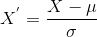Einführung in die Feature-Skalierung
Ich habe kürzlich mit einem Datensatz gearbeitet, der mehrere Funktionen hatte, die sich über unterschiedliche Größen, Bereiche und Einheiten erstrecken. Dies ist ein erhebliches Hindernis, da einige Algorithmen für maschinelles Lernen sehr empfindlich auf diese Funktionen reagieren.
Ich bin sicher, dass die meisten von Ihnen dieses Problem in Ihren Projekten oder Ihrer Lernreise gesehen haben müssen., Zum Beispiel ist eine Funktion vollständig in Kilogramm, während die andere in Gramm ist, eine andere ist Liter und so weiter. Wie können wir diese Funktionen nutzen, wenn sie in Bezug auf das, was sie präsentieren, so stark variieren?
Hier habe ich mich dem Konzept der Feature-Skalierung zugewandt. Es ist ein entscheidender Teil der Datenvorverarbeitungsphase, aber ich habe gesehen, dass viele Anfänger dies übersehen haben (zum Nachteil ihres maschinellen Lernmodells).,

Hier ist das Merkwürdige an der Feature – Skalierung-es verbessert (erheblich) die Leistung einiger Algorithmen für maschinelles Lernen und funktioniert überhaupt nicht für andere. Was könnte der Grund für diese Eigenart sein?
Was ist der Unterschied zwischen Normalisierung und Standardisierung? Dies sind zwei der am häufigsten verwendeten Feature-Scaling-Techniken im maschinellen Lernen, aber ein Maß an Mehrdeutigkeit besteht in ihrem Verständnis. Wann sollten Sie welche Technik anwenden?,
Ich werde diese und weitere Fragen in diesem Artikel zur Feature-Skalierung beantworten. Wir implementieren auch die Feature-Skalierung in Python, um Ihnen ein besseres Verständnis dafür zu vermitteln, wie sie für verschiedene Algorithmen für maschinelles Lernen funktioniert.
Hinweis: Ich gehe davon aus, dass Sie mit Python und Core Machine Learning Algorithmen vertraut sind., Wenn Sie neu in diesem Bereich sind, empfehle ich Ihnen, die folgenden Kurse zu besuchen:
- Python für Data Science
- Alle kostenlosen Kurse für maschinelles Lernen von Analytics Vidhya
- Angewandtes maschinelles Lernen
Inhaltsverzeichnis
- Warum sollten wir die Feature-Skalierung verwenden?
- Was ist Normalisierung?
- Was ist Normung?
- Die große Frage-Normalisieren oder standardisieren?,
- Implementierung der Feature-Skalierung in Python
- Normalisierung mit Sklearn
- Standardisierung mit Sklearn
- Anwenden der Feature-Skalierung auf Algorithmen für maschinelles Lernen
- K-Nearest Neighbours (KNN)
- Support Vector Regressor
- Decision Tree
Warum sollten wir Feature-Skalierung verwenden?
Die erste Frage, die wir beantworten müssen – warum müssen wir die Variablen in unserem Datensatz skalieren? Einige Algorithmen für maschinelles Lernen reagieren empfindlich auf die Feature-Skalierung, während andere praktisch invariant sind., Lassen Sie mich das genauer erklären.
Gradient Descent Based Algorithms
Algorithmen für maschinelles Lernen wie lineare Regression, logistische Regression, neuronales Netzwerk usw. für die Verwendung von Gradient Descent als Optimierungstechnik müssen Daten skaliert werden. Schauen Sie sich die folgende Formel für den Gradientenabstieg an:

Das Vorhandensein des Merkmalswerts X in der Formel wirkt sich auf die Schrittgröße des Gradientenabstiegs aus. Der Unterschied in den Funktionsbereichen führt zu unterschiedlichen Schrittgrößen für jedes Feature., Um sicherzustellen, dass sich der Gradientenabstieg reibungslos in Richtung der Minima bewegt und dass die Schritte für den Gradientenabstieg für alle Funktionen mit der gleichen Geschwindigkeit aktualisiert werden, skalieren wir die Daten, bevor wir sie dem Modell zuführen.
Wenn Funktionen in einem ähnlichen Maßstab vorhanden sind, kann der Gradientenabstieg schneller zum Minimum konvergieren.
Entfernungsbasierte Algorithmen
Entfernungsalgorithmen wie KNN, K-means und SVM sind am stärksten vom Funktionsumfang betroffen., Dies liegt daran, dass sie hinter den Kulissen Abstände zwischen Datenpunkten verwenden, um ihre Ähnlichkeit zu bestimmen.
Nehmen wir zum Beispiel an, wir haben Daten mit CGPA-Werten von Schülern der High School (von 0 bis 5) und ihren zukünftigen Einkommen (in Tausend Rupien):

