämme sille nykyisen minimin., Koska meidän subarrays lajitellaan, me vain valitsi pienemmän kaksi elementtiä, joita ei ole valittu toistaiseksi, ja siirrä iteraattori, että subarray eteenpäin:
Ajassa
Jos haluamme saada monimutkaisuus rekursiivinen algoritmeja, meidän täytyy saada hieman mathy.
Kantalausetta käytetään rekursiivisten algoritmien ajallisen kompleksisuuden selvittämiseen. Ei-rekursiivinen algoritmeja, me yleensä kirjoittaa tarkka aikavaativuus kuin jonkinlainen yhtälö, ja sitten käytämme Iso-O-Notaatio järjestää ne luokkiin samoin käyttäytyy algoritmeja.,
ongelma rekursiivinen algoritmeja on, että sama yhtälö voisi näyttää tältä:
$$
T(n) = aT(\frac{n}{b}) + cn^k
$$
yhtälö itsessään on rekursiivinen! Tässä yhtälössä a kertoo, kuinka monta kertaa me kutsumme rekursio, ja b kertoo, kuinka moneen osaan meidän ongelma on jaettu. Tässä tapauksessa, että voi tuntua merkityksetön ero, koska ne ovat sama mergesort, mutta joitakin ongelmia ne voivat olla.,
yhtälön loppuosa on kompleksisuus kaikkien näiden ratkaisujen yhdistämisessä yhdeksi lopussa., Mestari Lause ratkaisee tämän yhtälön meille:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
– Jos T(n) runtime on algoritmi, kun lajittelu array pituus n, Yhdistää Tavallaan olisi ajaa kaksi paneelit, jotka ovat puolet pituudesta alkuperäinen array.,
Joten jos meillä on a=2, b=2. Yhdistämisvaihe vie O (n) muistia, joten k=1. Tämä tarkoittaa sitä, että yhtälö Yhdistää Tavallaan näyttäisi seuraavalta:
$$
T(n) = 2T(\frac{n}{2})+cn
$$
Jos sovelletaan Master Theorem, me näemme, että meidän tapauksessa on sellainen, jossa a=b^k koska olemme 2=2^1. Tämä tarkoittaa meidän monimutkaisuus on O (nlog n). Tämä on erittäin hyvä aika monimutkaisuus lajittelualgoritmi, koska on todistettu, että array ei voi lajitella nopeammin kuin O (nlog n).,
vaikka esittelemämme versio on muistia vievä, on olemassa monimutkaisempia Merge Sort-versioita, jotka vievät vain O(1) – tilaa.
lisäksi algoritmi on erittäin helppo yhdensuuntaistettua, koska rekursiokutsua yhdestä solmusta voidaan suorittaa täysin itsenäisesti erilliset oksat. Vaikka emme päästä miten ja miksi, koska se on soveltamisalan ulkopuolella tämän artikkelin, se kannattaa pitää mielessä hyvät käyttää tätä algoritmia.,
Kekojärjestäminen
Selitys
oikein ymmärrä, miksi Kekojärjestäminen toimii, sinun on ensin ymmärtää rakenteen se perustuu – kasaan. Puhumme kannalta binary kasaan erityisesti, mutta voit yleistää suurimman osan tästä muihin kasaan rakenteita samoin.
kasaan on puu, joka täyttää kasaan omaisuutta, joka on, että kunkin solmun kaikki sen lapset ovat tietyssä suhteessa siihen. Lisäksi kasan on oltava lähes valmis., Lähes täydellinen binääripuu syvyys d on alipuun syvyys d-1 kanssa samaa juurta, joka on täydellinen, ja jossa jokaisen solmun vasen jälkeläinen on koko vasen alipuu. Toisin sanoen solmua lisättäessä mennään aina korkeimman keskeneräisen tason vasempaan asentoon.
