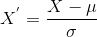Introducción al escalado de características
recientemente trabajé con un conjunto de datos que tenía varias características que abarcaban diversos grados de magnitud, rango y unidades. Este es un obstáculo importante, ya que algunos algoritmos de aprendizaje automático son muy sensibles a estas características.
estoy seguro de que la mayoría de ustedes deben haber enfrentado este problema en sus proyectos o en su viaje de aprendizaje., Por ejemplo, una característica está enteramente en kilogramos mientras que la otra está en gramos, otra es litros, y así sucesivamente. ¿Cómo podemos usar estas características cuando varían tan ampliamente en términos de lo que están presentando?
Aquí es donde recurrí al concepto de escalado de características. Es una parte crucial de la etapa de preprocesamiento de datos, pero he visto que muchos principiantes lo pasan por alto (en detrimento de su modelo de aprendizaje automático).,

esto es lo curioso del escalado de Funciones: Mejora (significativamente) el rendimiento de algunos algoritmos de aprendizaje automático y no funciona en absoluto para otros. ¿Cuál podría ser la razón detrás de esta peculiaridad?
Además, ¿Cuál es la diferencia entre normalización y estandarización? Estas son dos de las técnicas de escalado de características más utilizadas en el aprendizaje automático, pero existe un nivel de ambigüedad en su comprensión. ¿Cuándo debe usar qué técnica?,
responderé estas preguntas y más en este artículo sobre el escalado de funciones. También implementaremos el escalado de funciones en Python para brindarle una comprensión práctica de cómo funciona para diferentes algoritmos de aprendizaje automático.
Nota: asumo que está familiarizado con Python y los Algoritmos de aprendizaje automático del núcleo., Si eres nuevo en esto, te recomiendo seguir los siguientes cursos:
- Python for Data Science
- Todos los Cursos Gratuitos de aprendizaje automático de Analytics Vidhya
- Aprendizaje automático aplicado
tabla de contenidos
- ¿Por qué deberíamos usar el escalado de funciones?
- ¿Qué es la Normalización?
- ¿Qué es la Estandarización?
- La Gran Pregunta – Normalizar o Estandarizar?,
- implementar el escalado de características en Python
- normalización usando Sklearn
- estandarización usando Sklearn
- Aplicar el escalado de características a Algoritmos de aprendizaje automático
- k-nearest Neighbours (KNN)
- Support Vector Regressor
- árbol de decisiones
¿por qué deberíamos usar el escalado de características?
la primera pregunta que necesitamos abordar – ¿por qué necesitamos escalar las variables en nuestro conjunto de datos? Algunos algoritmos de aprendizaje automático son sensibles al escalado de características, mientras que otros son prácticamente invariantes a él., Permítanme explicar esto con más detalle.
algoritmos basados en descenso de gradiente
algoritmos de aprendizaje automático como regresión lineal, regresión logística, red neuronal, etc. que utilizan el descenso de gradiente como técnica de optimización requieren que los datos se escalen. Eche un vistazo a la fórmula para el descenso del gradiente a continuación:

la presencia del valor de entidad X en la fórmula afectará el tamaño del paso del descenso del gradiente. La diferencia en los rangos de entidades causará diferentes tamaños de paso para cada entidad., Para garantizar que el descenso de gradiente se mueve suavemente hacia los mínimos y que los pasos para el descenso de gradiente se actualizan a la misma velocidad para todas las características, escalamos los datos antes de alimentarlos al modelo.
tener características en una escala similar puede ayudar a que el descenso del gradiente converja más rápidamente hacia los mínimos.
los algoritmos basados en la distancia
los Algoritmos de distancia como KNN, K-means y SVM son los más afectados por la gama de características., Esto se debe a que detrás de las escenas están utilizando distancias entre puntos de datos para determinar su similitud.
por ejemplo, digamos que tenemos datos que contienen las puntuaciones CGPA de los estudiantes de secundaria (que van de 0 a 5) y sus ingresos futuros (en miles de rupias):

dado que ambas características tienen diferentes escalas, existe la posibilidad de que se dé una mayor ponderación a las características con mayor magnitud. Esto afectará el rendimiento del algoritmo de aprendizaje automático y, obviamente, no queremos que nuestro algoritmo esté sesgado hacia una característica.,
por lo tanto, escalamos nuestros datos antes de emplear un algoritmo basado en la distancia para que todas las características contribuyan por igual al resultado.,nts A y B, y entre B y C, antes y después del escalado como se muestra a continuación:
- Distance AB before scaling =>

