un método de muestreo de probabilidad es cualquier método de muestreo que utiliza alguna forma de selección aleatoria. Para tener un método de selección aleatoria, debe configurar algún proceso o procedimiento que asegure que las diferentes unidades de su población tengan las mismas probabilidades de ser elegidas. Los humanos han practicado durante mucho tiempo varias formas de selección aleatoria, como elegir un nombre de un sombrero o elegir la paja corta. En estos días, tendemos a utilizar las computadoras como el mecanismo para generar números aleatorios como base para la selección aleatoria.,
algunas definiciones
antes de poder explicar los diversos métodos de probabilidad tenemos que definir algunos términos básicos. Estos son:
-
Nes el número de casos en el marco de muestreo -
nes el número de casos en la muestra -
NCn= el número de combinaciones (subconjuntos) dendeN -
f = n/Nes la fracción de muestreo
Eso es todo., Con esos términos definidos podemos comenzar a definir los diferentes métodos de muestreo probabilístico.
muestreo aleatorio simple
la forma más simple de muestreo aleatorio se llama muestreo aleatorio simple. Bastante complicado, ¿eh? Aquí está la descripción rápida del muestreo aleatorio simple:
- Objetivo: seleccionar
nunidades fuera deNde modo que cadaNCntenga las mismas posibilidades de ser seleccionado. - procedimiento: utilice una tabla de números aleatorios, un generador de números aleatorios de computadora o un dispositivo mecánico para seleccionar la muestra.,
una definición algo zancuda, si bien precisa. Veamos si podemos hacerlo un poco más real.

¿Cómo se selecciona una muestra aleatoria simple? Supongamos que estamos investigando con una pequeña agencia de servicios que desea evaluar las opiniones de los clientes sobre la calidad del servicio durante el año pasado. Primero, tenemos que organizar el marco de muestreo. Para lograr esto, revisaremos los registros de la agencia para identificar a cada cliente en los últimos 12 meses. Si tenemos suerte, la agencia tiene buenos registros computarizados precisos y puede producir rápidamente tal lista., Entonces, tenemos que realmente dibujar la muestra. Decida el número de clientes que le gustaría tener en la muestra final. Por el bien del ejemplo, digamos que desea seleccionar 100 clientes para encuestar y que hubo 1000 clientes en los últimos 12 meses. Entonces, la fracción de muestreo es f = n/N = 100/1000 = .10(o 10%). Ahora, para realmente dibujar la muestra, tienes varias opciones. Podrías imprimir la lista de 1000 clientes, rasgar luego en tiras separadas, poner las tiras en un sombrero, mezclarlas muy bien, cerrar los ojos y sacar las primeras 100., Pero este procedimiento mecánico, sería tedioso y la calidad de la muestra dependerá de cuán profundamente mezclados de ellos y cómo al azar que alcanzó en. Tal vez un mejor procedimiento sería utilizar el tipo de máquina de bolas que es popular entre muchas de las loterías estatales. Necesitará tres conjuntos de bolas numeradas del 0 al 9, un conjunto para cada uno de los dígitos de 000 a 999 (si seleccionamos 000 lo llamaremos 1000)., Numere la lista de nombres de 1 a 1000 y luego use la máquina de bolas para seleccionar los tres dígitos que seleccionan a cada persona. La desventaja obvia aquí es que usted necesita conseguir las máquinas de la bola. (¿Dónde hacen esas cosas, de todos modos? ¿Hay una industria de máquinas de bolas?).
ninguno de estos procedimientos mecánicos es muy factible y, con el desarrollo de computadoras de bajo costo hay una manera mucho más fácil. Este es un procedimiento simple que es especialmente útil si ya tiene los nombres de los clientes en la computadora., Muchos programas informáticos pueden generar una serie de números aleatorios. Supongamos que puede copiar y pegar la lista de nombres de clientes en una columna en una hoja de cálculo de EXCEL. Luego, en la columna a su lado pegue la función =RAND()que es la forma de Excel de poner un número aleatorio entre 0y 1 en las celdas. Luego, ordena ambas columnas – la lista de nombres y el número aleatorio-por los números aleatorios. Esto reorganiza la lista en orden aleatorio del número aleatorio más bajo al más alto., Entonces, todo lo que tienes que hacer es tomar los primeros cien nombres en esta lista ordenada. bastante simple. Probablemente podrías lograr todo en menos de un minuto.
