Introducción
ordenar los datos significa organizarlos en un orden determinado, a menudo en una estructura de datos similar a una matriz. Puede utilizar varios criterios de Ordenación, los más comunes son ordenar los números de Menor a mayor o viceversa, o ordenar las cadenas lexicográficamente. Incluso puedes definir tus propios criterios, y veremos formas prácticas de hacerlo al final de este artículo.,
si está interesado en cómo funciona la clasificación, cubriremos varios algoritmos, desde soluciones ineficientes pero intuitivas, hasta algoritmos eficientes que realmente se implementan en Java y otros lenguajes.
Hay varios algoritmos de ordenación, y no todos son igualmente eficientes. Analizaremos su complejidad de tiempo para compararlos y ver cuáles funcionan mejor.,
la lista de algoritmos que aprenderá aquí no es exhaustiva, pero hemos compilado algunos de los más comunes y eficientes para ayudarlo a comenzar:
- Bubble Sort
- Insertion Sort
- Selection Sort
- Merge Sort
- Heapsort
- Quicksort
- ordenar en Java
Nota: Este artículo no esté lidiando con la clasificación concurrente, ya que está destinado a principiantes.
Bubble Sort
explicación
Bubble sort funciona intercambiando elementos adyacentes si no están en el orden deseado., Este proceso se repite desde el principio de la matriz hasta que todos los elementos estén en orden.
sabemos que todos los elementos están en orden cuando logramos hacer toda la iteración sin intercambiar en absoluto – entonces todos los elementos que comparamos estaban en el orden deseado con sus elementos adyacentes, y por extensión, toda la matriz.
Estos son los pasos para ordenar una matriz de números de Menor a mayor:
-
4 2 1 5 3: Los dos primeros elementos están en el orden incorrecto, por lo que los intercambiamos.
-
2 4 1 5 3: Los dos segundos elementos también están en el orden equivocado, por lo que intercambiamos.,
-
2 1 4 5 3: Estos dos están en el orden correcto, 4 < 5, así que los deje solos.
-
2 1 4 5 3: otro intercambio.
-
2 1 4 3 5: Aquí está la matriz resultante después de una iteración.
debido a que al menos un swap ocurrió durante la primera pasada (en realidad hubo tres), necesitamos pasar por todo el array de nuevo y repetir el mismo proceso.
repitiendo este proceso, hasta que no se hagan más swaps, tendremos una matriz ordenada.,
la razón por la que este algoritmo se llama Bubble Sort es porque los números tipo de «bubble up» a la » superficie.»Si repasa nuestro ejemplo de nuevo, siguiendo un número en particular (4 es un gran ejemplo), verá que se mueve lentamente hacia la derecha durante el proceso.
todos los números se mueven a sus respectivos lugares poco a poco, de izquierda a derecha, como burbujas que se elevan lentamente desde un cuerpo de agua.
si desea leer un artículo detallado y dedicado para Bubble Sort, ¡lo tenemos cubierto!,
implementación
vamos a implementar Bubble Sort de una manera similar a la que hemos establecido en palabras. Nuestra función entra en un bucle while en el que pasa por todo el intercambio de matrices según sea necesario.
asumimos que la matriz está ordenada, pero si se demuestra que estamos equivocados al ordenar (si ocurre un intercambio), pasamos por otra iteración. El bucle while continúa hasta que logramos pasar a través de toda la matriz sin intercambiar:
al usar este algoritmo tenemos que tener cuidado en cómo declaramos nuestra condición de intercambio.,
por ejemplo, si hubiera usado a >= a podría haber terminado con un bucle infinito, porque para elementos iguales esta relación siempre sería true, y por lo tanto siempre intercambiarlos.
complejidad de tiempo
para averiguar la complejidad de tiempo de la clasificación de burbujas, necesitamos mirar el peor escenario posible. ¿Cuál es el número máximo de veces que necesitamos pasar por toda la matriz antes de ordenarla?, Considere el siguiente ejemplo:
5 4 3 2 1En la primera iteración, 5 «de la burbuja a la superficie,» pero el resto de los elementos que se quedaría en orden descendente. Tendríamos que hacer una iteración para cada elemento excepto 1, y luego otra iteración para comprobar que todo está en orden, por lo que un total de 5 iteraciones.
expanda esto a cualquier matriz de elementos n, y eso significa que debe hacer iteraciones n., Mirando el código, eso significaría que nuestro bucle while puede ejecutar el máximo de n veces.
cada uno de esos n veces que estamos iterando a través de toda la matriz (for-loop en el código), lo que significa que la complejidad de tiempo del peor caso sería O(n^2).