Da beide Merkmale unterschiedliche Skalen haben, besteht die Möglichkeit, dass Funktionen mit höherer Größe eine höhere Gewichtung erhalten. Dies wirkt sich auf die Leistung des maschinellen Lernalgorithmus aus, und offensichtlich möchten wir nicht, dass unser Algorithmus auf ein Merkmal ausgerichtet ist.,
Daher skalieren wir unsere Daten, bevor wir einen entfernungsbasierten Algorithmus verwenden, so dass alle Funktionen gleichermaßen zum Ergebnis beitragen.,nts A und B und zwischen B und C, vor und nach der Skalierung, wie unten gezeigt:
- Distanz AB, bevor Sie die Skalierung =>

- Entfernung v. Chr. vor der Skalierung =>

- Distanz AB, nachdem Skalierung =>

- Strecke BC nach Skalierung =>

Skalierung gebracht hat, beide Funktionen in die Bild, und die Entfernungen sind nun besser vergleichbar, als Sie waren, bevor wir zu skalieren.,
Baumbasierte Algorithmen
Baumbasierte Algorithmen hingegen sind ziemlich unempfindlich gegen den Umfang der Features. Denken Sie darüber nach, ein Entscheidungsbaum teilt nur einen Knoten basierend auf einem einzelnen Feature auf. Der Entscheidungsbaum teilt einen Knoten in ein Feature auf, das die Homogenität des Knotens erhöht. Diese Aufteilung auf ein Feature wird nicht durch andere Features beeinflusst.
Es gibt also praktisch keine Auswirkung der verbleibenden Merkmale auf die Aufteilung. Dies macht sie invariant zum Maßstab der Funktionen!
Was ist Normalisierung?,
Normalisierung ist eine Skalierungstechnik, bei der Werte verschoben und neu skaliert werden, so dass sie zwischen 0 und 1 liegen. Es wird auch als Min-Max-Skalierung bezeichnet.
Hier ist die Formel für die Normalisierung:
Hier sind Xmax und Xmin die maximalen bzw. minimalen Werte des Features.,
- Wenn der Wert von X der Minimalwert in der Spalte ist, ist der Zähler 0, und daher ist X‘ 0
- Wenn der Wert von X der maximale Wert in der Spalte ist, ist der Zähler gleich dem Nenner und somit ist der Wert von X‘ 1
- Wenn der Wert von X zwischen dem minimalen und dem maximalen Wert liegt, liegt der Wert von X‘ zwischen 0 und 1
Was ist der Standardisierung?
Standardisierung ist eine weitere Skalierungstechnik, bei der die Werte um den Mittelwert mit einer Standardabweichung zentriert sind., Dies bedeutet, dass der Mittelwert des Attributs Null wird und die resultierende Verteilung eine Standardabweichung der Einheit aufweist.
Hier ist die Formel für die Standardisierung:
ist der Mittelwert der Merkmalswerte und
ist die Standardabweichung der Merkmalswerte. Beachten Sie, dass in diesem Fall die Werte nicht auf einen bestimmten Bereich beschränkt sind.
Nun, die große Frage in Ihrem Kopf muss sein, wann sollten wir Normalisierung verwenden und wann sollten wir Standardisierung verwenden? Lass es uns herausfinden!,
Die große Frage-Normalisieren oder standardisieren?
Normalisierung vs. Standardisierung ist eine ewige Frage unter Neulingen des maschinellen Lernens. Lassen Sie mich auf die Antwort in diesem Abschnitt näher eingehen.
- Normalisierung ist gut zu verwenden, wenn Sie wissen, dass die Verteilung Ihrer Daten nicht einer gaußschen Verteilung folgt. Dies kann in Algorithmen nützlich sein, die keine Verteilung der Daten wie K-Nächste Nachbarn und neuronale Netze annehmen.
- Die Standardisierung kann dagegen hilfreich sein, wenn die Daten einer gaußschen Verteilung folgen., Dies muss jedoch nicht unbedingt wahr sein. Im Gegensatz zur Normalisierung hat die Standardisierung auch keinen Begrenzungsbereich. Selbst wenn Sie Ausreißer in Ihren Daten haben, sind diese nicht von der Standardisierung betroffen.
