introduktion
sortering af data betyder at arrangere det i en bestemt rækkefølge, ofte i en array-lignende datastruktur. Du kan bruge forskellige bestillingskriterier, hvor almindelige sorteres tal fra mindst til størst eller vice versa, eller sortering af strenge leksikografisk. Du kan endda definere dine egne kriterier, og vi vil gå ind i praktiske måder at gøre det ved udgangen af denne artikel.,
Hvis du er interesseret i, hvordan sortering fungerer, dækker vi forskellige algoritmer, fra ineffektive, men intuitive løsninger til effektive algoritmer, der faktisk implementeres på Java og andre sprog.
Der er forskellige sorteringsalgoritmer, og de er ikke alle lige så effektive. Vi analyserer deres tidskompleksitet for at sammenligne dem og se, hvilke der fungerer bedst.,
listen af algoritmer, som du vil lære her, er på ingen måde udtømmende, men vi har samlet nogle af de mest almindelige og mest effektive produkter til at hjælpe dig med at komme i gang:
- Boble Form
- Isætning Form
- Valg Form
- Merge sort
- Heapsort
- Quicksort
- Sortering i Java
Bemærk: Denne artikel vil ikke beskæftige sig med samtidige sortering, da det er beregnet til begyndere.
Bubble Sort
forklaring
Bubble sort fungerer ved at bytte tilstødende elementer, hvis de ikke er i den ønskede rækkefølge., Denne proces gentages fra begyndelsen af arrayet, indtil alle elementer er i orden.
Vi ved, at alle elementer er i orden, når vi formår at udføre hele iterationen uden at bytte overhovedet-så var alle elementer, vi sammenlignede, i den ønskede rækkefølge med deres tilstødende elementer, og i forlængelse heraf hele arrayet.
Her er trinnene til sortering af en række tal fra mindst til størst:
-
4 2 1 5 3: de to første elementer er i forkert rækkefølge, så vi bytter dem.
-
2 4 1 5 3: de to Andet elementer er også i forkert rækkefølge, så vi bytter.,
-
2 1 4 5 3: Disse to er i den rigtige rækkefølge, 4 < 5, så vi lader dem være alene.
-
2 1 4 5 3: En anden s .ap.
-
2 1 4 3 5: Her er det resulterende array efter en iteration.
fordi mindst en s .ap opstod under det første pass (der var faktisk tre), skal vi gennemgå hele arrayet igen og gentage den samme proces.
Ved at gentage denne proces, indtil der ikke er lavet flere S .aps, har vi et sorteret array.,
grunden til denne algoritme kaldes Bubble Sort er fordi tallene slags “boble op” til “overfladen.”Hvis du går gennem vores eksempel igen, efter et bestemt nummer (4 er et godt eksempel), vil du se det langsomt bevæge sig til højre under processen.
alle tal flytter til deres respektive steder bit for bit, venstre mod højre, som bobler, der langsomt stiger op fra en vandmasse.
Hvis du gerne vil læse en detaljeret, dedikeret artikel til Bubble Sort, har vi dig dækket!,
implementering
Vi vil implementere Bubble Sort på en lignende måde, vi har lagt det ud i ord. Vores funktion går ind i et stykke tid loop, hvor det går gennem hele array s .apping efter behov.
Vi antager, at arrayet er sorteret, men hvis vi er bevist forkert under sortering (hvis en s .ap sker), gennemgår vi en anden iteration. Whilehile-loop fortsætter derefter, indtil vi formår at passere gennem hele arrayet uden at bytte:
Når vi bruger denne algoritme, skal vi være forsigtige med, hvordan vi angiver Vores s .aptilstand.,havde brugt a >= a, kunne det have endt med en uendelig løkke, fordi for lige elementer ville denne relation altid være true, og derfor altid bytte dem.
tidskompleksitet
for at finde ud af tidskompleksiteten af boblesortering skal vi se på det værst mulige scenario. Hvad er det maksimale antal gange, vi har brug for at passere gennem hele arrayet, før vi har sorteret det?, Overvej følgende eksempel:
5 4 3 2 1i den første iteration vil 5 “boble op til overfladen”, men resten af elementerne vil forblive i faldende rækkefølge. Vi skulle gøre en iteration for hvert element undtagen 1, og derefter en anden iteration for at kontrollere, at alt er i orden, så i alt 5 iterationer.
