og dens gennemførelse i Python
I denne blog, hvor vi”vil forsøge at grave dybere i den Tilfældige Skov Taksonomi. Her lærer vi om ensemblelæring og vil forsøge at implementere det ved hjælp af Python.,
Du kan finde koden herovre.
det er et ensemble træ-baseret læring algoritme. Random Forest Classifier er et sæt beslutningstræer fra tilfældigt udvalgt undergruppe af træningssæt. Det samler stemmerne fra forskellige beslutningstræer for at bestemme den endelige klasse af testobjektet.
Ensemblealgoritme:
Ensemblealgoritmer er dem, der kombinerer mere end en algoritme af samme eller anden art til klassificering af objekter. For eksempel kører forudsigelse over Naive Bayes, SVM og beslutningstræ og derefter stemmer for endelig overvejelse af klasse for testobjekt.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., De vandrette og lodrette akser af ovenstående beslutning træ udgange kan opfattes som funktioner11 og22. Ved bestemte værdier af hver funktion udsender beslutningstræet en klassificering af” blå”,” grøn”,” rød ” osv.
ovenstående resultater aggregeres gennem modelstemmer eller gennemsnit til en enkelt
ensemble-model, der ender med at overgå ethvert individuelt beslutningstræs output.
funktioner og fordele ved tilfældig Skov:
- det er en af de mest nøjagtige læringsalgoritmer, der er tilgængelige. For mange datasæt producerer det en meget nøjagtig klassificering.,
- det kører effektivt på store databaser.
- det kan håndtere tusindvis af inputvariabler uden variabel sletning.
- det giver skøn over, hvilke variabler der er vigtige i klassificeringen.
- det genererer et internt upartisk skøn over generaliseringsfejlen, når skovbygningen skrider frem.
- det har en effektiv metode til estimering af manglende data og opretholder nøjagtighed, når en stor del af dataene mangler.,
ulemper ved tilfældig Skov:
- tilfældige skove er blevet observeret for overfit for nogle datasæt med støjende klassificerings – / regressionsopgaver.
- for data, herunder kategoriske variabler med forskellige antal niveauer, tilfældige skove er forudindtaget til fordel for disse attributter med flere niveauer. Derfor er de variable betydningsresultater fra tilfældig skov ikke pålidelige for denne type data.,div>
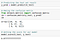
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Vi kiggede på den ensemlede læringsalgoritme i aktion og forsøgte at forstå, hvad der gør tilfældig Skov anderledes end andre maskinlæringsalgoritmer.