Am Ende des Tages hängt die Wahl der Verwendung von Normalisierung oder Standardisierung jedoch von Ihrem Problem und dem von Ihnen verwendeten Algorithmus für maschinelles Lernen ab. Es gibt keine harte und schnelle Regel, die Ihnen sagt, wann Sie Ihre Daten normalisieren oder standardisieren müssen., Sie können jederzeit damit beginnen, Ihr Modell an rohe, normalisierte und standardisierte Daten anzupassen und die Leistung für beste Ergebnisse zu vergleichen.
Es empfiehlt sich, den Scaler an die Trainingsdaten anzupassen und dann die Testdaten zu transformieren. Dies würde Datenlecks während des Modelltestprozesses vermeiden. Auch die Skalierung von Zielwerten ist in der Regel nicht erforderlich.
Implementierung der Feature-Skalierung in Python
Jetzt kommt der lustige Teil – das Gelernte in die Praxis umzusetzen., Ich werde die Feature-Skalierung auf einige Algorithmen für maschinelles Lernen in dem Big Mart-Datensatz anwenden, den ich für die DataHack-Plattform verwendet habe.
Ich werde die Vorverarbeitungsschritte überspringen, da sie außerhalb des Bereichs dieses Tutorials liegen. Aber Sie können sie ordentlich in diesem Artikel erklärt finden. Diese Schritte ermöglichen es Ihnen, die Top 20 Perzentil auf dem Hackathon Leaderboard zu erreichen, so dass es sich lohnt, Check-out!
Teilen wir also zuerst unsere Daten in Trainings-und Testsätze auf:
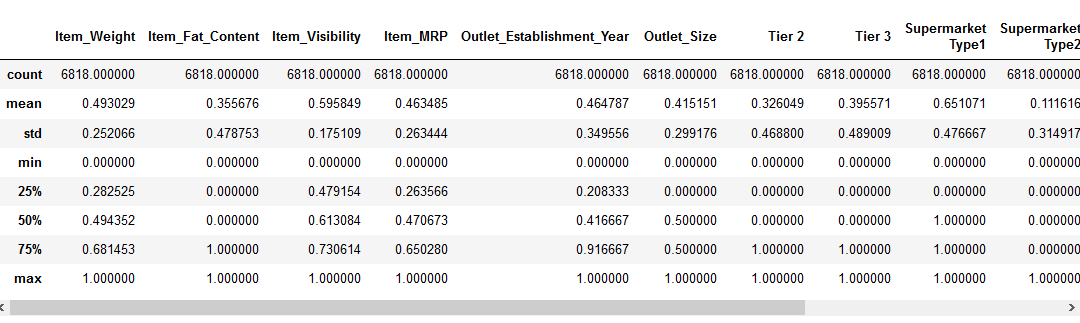
Bevor wir zum Feature-Skalierungsteil wechseln, werfen wir einen Blick auf die Details zu unseren Daten mit der pd.,describe () Methode:
Wir können sehen, dass es einen großen Unterschied im Wertebereich in unseren numerischen Merkmalen gibt: Item_Visibility, Item_Weight, Item_MRP und Outlet_Establishment_Year. Lassen Sie uns versuchen, das mit Feature Scaling zu beheben!
Hinweis: Sie werden negative Werte in der Item_Visibility-Funktion bemerken, da ich die Log-Transformation durchgeführt habe, um mit der Schiefe in der Funktion umzugehen.
Normalisierung mit sklearn
Um Ihre Daten zu normalisieren, müssen Sie den MinMaxScalar aus der sklearn-Bibliothek importieren und auf unseren Datensatz anwenden., Also, lass uns das tun!
Lassen Sie uns sehen, wie sich die Normalisierung auf unseren Datensatz ausgewirkt hat:
Alle Funktionen haben jetzt einen Mindestwert von 0 und einen Maximalwert von 1. Perfekt!
Probieren Sie den obigen Code im Live-Codierungsfenster unten aus!!
Als nächstes versuchen wir, unsere Daten zu standardisieren.
Standardisierung mit sklearn
Um Ihre Daten zu standardisieren, müssen Sie den StandardScalar aus der sklearn-Bibliothek importieren und auf unseren Datensatz anwenden., Hier ist, wie Sie es tun können:
Sie hätten bemerkt, dass ich nur meine numerischen Spalten standardisiert habe und nicht die anderen-Hot-codierten Funktionen. Die Standardisierung der One-Hot-codierten Funktionen würde bedeuten, kategorialen Funktionen eine Verteilung zuzuweisen. Du willst das nicht tun!
Aber warum habe ich beim Normalisieren der Daten nicht dasselbe getan? Weil One-Hot-codierte Funktionen bereits im Bereich zwischen 0 und 1 liegen. Die Normalisierung würde also ihren Wert nicht beeinflussen.,
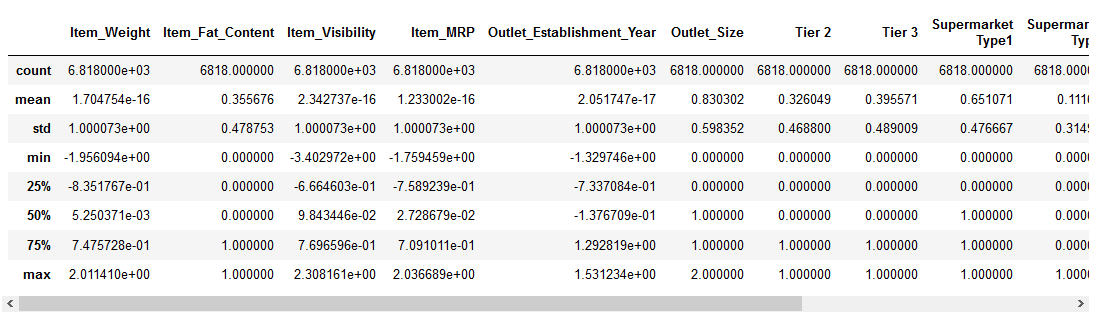
Richtig, schauen wir uns an, wie die Standardisierung unsere Daten verändert hat:
Die numerischen Merkmale konzentrieren sich nun auf den Mittelwert mit einer Standardabweichung pro Einheit. Genial!