el muestreo aleatorio Simple es fácil de lograr y es fácil de explicar a los demás. Debido a que el muestreo aleatorio simple es una forma justa de seleccionar una muestra, es razonable generalizar los resultados de la muestra a la población. El muestreo aleatorio Simple no es el método de muestreo estadísticamente más eficiente y es posible que, solo por la suerte del sorteo, no obtenga una buena representación de los subgrupos en una población., Para abordar estas cuestiones, tenemos que recurrir a otros métodos de muestreo.
muestreo aleatorio estratificado
El muestreo aleatorio estratificado, también a veces llamado muestreo aleatorio proporcional o de cuota, implica dividir su población en subgrupos homogéneos y luego tomar una muestra aleatoria simple en cada subgrupo. En términos más formales:
Hay varias razones principales por las que puede preferir el muestreo estratificado sobre el muestreo aleatorio simple., En primer lugar, asegura que usted será capaz de representar no solo a la población en general, sino también subgrupos clave de la población, especialmente pequeños grupos minoritarios. Si desea poder hablar sobre subgrupos, esta puede ser la única manera de asegurar efectivamente que podrá hacerlo. Si el subgrupo es extremadamente pequeño, puede usar diferentes fracciones de muestreo (f) dentro de los diferentes estratos para sobre-muestrear aleatoriamente el grupo pequeño (aunque luego tendrá que ponderar las estimaciones dentro del grupo utilizando la fracción de muestreo siempre que desee estimaciones de población general)., Cuando utilizamos la misma fracción de muestreo dentro de los estratos, estamos llevando a cabo un muestreo aleatorio estratificado proporcional. Cuando usamos diferentes fracciones de muestreo en los estratos, llamamos a esto muestreo aleatorio estratificado desproporcionado. En segundo lugar, el muestreo aleatorio estratificado generalmente tendrá más precisión estadística que el muestreo aleatorio simple. Esto solo será cierto si los estratos o grupos son homogéneos. Si lo son, esperamos que la variabilidad dentro de los grupos sea menor que la variabilidad para la población en su conjunto. El muestreo estratificado capitaliza ese hecho.,
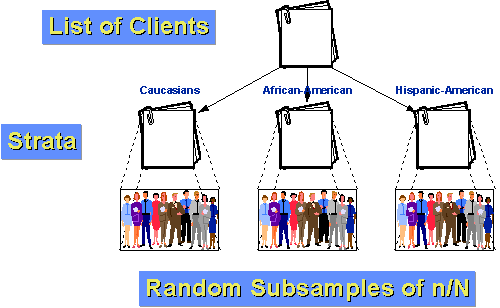
por ejemplo, digamos que la población de clientes de nuestra agencia se puede dividir en tres grupos: caucásicos, afroamericanos e Hispanoamericanos. Además, supongamos que tanto los afroamericanos como los hispanoamericanos son minorías relativamente pequeñas de la clientela (10% y 5% respectivamente)., Si solo hiciéramos una muestra aleatoria simple de n=100 con una fracción de muestreo de 10%, esperaríamos por casualidad que solo obtendríamos 10 y 5 personas de cada uno de nuestros dos grupos más pequeños. Y, por casualidad, podríamos conseguir menos que eso! Si estratificamos, podemos hacerlo mejor. Primero, determinemos cuántas personas queremos tener en cada grupo. Digamos que todavía queremos tomar una muestra de 100 de la población de 1000 clientes en el último año. Pero creemos que para decir algo sobre subgrupos necesitaremos al menos 25 casos en cada grupo., Por lo tanto, vamos a muestrear 50 caucásicos, 25 afroamericanos y 25 Hispanoamericanos. Sabemos que el 10% de la población, o 100 clientes, son afroamericanos. Si muestreamos aleatoriamente 25 de estos, tenemos una fracción de muestreo dentro del estrato de 25/100 = 25%. Del mismo modo, sabemos que el 5% o 50 clientes son Hispanoamericanos. Así que nuestra fracción de muestreo dentro del estrato será 25/50 = 50%. Finalmente, por resta sabemos que hay 850 clientes caucásicos. Nuestra fracción de muestreo dentro del estrato para ellos es 50/850 = about 5.88%., Debido a que los grupos son más homogéneos dentro del grupo que en toda la población en su conjunto, podemos esperar una mayor precisión estadística (menos varianza). Y, porque estratificamos, sabemos que tendremos suficientes casos de cada grupo para hacer inferencias de subgrupos significativos.,e son los pasos que debe seguir para lograr una sistemática al azar de la muestra:
- número de unidades en la población de
1aN - decidir sobre el
n(tamaño de muestra) que usted quiere o necesita -
k = N/n= el tamaño del intervalo - seleccionar al azar un número entero entre
1ak - luego tomar cada
kthunidad

Todo esto será mucho más claro con un ejemplo., Supongamos que tenemos una población que solo tiene N = 100 personas en ella y que desea tomar una muestra de n = 20. Para utilizar el muestreo sistemático, la población debe enumerarse en un orden aleatorio. La fracción de muestreo sería f = 20/100 = 20%. en este caso, el tamaño del intervalo, k, es igual a N/n = 100/20 = 5. Ahora, seleccione un entero aleatorio de 1 to 5. En nuestro ejemplo, imagine que eligió 4., Ahora, para seleccionar la muestra, comience con la unidad 4th en la lista y tome cada unidad k-th (cada 5A, porque k = 5). Usted estaría muestreando unidades 4, 9, 14, 19, y así sucesivamente a 100 y usted terminaría con 20 unidades en su muestra.