Udvid dette til et hvilket som helst array afnelementer, og det betyder, at du skal gøren iterationer., Ser man på koden, ville det betyde, at vores while loop kan køre maksimaltn gange.
hver af disse n gange vi itererer gennem hele arrayet(for-loop i koden), hvilket betyder, at den værste tidskompleksitet ville være o (n^2).Bemærk: tidskompleksiteten ville altid være o (n^2), hvis det ikke var for sorted boolean check, som afslutter algoritmen, hvis der ikke er nogen s .aps i den indre sløjfe – hvilket betyder, at arrayet er sorteret.,
Insertion Sort
forklaring
ideen bag Insertion Sort er at opdele arrayet i de sorterede og usorterede subarrays.
den sorterede del er af længde 1 i begyndelsen og svarer til det første (venstre mest) element i arrayet. Vi gentager gennem arrayet og under hver iteration udvider vi den sorterede del af arrayet med et element.
Når vi udvider, placerer vi det nye element på dets rette sted inden for det sorterede subarray. Vi gør dette ved at flytte alle elementerne til højre, indtil vi støder på det første element, vi ikke behøver at skifte.,
for eksempel, hvis den fedtede del i den følgende array sorteres i stigende rækkefølge, sker følgende:
-
3 5 7 8 4 2 1 9 6: Vi tager 4 og husk at det er det, vi skal indsætte. Siden 8 > 4 skifter vi.
-
3 5 7 8 8 2 1 9 6: hvor værdien af.ikke er af afgørende betydning, da den vil blive overskrevet med det samme (enten med 4, hvis det er dets passende sted eller med 7, hvis vi skifter). Siden 7 > 4 skifter vi.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Efter denne proces, den sorterede del blev udvidet med et element, vi har nu fem i stedet for fire elementer. Hver iteration gør dette, og i slutningen har vi hele arrayet sorteret.
Hvis du gerne vil læse en detaljeret, dedikeret artikel til indsættelsessortering, har vi dig dækket!,
implementering
tidskompleksitet
igen skal vi se på det værste tilfælde for vores algoritme, og det vil igen være eksemplet, hvor hele arrayet er faldende.
dette skyldes, at vi i hver iteration skal flytte hele sorteret listen efter en, som er o(n). Vi skal gøre dette for hvert element i hvert array, hvilket betyder, at det vil blive afgrænset af O(n^2).
Selection Sort
forklaring
Selection Sort opdeler også arrayet i en sorteret og usorteret subarray., Dog, denne gang, sorteret subarray er dannet ved at indsætte det mindste element i den usorterede subarray i slutningen af sorteret array, ved at bytte:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Gennemførelsen
I hver iteration, antager vi, at den første usorteret element er den mindste og kør gennem resten for at se, om der er et mindre element.,
Når vi finder det nuværende minimum af usorteret en del af de mange, vi bytte den ud med det første element, og betragter det som en del af den sorterede array ‘ et:
Tid Kompleksitet
Finde den mindste er O(n) for længden af array, fordi vi er nødt til at kontrollere alle elementer. Vi skal finde minimumet for hvert element i arrayet, hvilket gør hele processen afgrænset af O(n^2).,
Merge Sort
forklaring
Merge Sort bruger rekursion til at løse problemet med sortering mere effektivt end algoritmer, der tidligere blev præsenteret, og især bruger den en kløft og erobre tilgang.
ved Hjælp af begge disse begreber, vil vi bryde hele rækken ned til to subarrays og derefter:
- Sortér venstre halvdel af det array (rekursivt)
- Sortér højre halvdel af array (rekursivt)
- Flette løsninger
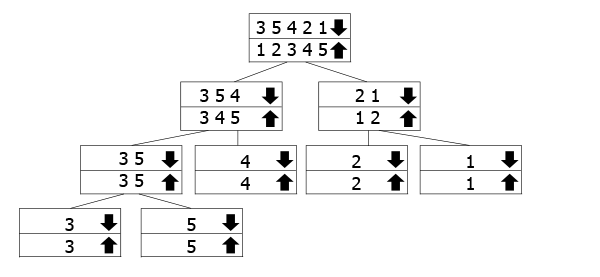
Dette træ er beregnet til at repræsentere, hvordan de rekursive kald arbejde., De arrays, der er markeret med pil ned, er dem, vi kalder funktionen for, mens vi fusionerer pil op, der går op igen. Så du følger Pil ned til bunden af træet, og derefter gå op igen og fusionere.