Vergleichen Sie nicht skalierte, normalisierte und standardisierte Daten
Es ist immer großartig, Ihre Daten zu visualisieren, um die vorhandene Verteilung zu verstehen. Wir können den Vergleich zwischen unseren nicht skalierten und skalierten Daten mit Boxplots sehen.
Mehr zur Datenvisualisierung erfahren Sie hier.,
Sie können feststellen, wie die Skalierung der Merkmale bringt alles in die richtige Perspektive. Die Funktionen sind jetzt besser vergleichbar und werden sich ähnlich auf die Lernmodelle auswirken.
Anwenden der Skalierung auf Algorithmen für maschinelles Lernen
Es ist jetzt an der Zeit, einige Algorithmen für maschinelles Lernen in unseren Daten zu trainieren, um die Auswirkungen verschiedener Skalierungstechniken auf die Leistung des Algorithmus zu vergleichen. Ich möchte den Effekt der Skalierung insbesondere auf drei Algorithmen sehen: K-Nearest Neighbours, Support Vector Regressor und Decision Tree.,
K-Nearest Neighbours
Wie wir zuvor gesehen haben, ist KNN ein entfernungsbasierter Algorithmus, der vom Funktionsumfang beeinflusst wird. Mal sehen, wie es mit unseren Daten funktioniert, vor und nach der Skalierung:
Sie können sehen, dass die Skalierung der Funktionen den RMSE-Score unseres KNN-Modells gesenkt hat. Insbesondere führen die normalisierten Daten ein bisschen besser als die standardisierten Daten.
Hinweis: Ich messe hier die RMSE, weil dieser Wettbewerb die RMSE bewertet.
Support-Vector-Regressor
der SVR ist eine weitere Distanz-basierten Algorithmus., Schauen wir uns also an, ob es mit Normalisierung oder Standardisierung besser funktioniert:
Wir können sehen, dass die Skalierung der Funktionen den RMSE-Score senkt. Und die standardisierten Daten haben eine bessere Leistung erbracht als die normalisierten Daten. Warum glauben Sie, dass das der Fall ist?
Die sklearn-Dokumentation besagt, dass SVM mit dem RBF-Kernel davon ausgeht, dass alle Funktionen auf Null zentriert sind und die Varianz dieselbe Reihenfolge hat. Dies liegt daran, dass ein Merkmal mit einer größeren Varianz als das anderer verhindert, dass der Schätzer von allen Merkmalen lernt., Großartig!
Entscheidungsbaum
Wir wissen bereits, dass ein Entscheidungsbaum für die Feature-Skalierung invariant ist. Ich wollte jedoch ein praktisches Beispiel für die Leistung der Daten zeigen:
Sie können sehen, dass der RMSE-Score beim Skalieren der Funktionen keinen Zoll verschoben hat. Seien Sie also versichert, wenn Sie baumbasierte Algorithmen für Ihre Daten verwenden!,
Endnotizen
Dieses Tutorial behandelte die Relevanz der Verwendung der Feature-Skalierung für Ihre Daten und wie Normalisierung und Standardisierung unterschiedliche Auswirkungen auf die Arbeit von Algorithmen für maschinelles Lernen haben
Beachten Sie, dass es keine richtige Antwort darauf gibt, wann Normalisierung über Standardisierung und umgekehrt verwendet werden soll. Alles hängt von Ihren Daten und dem von Ihnen verwendeten Algorithmus ab.
Als nächsten Schritt empfehle ich Ihnen, die Feature-Skalierung mit anderen Algorithmen auszuprobieren und herauszufinden, was am besten funktioniert – Normalisierung oder Standardisierung?, Ich empfehle Ihnen, die BigMart-Verkaufsdaten zu diesem Zweck zu verwenden, um die Kontinuität mit diesem Artikel aufrechtzuerhalten. Und vergessen Sie nicht, Ihre Erkenntnisse im Kommentarbereich unten zu teilen!
Sie können diesen Artikel auch in unserer mobilen APP lesen