para que esto funcione, es esencial que las unidades en la población estén ordenadas aleatoriamente, al menos con respecto a las características que está midiendo. ¿Por qué querrías usar el muestreo aleatorio sistemático? Por un lado, es bastante fácil de hacer. Solo tienes que seleccionar un solo número aleatorio para comenzar las cosas., También puede ser más preciso que el simple muestreo aleatorio. Finalmente, en algunas situaciones simplemente no hay una manera más fácil de hacer el muestreo aleatorio. Por ejemplo, una vez tuve que hacer un estudio que incluía muestras de todos los libros de una biblioteca. Una vez seleccionado, tendría que ir a la estantería, localizar el libro y registrar la última vez que circuló. Sabía que tenía un marco de muestreo bastante bueno en forma de Lista de estantes (que es un catálogo de tarjetas donde las entradas se ordenan en el orden en que ocurren en el estante)., Para hacer una muestra aleatoria simple, podría haber estimado el número total de libros y generado números aleatorios para dibujar la muestra; pero ¿cómo encontraría el libro #74,329 fácilmente si ese es el número que seleccioné? ¡No pude contar las cartas hasta que llegué a 74.329! La estratificación tampoco resolvería ese problema. Por ejemplo, podría haber estratificado por cajón de catálogo de tarjetas y dibujado una muestra aleatoria simple dentro de cada cajón. Pero todavía estaría atascado contando cartas. En su lugar, hice una muestra aleatoria sistemática. Estimé el número de libros en toda la colección. Imaginemos que eran 100.000., Decidí que quería tomar una muestra de 1000 para una fracción de muestreo de 1000/100,000 = 1%. Para obtener el intervalo de muestreo k, que divide N/n = 100,000/1000 = 100. Luego seleccioné un entero aleatorio entre 1 y 100. Digamos que tengo 57.
a continuación, hice un pequeño estudio paralelo para determinar el grosor de mil tarjetas en el catálogo de tarjetas (teniendo en cuenta las diferentes edades de las tarjetas)., Digamos que en promedio encontré que dos tarjetas que estaban separadas por 100 las tarjetas estaban separadas por.75 pulgadas en el cajón del catálogo. Esa información me dio todo lo que necesitaba para dibujar la muestra. Conté hasta el 57 a mano y registré la información del libro. Entonces, tomé una brújula. (¿Recuerdas los de tu clase de matemáticas de secundaria? Son los divertidos instrumentos de metal con un alfiler afilado en un extremo y un lápiz en el otro que usabas para dibujar círculos en la clase de geometría., Luego puse la brújula en .75", pegué el extremo del pin en la tarjeta 57 y apunté con el extremo del lápiz a la siguiente tarjeta (aproximadamente a 100 libros de distancia). De esta manera, me aproximé a la selección de la 157a, 257A, 357a, y así sucesivamente. Pude llevar a cabo todo el procedimiento de selección en muy poco tiempo utilizando este método de muestreo aleatorio sistemático. Probablemente todavía estaría allí contando cartas si hubiera intentado otro método de muestreo aleatorio. (Vale, así que no tengo vida. Me compensaron muy bien, no me importa decirlo, por inventar este plan.,)
Cluster (área) Random Sampling
el problema con los métodos de muestreo aleatorio Cuando tenemos que muestrear una población que se distribuye a través de una amplia región geográfica es que tendrá que cubrir una gran cantidad de terreno geográficamente para llegar a cada una de las unidades que muestreó. Imagine tomar una simple muestra aleatoria de todos los residentes del Estado de Nueva York para realizar entrevistas personales. Por la suerte del sorteo, terminarás con encuestados que vienen de todo el estado. Sus entrevistadores van a tener un montón de viajes que hacer., Es precisamente para este problema que se inventó el muestreo aleatorio de conglomerados o áreas.