I vores eksempel, har vi array 3 5 3 2 1, så vi deler det ind i 3 5 4 og 2 1. For at sortere dem deler vi dem yderligere i deres komponenter. Når vi har nået bunden, begynder vi at slå sammen og sortere dem, mens vi går.,
Hvis du gerne vil læse en detaljeret, dedikeret artikel til Merge Sort, har vi dig dækket!
implementering
kernefunktionen fungerer stort set som beskrevet i forklaringen. Vi passerer bare indekser left og right, som er indekser for det venstre og højre element i det subarray, vi vil sortere. Oprindeligt bør disse være 0 og array.length-1, afhængigt af implementeringen.,basen af vores rekursion sikrer, at vi afslutter, når vi er færdige, eller når right og left møder hinanden. Vi finder et midtpunkt mid, og sorterer subarrays venstre og højre for det rekursivt, i sidste ende fusionerer vores løsninger.
Hvis du husker vores trægrafik, kan du undre dig over, hvorfor vi ikke opretter to nye mindre arrays og videregiver dem i stedet. Dette skyldes, at det på virkelig lange arrays ville medføre stort hukommelsesforbrug for noget, der i det væsentlige er unødvendigt.,
Flet Sort fungerer allerede ikke på stedet på grund af fusionstrinnet, og dette ville kun tjene til at forværre dets hukommelseseffektivitet. Logikken i vores træ af rekursion ellers forbliver den samme, selv, vi bare nødt til at følge indekser vi bruger:
for At fusionere sorteret subarrays til én, vi bliver nødt til at beregne længden af hver og lave midlertidige arrays til at kopiere dem ind, så vi kunne frit ændre vores vigtigste array.
efter kopiering går vi gennem det resulterende array og tildeler det det aktuelle minimum., Fordi vores subarrays er sorteret, valgte vi bare det mindste af de to elementer, der ikke er valgt hidtil, og flytter iteratoren for det subarray fremad:
tidskompleksitet
Hvis vi ønsker at udlede kompleksiteten af rekursive algoritmer, bliver vi nødt til at blive lidt matematiske.
Master Theorem bruges til at finde ud af tidskompleksiteten af rekursive algoritmer. For ikke-rekursive algoritmer kunne vi normalt skrive den præcise tidskompleksitet som en slags ligning, og så bruger vi Big-O Notation til at sortere dem i klasser af lignende opfører algoritmer.,
problemet med rekursive algoritmer er, at den samme ligning ville se sådan ud:
$$
t(n) = at(\frac{n}{b}) + cn^K
$$
selve ligningen er rekursiv! I denne ligning fortæller a os, hvor mange gange vi kalder rekursionen, ogb fortæller os, hvor mange dele vores problem er opdelt. I dette tilfælde kan det virke som en ubetydelig forskel, fordi de er lige for mergesort, men for nogle problemer kan de ikke være.,
resten af ligningen er kompleksiteten ved at flette alle disse løsninger til en i slutningen., Master Theorem løser denne ligning for os:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Hvis T(n) er runtime af den algoritme, når du sorterer et array af længde n Merge sort ville køre to gange for arrays, der er halvdelen af længden af den oprindelige array.,
Så hvis vi har a=2 b=2. Fusionstrinnet tager o(n) hukommelse, så k=1. Dette betyder, at ligningen for Merge sort ville se ud som følger:
$$
T(n) = 2T(\frac{n}{2})+cn
$$
Hvis vi anvender Master Theorem, vi vil se, at vores sag er den ene, hvor a=b^k fordi vi har 2=2^1. Det betyder, at vores kompleksitet er o (nlog n). Dette er en ekstremt god tidskompleksitet for en sorteringsalgoritme, da det er bevist, at et array ikke kan sorteres hurtigere end O(nlog n).,
mens den version, vi har fremvist, er hukommelsesforbrugende, er der mere komplekse versioner af Merge Sort, der kun optager o(1) plads.
derudover er algoritmen ekstremt let at parallelisere, da rekursive opkald fra en knude kan køres helt uafhængigt af separate grene. Selvom vi ikke kommer ind på hvordan og hvorfor, da det er uden for rammerne af denne artikel, er det værd at huske på fordelene ved at bruge denne særlige algoritme.,
Heapsort
forklaring
for korrekt at forstå, hvorfor Heapsort fungerer, skal du først forstå strukturen, den er baseret på – the heap. Vi vil tale i form af en binær bunke specifikt, men du kan generalisere det meste af dette til andre bunke strukturer samt.