Jos keko on max-heap, niin kaikki lapset ovat pienempiä kuin vanhempi, ja jos se on min-heap ne kaikki ovat suurempia.,
Toisin sanoen, kun siirrät alas puusta, saat pienempi ja pienempi määrä (min-heap) tai suurempi ja suurempi määrä (max-heap). Tässä on esimerkki max-heap:
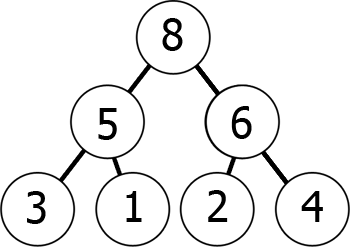
Voimme edustaa tätä max-heap muisti array seuraavalla tavalla:
8 5 6 3 1 2 4Voit kuvitella sen lukemalla kuvaajaa taso kerrallaan, vasemmalta oikealle., Mitä olemme saavuttaneet tähän on se, että jos otamme kth elementti array, sen lasten kannat ovat 2*k+1 ja 2*k+2 (olettaen, että indeksointi alkaa 0: sta). Voit tarkistaa tämän itse.
Toisaalta, esimerkiksi kth elementti vanhemman asema on aina (k-1)/2.
Tietäen tämän, voit helposti ”max-heapify” tahansa sijainnista. Tarkista jokaisen elementin osalta, onko jokin sen lapsista pienempi kuin se., Jos ne ovat, vaihda yksi niistä vanhemman kanssa, ja rekursiivisesti toista tämä vaihe, jossa vanhempi (koska uusi suuri osa saattaa olla vielä suurempi kuin sen toinen lapsi).
Lehdet ei ole lapsia, joten ne ovat triviaalisti max-kasoista oman:
-
6 1 8 3 5 2 4: Molemmat lapset ovat pienempiä kuin vanhempi, niin kaikki pysyy samana.
-
6 1 8 3 5 2 4: Koska 5 > 1, me vaihtaa niitä. Me rekursiivisesti heapify 5 Nyt.
-
6 5 8 3 1 2 4: Molemmat lapset ovat pienempiä, niin mitään ei tapahdu.,
-
6 5 8 3 1 2 4: Koska 8 > 6, me vaihtaa niitä.
-
8 5 6 3 1 2 4: we got the heap pictured above!
Kun olemme oppineet heapify array loput on melko yksinkertainen. Vaihdamme kasan juuren array loppuun ja lyhennämme array yhdellä.,
heapify lyhennetty array uudelleen, ja toista prosessi:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: vaihtoi
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: vaihtoi
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: vaihtoi
Ja niin edelleen, olen varma, että voit nähdä malli kehittymässä.
Toteutus
Ajassa
Kun tarkastelemme heapify() toiminto näyttää kaikki voidaan tehdä O(1), mutta sitten siinä on se ärsyttävä rekursiokutsu.,
kuinka monta kertaa sitä kutsutaan, pahimmassa tapauksessa? Pahimmassa tapauksessa se leviää kasan huipulle asti. Se tekee sen hyppäämällä kunkin solmun kantapäähän, niin aseman ympärillä i/2. se tarkoittaa, että se tekee pahimmillaan log n hyppyjä, ennen kuin se pääsee alkuun, niin monimutkaisuus on O(log n).
Koska heapSort() on selvästi O(n), koska for-silmukoita iteroimalla läpi koko array, tämä tekisi yhteensä monimutkaisuus Kekojärjestäminen O(nlog n).,
Kekojärjestäminen on in-place lajittelu eli se vie O(1) ylimääräistä tilaa, toisin kuin Yhdistää Lajitella, mutta se on joitakin haittoja samoin, kuten on vaikea parallelize.
Quicksort
selitys
Quicksort on toinen hajota ja hallitse-algoritmi. Se poimii yhden elementin array kuin pivot ja lajittelee kaikki muut elementit ympärillä, esimerkiksi pienemmät elementit vasemmalle, ja suurempi oikealle.
tämä takaa, että nivel on prosessin jälkeen paikallaan., Sitten algoritmi rekursiivisesti tekee saman vasemmalle ja oikealle osia array.
Toteutus
Ajassa
aikakompleksisuus Pikalajittelun voidaan ilmaista seuraavalla yhtälöllä:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
pahimmassa tapauksessa on, kun suurin tai pienin elementti on aina valinnut pivot. Yhtälö olisi sitten näyttää tältä:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
Tämä osoittautuu O(n^2).,
Tämä saattaa kuulostaa pahalta, sillä olemme jo oppineet useita algoritmeja, jotka kulkevat O(nlog n) – ajassa pahimpana tapauksenaan, mutta Quicksort on itse asiassa hyvin laajalti käytössä.
Tämä on, koska se on todella hyvä keskiarvo runtime, myös rajaamalla O(nlog n), ja on erittäin tehokas, sillä suuri osa mahdollisista tuloa.