en el muestreo de conglomerados, seguimos estos pasos:
- dividir la población en conglomerados (generalmente a lo largo de límites geográficos)
- muestrear aleatoriamente conglomerados
- Medir todas las unidades dentro de los conglomerados muestreados
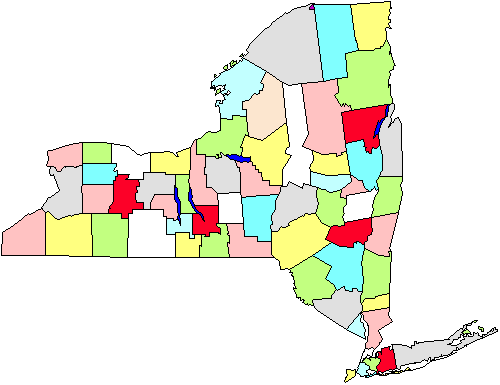
por ejemplo, en la figura vemos un mapa de los condados en el estado de Nueva York. Digamos que tenemos que hacer una encuesta de los gobiernos municipales que nos obligará a ir a las ciudades personalmente., Si hacemos una muestra aleatoria simple en todo el estado tendremos que cubrir todo el estado geográficamente. En su lugar, decidimos hacer un muestreo por conglomerados de cinco condados (marcados en rojo en la figura). Una vez que estos son seleccionados, vamos a cada gobierno de la ciudad en las cinco áreas. Es evidente que esta estrategia nos ayudará a ahorrar en nuestro kilometraje. El muestreo de conglomerados o áreas, entonces, es útil en situaciones como esta, y se realiza principalmente para la eficiencia de la administración., Tenga en cuenta también que probablemente no tenemos que preocuparnos por usar este enfoque si estamos realizando una encuesta por correo o teléfono porque no importa tanto (o cuesta más o aumenta la ineficiencia) a dónde llamamos o enviamos cartas.
muestreo multietapa
Los cuatro métodos que hemos cubierto hasta ahora-simple, estratificado, sistemático y por conglomerados – son las estrategias de muestreo aleatorio más simples. En la mayoría de la investigación social aplicada real, usaríamos métodos de muestreo que son considerablemente más complejos que estas simples variaciones., El principio más importante aquí es que podemos combinar los métodos simples descritos anteriormente en una variedad de formas útiles que nos ayudan a abordar nuestras necesidades de muestreo de la manera más eficiente y efectiva posible. Cuando combinamos métodos de muestreo, llamamos a esto muestreo de etapas múltiples.
por ejemplo, considere la idea de muestrear a los residentes del Estado de Nueva York para entrevistas cara a cara. Es evidente que querríamos hacer algún tipo de muestreo por conglomerados como primera etapa del proceso. Podríamos muestrear municipios o zonas censales en todo el estado., Pero en el muestreo de conglomerados luego iríamos a medir a todos en los conglomerados que seleccionamos. Incluso si estamos muestreando las secciones del censo, es posible que no podamos medir a todos los que están en las secciones del Censo. Por lo tanto, podríamos establecer un proceso de muestreo estratificado dentro de los grupos. En este caso, tendríamos un proceso de muestreo de dos etapas con muestras estratificadas dentro de muestras de conglomerados. O, considere el problema de muestrear a los estudiantes en las escuelas primarias. Podríamos comenzar con una muestra nacional de distritos escolares estratificados por economía y nivel educativo., Dentro de los distritos seleccionados, podríamos hacer una simple muestra aleatoria de escuelas. Dentro de las escuelas, podríamos hacer una muestra aleatoria simple de clases o calificaciones. Y, dentro de las clases, incluso podríamos hacer una simple muestra aleatoria de estudiantes. En este caso, tenemos tres o cuatro etapas en el proceso de muestreo y utilizamos tanto el muestreo estratificado como el aleatorio simple. Al combinar diferentes métodos de muestreo, podemos lograr una rica variedad de métodos de muestreo probabilísticos que se pueden usar en una amplia gama de contextos de investigación social.