Nota: la complejidad de tiempo siempre sería O(n^2) si no fuera por la comprobación booleana sorted, que termina el algoritmo si no hay ningún swaps dentro del bucle interno, lo que significa que la matriz está ordenada.,
ordenación por inserción
explicación
La idea detrás de ordenación por inserción es dividir la matriz en subarrays ordenados y no clasificados.
la parte ordenada es de longitud 1 al principio y corresponde al primer elemento (más a la izquierda) del array. Iteramos a través de la matriz y durante cada iteración, expandimos la porción ordenada de la matriz por un elemento.
al expandir, colocamos el nuevo elemento en su lugar adecuado dentro del subarray ordenado. Hacemos esto cambiando todos los elementos a la derecha hasta que encontramos el primer elemento que no tenemos que cambiar.,
por ejemplo, si en el siguiente array la parte en negrita se ordena en orden ascendente, ocurre lo siguiente:
-
3 5 7 8 4 2 1 9 6: tomamos 4 y recordamos que eso es lo que necesitamos insertar. Desde 8 > 4, cambiamos.
-
3 5 7 x 8 2 1 9 6: donde el valor de x no es de importancia crucial, ya que se sobrescribirá inmediatamente(ya sea por 4 si es su lugar apropiado o por 7 Si nos desplazamos). Desde 7 > 4, cambiamos.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Después de este proceso, la ordenada parte fue ampliado por un elemento, ahora tenemos cinco en lugar de cuatro elementos. Cada iteración hace esto y al final tendremos toda la matriz ordenada.
si desea leer un artículo detallado y dedicado para ordenar la inserción, ¡lo tenemos cubierto!,
implementación
complejidad temporal
de nuevo, tenemos que mirar el peor de los casos para nuestro algoritmo, y volverá a ser el ejemplo donde toda la matriz es descendente.
esto se debe a que en cada iteración, tendremos que mover toda la lista ordenada por uno, que es O (n). Tenemos que hacer esto para cada elemento en cada matriz, lo que significa que va a estar limitado por O (n^2).
Selection Sort
explicación
Selection Sort también divide la matriz en un subarray ordenado y sin clasificar., Aunque, esta vez, la ordenada subarray está formado por insertar el mínimo elemento de la sin clasificar subarray al final de la matriz ordenada, por intercambio:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Aplicación
En cada iteración, se asume que la primera sin clasificar elemento es el mínimo y recorrer el resto para ver si hay un elemento menor.,
una vez que encontramos el mínimo actual de la parte no ordenada del array, lo intercambiamos con el primer elemento y lo consideramos parte del array ordenado:
Time Complexity
encontrar el mínimo es O(n) para la longitud del array porque tenemos que comprobar todos los elementos. Tenemos que encontrar el mínimo para cada elemento de la matriz, haciendo todo el proceso limitado por O(n^2).,
Merge Sort
explicación
Merge Sort utiliza la recursión para resolver el problema de la ordenación de manera más eficiente que los algoritmos presentados anteriormente, y en particular utiliza un enfoque de divide y vencerás.
Usando ambos conceptos, dividiremos todo el array en dos subarrays y luego:
- ordenar la mitad izquierda del array (recursivamente)
- ordenar la mitad derecha del array (recursivamente)
- fusionar las soluciones
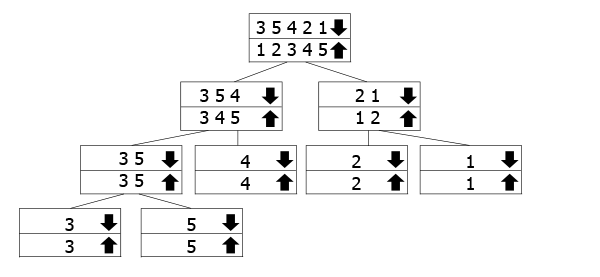
cómo funcionan las llamadas recursivas., Los arrays marcados con la flecha hacia abajo son los que llamamos a la función, mientras que estamos fusionando los de la flecha hacia arriba volviendo hacia arriba. Así que sigue la flecha hacia abajo hasta la parte inferior del árbol, y luego vuelve a subir y fusionar.