Yksi syy on edullista Yhdistää Tavallaan on, että se ei vie ylimääräistä tilaa, kaikki lajittelu on tehty,-paikka, ja ei ole kallista jakamista ja purkamisessa puhelut.,
Suorituskyvyn Vertailu
Että kaikki on sanottu, se on usein hyödyllistä suorittaa kaikki nämä algoritmit koneen pari kertaa saada käsityksen, miten ne toimivat.
He suorittaa eri tavoin eri kokoelmia, jotka on järjestetty tietenkin, mutta vaikka tämä mielessä, sinun pitäisi pystyä huomata joitakin trendejä.
katsotaanpa ajaa kaikki toteutukset, yksi kerrallaan, kukin kopio sekoitetaan array 10000 kokonaislukuja:
Voimme selvästi nähdä, että Kupla Lajitella on pahin, kun se tulee suorituskykyä., Vältä sen tuotantoa, jos et voi taata, että se tulee käsitellä vain pieniä kokoelmia, ja se ei ole viivyttää sovellus.
HeapSort ja QuickSort ovat parhaita suoritusviisaita. Vaikka he syöttöä vastaavia tuloksia, Pikalajittelun taipumus olla hieman parempi ja johdonmukaisempi – joka tarkistaa ulos.
Lajittelu Java
Comparable-Rajapinnan
Jos sinulla on oma tyyppejä, se voi saada hankala toteuttaa erillinen lajittelu algoritmi kullekin. Siksi Java tarjoaa käyttöliittymän, jonka avulla voit käyttää Collections.sort() oman luokat.,
Voit tehdä tämän, sinun luokka on toteuttaa Comparable<T> käyttöliittymä, jossa T ei teidän tyyppi, ja ohittaa menetelmä nimeltä .compareTo().
Tämä metodi palauttaa negatiivisen kokonaisluvun, jos this on pienempi kuin argumentti elementti, 0, jos he ovat yhtä, ja positiivinen kokonaisluku, jos this on suurempi.
Tässä esimerkissä olemme tehneet luokan Student, ja jokainen opiskelija on tunnistettavissa id ja vuodessa he aloittivat opintonsa.,
haluamme lajitella ne ensisijaisesti sukupolvien, mutta myös toissijaisesti Tunnukset:
Ja tässä on, miten käyttää sitä hakemuksen:
tuloksena on:
Vertailuryhmässä Käyttöliittymä
haluamme ehkä tavallaan meidän esineitä epäsovinnainen tavalla tiettyä tarkoitusta varten, mutta emme halua toteuttaa, että oletuksena käyttäytymistä meidän luokan, tai meillä voi olla lajittelu kokoelma on sisäänrakennettu tyyppi non-default tavalla.
tähän voidaan käyttää Comparator – rajapintaa., Esimerkiksi, katsotaanpa ottaa meidän Student luokan, ja tavallaan vain ID:
Jos me korvata tavallaan soittaa tärkein seuraavasti:
Arrays.sort(a, new SortByID());Lähtö:
Miten se Toimii
Collection.sort() toimii soittamalla taustalla Arrays.sort() menetelmä, kun lajittelu itse käyttää lisäyslajittelun paneelit lyhyempi kuin 47, ja Pikalajittelun loput.,
– Se perustuu tiettyyn kaksi-pivot täytäntöönpano Pikalajittelun joka varmistaa se välttää useimmat tyypillisiä syitä hajoamista osaksi toisen asteen suorituskyky, mukaan JDK10 asiakirjat.
Johtopäätös
Lajittelu on hyvin yleinen operaatio, jossa aineistot, onko se on analysoida niitä edelleen, nopeuttaa hakua käyttämällä tehokkaampia algoritmeja, jotka perustuvat tiedot on lajiteltu, suodattaa tietoja, jne.
lajittelua tukevat monet kielet ja rajapinnat usein hämärtävät, mitä ohjelmoijalle oikeasti tapahtuu., Vaikka tämä abstraktio on tervetullut ja tarpeen tehokasta työtä, se voi joskus olla tappava tehokkuus, ja se on hyvä tietää, miten toteuttaa eri algoritmeja ja tunnettava niiden hyviä ja huonoja puolia, sekä miten helposti käyttää sisäänrakennettu toteutuksia.