en bunke er et træ, der tilfredsstiller bunkeegenskaben, hvilket er, at for hver knude er alle dets børn i et givet forhold til det. Derudover skal en bunke være næsten komplet., En næsten komplet binært træ af dybde d har et undertræ af dybde d-1 med den samme rod, der er komplette, og hvor hver node med en venstre efterkommer er en komplet venstre undertræ. Med andre ord, når vi tilføjer en knude, går vi altid til venstre for det højeste ufuldstændige niveau.
Hvis dyngen er en ma.-bunke, så alle børnene er mindre end den forælder, og hvis det er en min-bunke alle af dem er større.,
med andre ord, når du bevæger dig ned i træet, kommer du til mindre og mindre tal (min-bunke) eller større og større tal (ma.-bunke). Her er et eksempel på en max-heap:
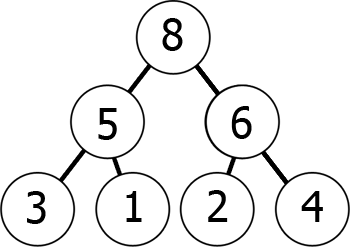
Vi kan repræsentere denne max-heap i hukommelsen som en vifte på følgende måde:
8 5 6 3 1 2 4Du kan forestille dig det som at læse fra grafen niveau efter niveau, fra venstre til højre., Det, vi har opnået med dette er, at hvis vi tager kth – element i arrayet, sine børns holdninger er 2*k+1 og 2*k+2 (forudsat at den indeksering, der starter ved 0). Du kan tjekke dette for dig selv.
omvendt, forkth elementet er forældrenes position altid(k-1)/2.når du kender dette, kan du nemt “ma.-heapify” et givet array. For hvert element skal du kontrollere, om nogen af dens børn er mindre end det., Hvis de er, skal du bytte en af dem med forælderen og gentage dette trin rekursivt med forælderen (fordi det nye store element stadig kan være større end dets andet barn).
Blade har ingen børn, så de er trivielt max-heaps for deres egne:
-
6 1 8 3 5 2 4: Begge børn er mindre end den forælder, så alt forbliver den samme.
-
6 1 8 3 5 2 4: fordi 5> 1, bytter vi dem. Vi rekursivt heapify for 5 Nu.
-
6 5 8 3 1 2 4: begge børn er mindre, så der sker ikke noget.,
-
6 5 8 3 1 2 4: fordi 8> 6, bytter vi dem.
-
8 5 6 3 1 2 4: vi fik bunken afbildet ovenfor!
Når vi har lært at heapify et array resten er ret simpelt. Vi bytter roden af bunken med enden af arrayet og forkorter arrayet med en.,
Vi heapify den forkortede array igen, og gentag processen:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: byttes
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: byttes
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: byttes
Og så videre, er jeg sikker på, at du kan se det mønster, som dukker op.
implementering
tidskompleksitet
Når vi ser påheapify() – funktionen, ser alt ud til at ske i o(1), men så er der det irriterende rekursive opkald.,
hvor mange gange vil det blive kaldt, i værste fald? Nå, i værste fald vil den formere sig helt til toppen af bunken. Det vil gøre det ved at hoppe til forælderen til hver knude, så omkring positionen i/2. det betyder, at det i værste fald vil gøre log n hopper, før den når toppen, så kompleksiteten er o(log n).
Fordi heapSort() er klart O(n) på grund af for-løkker iterere gennem hele arrayet, vil det gøre den samlede kompleksitet af Heapsort O(nlog n).,
Heapsort er en in-place sort, hvilket betyder at det tager o(1) ekstra plads, i modsætning til flette Sort, men det har også nogle ulemper, som f.eks.
Quickuicksort
forklaring
Quickuicksort er en anden kløft og erobre algoritme. Det vælger et element i et array som omdrejningspunkt og sorterer alle de andre elementer omkring det, for eksempel mindre elementer til venstre, og større til højre.
dette garanterer, at pivoten er på sit rette sted efter processen., Derefter gør algoritmen rekursivt det samme for venstre og højre del af arrayet.