En nuestro ejemplo, tenemos la matriz 3 5 3 2 1, por lo que la dividimos en 3 5 4 y 2 1. Para clasificarlos, los dividimos aún más en sus componentes. Una vez que hemos llegado al fondo, empezamos a fusionarlos y ordenarlos a medida que avanzamos.,
si desea leer un artículo detallado y dedicado para Merge Sort, ¡lo tenemos cubierto!
implementación
La función principal funciona más o menos como se describe en la explicación. Solo estamos pasando los índices left y right que son índices del elemento más a la izquierda y más a la derecha del subarray que queremos ordenar. Inicialmente, estos deben ser 0 y array.length-1, dependiendo de la aplicación.,
la base de nuestra recursión garantiza que salgamos cuando hayamos terminado, o cuando righty left se encuentren. Encontramos un punto medio mid, y ordenamos los subarrays izquierda y derecha de él recursivamente, finalmente fusionando nuestras soluciones.
si recuerda nuestro gráfico de árbol, se preguntará por qué no creamos dos nuevas matrices más pequeñas y las pasamos en su lugar. Esto se debe a que en matrices muy largas, esto causaría un gran consumo de memoria para algo que es esencialmente innecesario.,
Merge Sort ya no funciona en el lugar debido al paso de fusión, y esto solo serviría para empeorar su eficiencia de memoria. La lógica de nuestro árbol de recursión de lo contrario permanece igual, sin embargo, solo tenemos que seguir los índices que estamos usando:
para fusionar los subarrays ordenados en uno, necesitaremos calcular la longitud de cada uno y hacer arrays temporales para copiarlos, para que podamos cambiar libremente nuestro array principal.
Después de copiar, vamos a través de la matriz resultante y asignarle el mínimo actual., Debido a que nuestros subarrays están ordenados, solo elegimos el menor de los dos elementos que no se han elegido hasta ahora, y movemos el iterador para ese subarrays hacia adelante:
time Complexity
Si queremos derivar la complejidad de los algoritmos recursivos, vamos a tener que obtener un poco mathy.
El teorema Maestro se utiliza para averiguar la complejidad temporal de los algoritmos recursivos. Para algoritmos no recursivos, usualmente podríamos escribir la complejidad de tiempo precisa como una especie de ecuación, y luego usamos la notación Big-O para ordenarlos en clases de Algoritmos de comportamiento similar.,
el problema con los algoritmos recursivos es que la misma ecuación se vería algo como esto:
t
t (n) = at(\frac{n}{B}) + CN ^ k
!
¡la ecuación en sí es recursiva! En esta ecuación, a nos dice cuántas veces llamamos a la recursión, y b nos dice en cuántas partes está dividido nuestro problema. En este caso puede parecer una distinción sin importancia porque son iguales para mergesort, pero para algunos problemas puede que no lo sean.,
el resto de la ecuación es la complejidad de fusionar todas esas soluciones en una al final., El Teorema Maestro resuelve esta ecuación para nosotros:
t
t(n) = \Bigg\{
\begin{matrix}
O(N^{log_ba}), & a>b^k \\ o(n^klog n), & A = B^K \\ o(n^k), & a < B^K
\end{matrix}
If
If T(n) es tiempo de ejecución del algoritmo al ordenar una matriz de la longitud n, merge sort se ejecutaría dos veces para matrices que tienen la mitad de la longitud de la matriz original.,
Así que si tenemos a=2, b=2. El paso de fusión toma o (n) memoria, por lo que k=1. Esto significa que la ecuación para Merge Sort se vería como sigue:
T
t(n) = 2T(\frac{n}{2})+CN
If
si aplicamos el Teorema maestro, veremos que nuestro caso es el donde a=b^k porque tenemos 2=2^1. Eso significa que nuestra complejidad es O (nlog n). Esta es una complejidad de tiempo extremadamente buena para un algoritmo de Ordenación, ya que se ha demostrado que una matriz no se puede ordenar más rápido que O(nlog n).,
mientras que la versión que hemos mostrado consume memoria, hay versiones más complejas de Merge Sort que ocupan solo O (1) espacio.