- Distance BC before scaling =>

- distance AB after scaling =>

- distance BC after scaling =>

el escalado ha traído ambas características a la imagen y las distancias ahora son más comparables de lo que eran antes de aplicar el escalado.,
algoritmos basados en árboles
los algoritmos basados en árboles, por otro lado, son bastante insensibles a la escala de las características. Piénselo, un árbol de decisiones solo está dividiendo un nodo en función de una sola entidad. El árbol de decisión divide un nodo en una entidad que aumenta la homogeneidad del nodo. Esta división en una característica no está influenciada por otras características.
por lo tanto, prácticamente no hay efecto de las características restantes en la división. ¡Esto es lo que los hace invariantes a la escala de las características!
¿Qué es la normalización?,
la normalización es una técnica de escalado en la que los valores se desplazan y se reescalan para que terminen oscilando entre 0 y 1. También se conoce como escala Min-Max.
Aquí está la fórmula para la normalización:
Aquí, Xmax y Xmin son los valores máximos y mínimos de la característica respectivamente.,
- Cuando el valor de X es el valor mínimo de la columna, el numerador será 0, y por lo tanto, X’ es 0
- Por otro lado, cuando el valor de X es el valor máximo de la columna, el numerador es igual al denominador y por lo tanto el valor de X’ es 1
- Si el valor de X está entre el mínimo y el valor máximo, entonces el valor de X está entre 0 y 1
¿Qué es la Normalización?
La estandarización es otra técnica de escalado donde los valores se centran alrededor de la media con una desviación estándar unitaria., Esto significa que la media del atributo se convierte en cero y la distribución resultante tiene una desviación estándar unitaria.
Aquí está la fórmula para la estandarización:
es la media de los valores de las funciones y
es la desviación estándar de los valores de la característica. Tenga en cuenta que en este caso, los valores no están restringidos a un rango en particular.
ahora, la gran pregunta en su mente debe ser ¿cuándo debemos usar la normalización y cuándo debemos usar la estandarización? ¡Averigüémoslo!,
La Gran Pregunta – Normalizar o Estandarizar?
la normalización frente a la estandarización es una pregunta eterna entre los recién llegados al aprendizaje automático. Permítanme explayarme sobre la respuesta en esta sección.
- La normalización es buena para usar cuando sabe que la distribución de sus datos no sigue una distribución gaussiana. Esto puede ser útil en algoritmos que no asumen ninguna distribución de los datos como K-vecinos más cercanos y Redes Neuronales.
- La estandarización, por otro lado, puede ser útil en los casos en que los datos siguen una distribución gaussiana., Sin embargo, esto no tiene que ser necesariamente cierto. Además, a diferencia de la normalización, la estandarización no tiene un rango límite. Por lo tanto, incluso si tiene valores atípicos en sus datos, no se verán afectados por la estandarización.