Gennemførelsen
Tid Kompleksitet
Den tid, kompleksitet af Quicksort kan udtrykkes med følgende ligning:
$$
T(n) = T(k)) + T(n-k-1) + O(n)
$$
Det værst tænkelige scenarie er, når den største eller mindste element er altid plukket til pivot. Ligningen vil så se sådan ud:
$$
t(n) = T(0) + T(n-1) + o(n) = T(n-1) + o(n)
$$
Dette viser sig at være O(n^2).,
dette kan lyde dårligt, da vi allerede har lært flere algoritmer, der kører i O(nlog n) tid som deres værste tilfælde, men Quickuicksort er faktisk meget udbredt.dette skyldes, at det har en rigtig god gennemsnitlig runtime, også afgrænset af O(nlog n), og er meget effektiv til en stor del af mulige input.
en af grundene til, at det foretrækkes at flette sortering, er, at det ikke tager ekstra plads, al sorteringen udføres på stedet, og der er ingen dyre allokerings-og deallokeringsopkald.,
Præstationssammenligning
når det er sagt, er det ofte nyttigt at køre alle disse algoritmer på din maskine et par gange for at få en ID.om, hvordan de udfører.
de vil udføre forskelligt med forskellige samlinger, der bliver sorteret selvfølgelig, men selv med det i tankerne, bør du være i stand til at lægge mærke til nogle tendenser.
lad os køre alle implementeringer, en efter en, hver på en kopi af et blandet array på 10.000 heltal:
Vi kan åbenbart se, at Bubble Sort er det værste, når det kommer til ydeevne., Undgå at bruge det i produktion, hvis du ikke kan garantere, at det kun håndterer små samlinger, og det vil ikke stoppe applikationen.
HeapSort og Quickuicksort er de bedste performance-wiseise. Selvom de udsender lignende resultater, har Quickuicksort en tendens til at være lidt bedre og mere konsekvent – hvilket tjekker.
sortering i Java
sammenlignelig grænseflade
Hvis du har dine egne typer, kan det blive besværligt at implementere en separat sorteringsalgoritme for hver enkelt. Derfor giver Java En grænseflade, der giver dig mulighed for at bruge Collections.sort() på dine egne klasser.,
for At gøre dette, kan din klasse skal gennemføre Comparable<T> interface, hvor T er din type, og tilsidesætte en metode, der kaldes .compareTo().
Denne metode returnerer et negativt heltal, hvis this er mindre end argumentet element, 0, hvis de er ens, og et positivt heltal, hvis this er større.
I vores eksempel, har vi lavet en klasse Student, og hver studerende er identificeret ved en id og et år, de begyndte deres studier.,
Vi ønsker at sortere dem primært af generationer, men også sekundært ved id ‘ er:
Og her er hvordan du bruger det i en ansøgning:
Output:
Komparator Interface
Vi vil måske ønske at sortere vores objekter i en uortodokse måde til et bestemt formål, men vi ønsker ikke at gennemføre det, som den standard opførsel af vores klasse, eller vi kan være sortering af en samling af en indbygget type i en ikke-standard måde.
til dette kan vi bruge Comparator interface., For eksempel, lad os tage vores Student class, og sortér efter ID:
Hvis vi erstatter den slags opkald i main med følgende:
Arrays.sort(a, new SortByID());Output:
Hvordan det Hele Fungerer
Collection.sort() virker ved at kalde den underliggende Arrays.sort() metode, mens sorteringen i sig selv bruger Indsættelse Form for arrays, der er kortere end 47, og Quicksort for resten.,
det er baseret på en specifik to-pivot implementering af Quickuicksort, som sikrer, at det undgår de fleste af de typiske årsager til nedbrydning til kvadratisk ydeevne, ifølge jdk10 dokumentationen.
konklusion
sortering er en meget almindelig operation med datasæt, hvad enten det er at analysere dem yderligere, fremskynde søgningen ved hjælp af mere effektive algoritmer, der er afhængige af de data, der sorteres, filtrerer data osv.
sortering understøttes af mange sprog, og grænsefladerne skjuler ofte, hvad der faktisk sker med programmereren., Selvom denne abstraktion er velkommen og nødvendig for effektivt arbejde, kan det undertiden være dødbringende for effektivitet, og det er godt at vide, hvordan man implementerer forskellige algoritmer og er bekendt med deres fordele og ulemper, samt hvordan man let får adgang til indbyggede implementeringer.