Además, el algoritmo es extremadamente fácil de paralelizar, ya que las llamadas recursivas de un nodo se pueden ejecutar de forma completamente independiente desde ramas separadas. Si bien no vamos a entrar en cómo y por qué, ya que está más allá del alcance de este artículo, vale la pena tener en cuenta los pros de usar este algoritmo en particular.,
Heapsort
explicación
para entender correctamente por qué funciona Heapsort, primero debe comprender la estructura en la que se basa: el heap. Estaremos hablando en términos de un montón binario específicamente, pero puede generalizar la mayor parte de esto a otras estructuras de montón también.
un heap es un árbol que satisface la propiedad heap, que es que para cada nodo, todos sus hijos están en una relación dada con él. Además, un montón debe estar casi completo., Un árbol binario casi completo de profundidad d tiene un subárbol de profundidad d-1 con la misma raíz que está completa, y en el que cada nodo con un descendiente izquierdo tiene un subárbol izquierdo completo. En otras palabras, al agregar un nodo, siempre vamos a la posición más a la izquierda en el nivel incompleto más alto.
si el montón es un montón máximo, entonces todos los hijos son más pequeños que el padre, y si es un montón mínimo Todos son más grandes.,
En otras palabras, a medida que se mueve por el árbol, se obtiene números más y más pequeños (min-heap) o números más y más grandes (max-heap). Aquí hay un ejemplo de un max-heap:
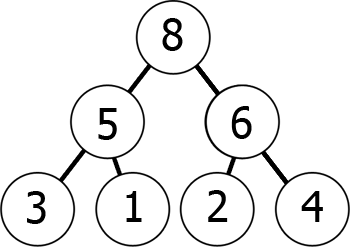
podemos representar este Max-heap en memoria como una matriz de la siguiente manera:
8 5 6 3 1 2 4puede visualizarlo como lectura del gráfico nivel por nivel, de izquierda a derecha., Lo que hemos logrado con esto es que si tomamos el elemento kth en el array, las posiciones de sus hijos son 2*k+1 y 2*k+2 (asumiendo que la indexación comienza en 0). Puedes comprobarlo tú mismo.
por el contrario, para el elemento kth la posición del padre es siempre (k-1)/2.
sabiendo esto, puede fácilmente «Max-heapify» cualquier matriz dada. Para cada elemento, compruebe si alguno de sus hijos es más pequeño que él., Si lo son, intercambia uno de ellos con el padre, y repite recursivamente este paso con el Padre (porque el nuevo elemento grande aún podría ser más grande que su otro hijo).
Las hojas no tienen hijos, por lo que son trivialmente max-heaps propios:
-
6 1 8 3 5 2 4: ambos hijos son más pequeños que el padre, por lo que todo permanece igual.
-
6 1 8 3 5 2 4: debido a que 5 > 1, los intercambiamos. Ahora nos apilamos recursivamente para 5.
-
6 5 8 3 1 2 4: ambos niños son más pequeños, así que no pasa nada.,
-
6 5 8 3 1 2 4: debido a que 8 > 6, los intercambiamos.
-
8 5 6 3 1 2 4: Tenemos el montón de la foto de arriba!
una vez que hemos aprendido a agrupar una matriz, el resto es bastante simple. Intercambiamos la raíz del montón con el final de la matriz, y acortamos la matriz por uno.,
Nos heapify la reducción de la matriz de nuevo, y repetir el proceso:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: intercambiado
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: intercambiado
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: intercambiado
Y así, estoy seguro de que usted puede ver el patrón emergente.
implementación
complejidad de tiempo
Cuando miramos la función heapify(), todo parece hacerse en O(1), pero luego está esa molesta llamada recursiva.,
¿Cuántas veces se llamará a eso, en el peor de los casos? Bueno, en el peor de los casos, se propagará hasta la cima del montón. Lo hará saltando al padre de cada nodo, así que alrededor de la posición i/2. eso significa que hará en el peor de los saltos log n Antes de llegar a la cima, por lo que la complejidad es o(log n).
debido a que heapSort() es claramente O(n) Debido a los bucles for que iteran a través de toda la matriz, esto haría que la complejidad total de Heapsort O (nlog n).,
Heapsort es una ordenación in-place, lo que significa que ocupa O(1) espacio adicional, a diferencia de la ordenación Merge, pero también tiene algunos inconvenientes, como ser difícil de paralelizar.