sin embargo, al final del día, la elección de usar normalización o estandarización dependerá de su problema y del algoritmo de aprendizaje automático que esté utilizando. No hay una regla dura y rápida para decirle cuándo normalizar o estandarizar sus datos., Siempre puede comenzar ajustando su modelo a datos sin procesar, normalizados y estandarizados y comparar el rendimiento para obtener los mejores resultados.
es una buena práctica ajustar el escalador en los datos de entrenamiento y luego usarlo para transformar los datos de prueba. Esto evitaría cualquier fuga de datos durante el proceso de prueba del modelo. Además, la escala de los valores objetivo generalmente no es necesaria.
implementar el escalado de funciones en Python
ahora viene la parte divertida: poner en práctica lo que hemos aprendido., Voy a aplicar el escalado de características a algunos algoritmos de aprendizaje automático en el conjunto de datos de Big Mart que he tomado la plataforma DataHack.
saltaré los pasos de preprocesamiento ya que están fuera del alcance de este tutorial. Pero puedes encontrarlos perfectamente explicados en este artículo. Esos pasos le permitirán llegar al percentil 20 superior en la tabla de clasificación hackathon por lo que vale la pena echarle un vistazo!
entonces, primero dividamos nuestros datos en conjuntos de entrenamiento y pruebas:
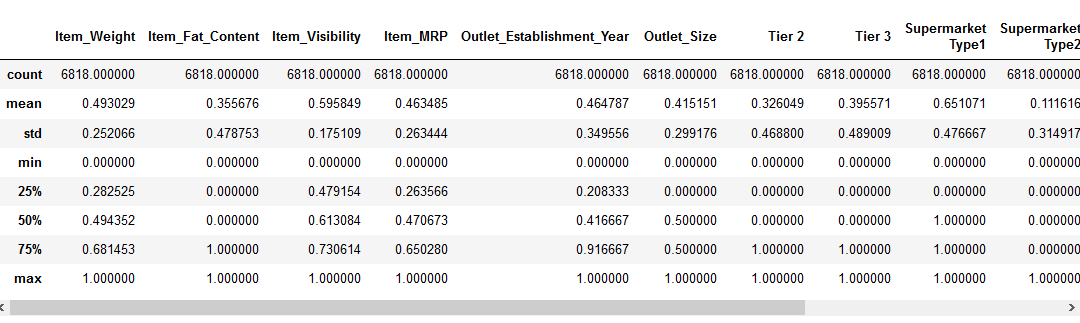
antes de pasar a la parte de escalado de características, echemos un vistazo a los detalles sobre nuestros datos usando el pd.,método describe ():
podemos ver que hay una gran diferencia en el rango de los valores presentes en nuestra numérico características: Item_Visibility, Item_Weight, Item_MRP, y Outlet_Establishment_Year. Vamos a tratar de arreglar que el uso de la función de escalado!
Nota: notará valores negativos en la característica Item_Visibility porque he tomado la transformación de registro para lidiar con la asimetría en la característica.
normalización usando sklearn
para normalizar sus datos, debe importar MinMaxScalar de la biblioteca sklearn y aplicarlo a nuestro conjunto de datos., Así que, vamos a hacer eso!
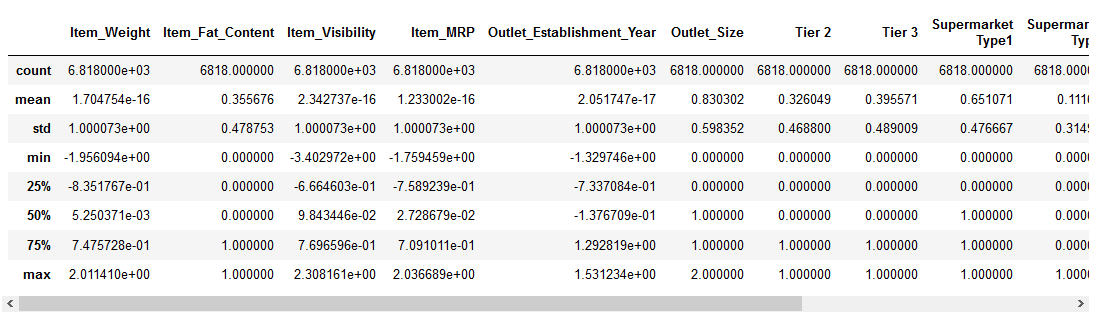
veamos cómo la normalización ha afectado a nuestro conjunto de datos:
todas las características ahora tienen un valor mínimo de 0 y un valor máximo de 1. ¡Perfecto!
pruebe el código anterior en la ventana de live coding a continuación!!
a continuación, intentemos estandarizar nuestros datos.
estandarización usando sklearn
para estandarizar sus datos, debe importar StandardScalar de la biblioteca sklearn y aplicarlo a nuestro conjunto de datos., Así es como puedes hacerlo:
habrás notado que solo apliqué estandarización a mis columnas numéricas y no a las otras características codificadas en caliente. Estandarizar las entidades codificadas One-Hot significaría asignar una distribución a entidades categóricas. ¡No quieres hacer eso!
pero ¿por qué no hice lo mismo mientras normalizaba los datos? Debido a que las entidades codificadas One-Hot ya están en el rango entre 0 y 1. Por lo tanto, la normalización no afectaría su valor.,
bien, echemos un vistazo a cómo la estandarización ha transformado nuestros datos:
las características numéricas ahora se centran en la media con una desviación estándar unitaria. ¡Órale!
comparar datos sin escala, normalizados y estandarizados
siempre es genial visualizar sus datos para comprender la distribución presente. Podemos ver la comparación entre nuestros datos sin escala y escalados usando boxplots.
Puede obtener más información sobre la visualización de datos aquí.,
puede notar cómo escalar las características pone todo en perspectiva. Las características son ahora más comparables y tendrán un efecto similar en los modelos de aprendizaje.
aplicar el escalado a Algoritmos de aprendizaje automático
ahora es el momento de entrenar algunos algoritmos de aprendizaje automático en nuestros datos para comparar los efectos de diferentes técnicas de escalado en el rendimiento del algoritmo. Quiero ver el efecto del escalado en tres algoritmos en particular: K-nearest Neighbours, Support Vector Regressor y Decision Tree.,
K-nearest Neighbours
Como vimos antes, KNN es un algoritmo basado en la distancia que se ve afectado por el rango de características. Veamos cómo funciona en nuestros datos, antes y después del escalado:
puede ver que el escalado de las características ha reducido la puntuación RMSE de nuestro modelo KNN. Específicamente, los datos normalizados funcionan un poco mejor que los datos estandarizados.
Nota: estoy midiendo el RMSE aquí porque esta competencia evalúa el RMSE.
Support Vector Regressor
SVR es otro algoritmo basado en la distancia., Así que vamos a comprobar si funciona mejor con normalización o estandarización:
podemos ver que escalar las características hace bajar la puntuación RMSE. Y los datos estandarizados han funcionado mejor que los datos normalizados. ¿Por qué crees que es así?
la documentación de sklearn indica que SVM, con núcleo RBF, asume que todas las características están centradas alrededor de cero y la varianza es del mismo orden. Esto se debe a que una característica con una varianza mayor que la de otras impide que el estimador aprenda de todas las características., ¡Órale!
Árbol de Decisión
ya sabemos que un árbol de Decisión es invariante a la función de escalado. Pero quería mostrar un ejemplo práctico de cómo funciona en los datos:
puede ver que la puntuación RMSE no se ha movido ni una pulgada en el escalado de las características. Así que tenga la seguridad cuando está utilizando algoritmos basados en árboles en sus datos!,
notas finales
este tutorial cubrió la relevancia de usar el escalado de características en sus datos y cómo la normalización y la estandarización tienen efectos variables en el funcionamiento de los Algoritmos de aprendizaje automático
tenga en cuenta que no hay una respuesta correcta a cuándo usar la normalización sobre la estandarización y viceversa. Todo depende de tus datos y del algoritmo que estés usando.
como siguiente paso, te animo a probar el escalado de funciones con otros algoritmos y descubrir qué funciona mejor: ¿normalización o estandarización?, Le recomiendo que utilice los datos de ventas de BigMart para ese propósito para mantener la continuidad con este artículo. ¡Y no olvides compartir tus ideas en la sección de comentarios a continuación!
Usted también puede leer este artículo en nuestra APLICACIÓN Móvil