Quicksort
explicación
Quicksort es otro algoritmo de Divide y vencerás. Elige un elemento de una matriz como pivote y ordena todos los demás elementos a su alrededor, por ejemplo, elementos más pequeños a la izquierda y más grandes a la derecha.
esto garantiza que el pivote está en su lugar adecuado después del proceso., Entonces el algoritmo recursivamente hace lo mismo para las porciones izquierda y derecha de la matriz.
implementación
complejidad de tiempo
la complejidad de tiempo de Quicksort se puede expresar con la siguiente ecuación:
T
t(n) = t(k) + t(n-k-1) + o(n)
el peor de los casos es cuando el elemento más grande o más pequeño siempre se elige para Pivot. La ecuación podría ser algo como esto:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
Este resulta ser O(n^2).,
esto puede sonar mal, ya que ya hemos aprendido varios algoritmos que se ejecutan en O(nlog n) como su peor caso, pero Quicksort es en realidad muy ampliamente utilizado.
esto se debe a que tiene un tiempo de ejecución promedio realmente bueno, también limitado por O (nlog n), y es muy eficiente para una gran parte de las posibles entradas.
una de las razones por las que se prefiere combinar ordenación es que no ocupa espacio adicional, toda la ordenación se realiza en el lugar, y no hay costosas llamadas de asignación y desasignación.,
comparación de rendimiento
dicho esto, a menudo es útil ejecutar todos estos algoritmos en su máquina un par de veces para tener una idea de cómo funcionan.
funcionarán de manera diferente con diferentes colecciones que se están ordenando, por supuesto, pero incluso con eso en mente, debería poder notar algunas tendencias.
vamos a ejecutar todas las implementaciones, una por una, cada una en una copia de una matriz barajada de 10.000 enteros:
evidentemente podemos ver que la ordenación de burbujas es la peor cuando se trata de rendimiento., Evite usarlo en producción si no puede garantizar que manejará solo pequeñas colecciones y no detendrá la aplicación.
HeapSort y QuickSort son los mejores en cuanto a rendimiento. Aunque están produciendo resultados similares, QuickSort tiende a ser un poco mejor y más consistente, lo cual se verifica.
ordenar en Java
interfaz Comparable
Si tiene sus propios tipos, puede ser engorroso implementar un algoritmo de Ordenación separado para cada uno. Es por eso que Java proporciona una interfaz que le permite usar Collections.sort() en sus propias clases.,
para hacer esto, su clase debe implementar la interfaz Comparable<T>, donde T es su tipo, y anular un método llamado .compareTo().
Este método devuelve un entero negativo si this es menor que el argumento del elemento, 0 si son iguales, y un entero positivo si this es mayor.
en nuestro ejemplo, hemos hecho una clase Student, y cada estudiante es identificado por un id y un año comenzaron sus estudios.,
queremos ordenarlos principalmente por generaciones, pero también secundariamente por IDs:
y aquí está cómo usarlo en una aplicación:
salida:
interfaz comparador
es posible que deseemos ordenar nuestros objetos de una manera poco ortodoxa para un propósito específico, pero no queremos implementar eso como el comportamiento predeterminado de nuestra clase, o podríamos estar ordenando una colección de un tipo incorporado de una manera no predeterminada.
para esto, podemos usar la interfaz Comparator., Por ejemplo, tomemos nuestra clase Student y ordenemos solo por ID:
Si reemplazamos la llamada de ordenación en main con lo siguiente:
Arrays.sort(a, new SortByID());salida:
cómo funciona todo
Collection.sort() funciona llamando al método subyacente Arrays.sort(), mientras que la ordenación en sí utiliza el tipo de inserción para matrices más cortas que 47, y quicksort para el resto.,
se basa en una implementación específica de dos pivotes de Quicksort que garantiza que evita la mayoría de las causas típicas de degradación en rendimiento cuadrático, de acuerdo con la documentación JDK10.
conclusión
La ordenación es una operación muy común con conjuntos de datos, ya sea para analizarlos más a fondo, acelerar la búsqueda mediante el uso de algoritmos más eficientes que se basan en los datos que se ordenan, filtrar datos, etc.
La ordenación es soportada por muchos lenguajes y las interfaces a menudo ocultan lo que realmente le está sucediendo al programador., Si bien esta abstracción es bienvenida y necesaria para un trabajo efectivo, a veces puede ser mortal para la eficiencia, y es bueno saber cómo implementar varios algoritmos y estar familiarizado con sus pros y contras, así como cómo acceder fácilmente a implementaciones integradas.