en sandsynlighedsprøvetagningsmetode er enhver prøveudtagningsmetode, der anvender en form for tilfældigt valg. For at have en tilfældig udvælgelsesmetode skal du oprette en proces eller procedure, der sikrer, at de forskellige enheder i din befolkning har lige sandsynligheder for at blive valgt. Mennesker har længe praktiseret forskellige former for tilfældigt valg, såsom at vælge et navn ud af en hat eller vælge det korte strå. Disse dage har vi en tendens til at bruge computere som mekanismen til at generere tilfældige tal som grundlag for tilfældigt valg.,
nogle definitioner
før jeg kan forklare de forskellige sandsynlighedsmetoder, skal vi definere nogle grundlæggende udtryk. Disse er:
-
Ner antallet af sager i stikprøvegrundlaget -
ner antallet af sager i stikprøven -
NCn= antallet af kombinationer (delmængder) afnfraN -
f = n/Nprøveudtagning brøkdel
det er det., Med disse definerede udtryk kan vi begynde at definere de forskellige sandsynlighedsprøvetagningsmetoder.
enkel tilfældig prøveudtagning
den enkleste form for tilfældig prøveudtagning kaldes simpel tilfældig prøveudtagning. Temmelig vanskelig, hva’? Her er en hurtig beskrivelse af simpel tilfældig sampling:
- Formål: At vælge
nenheder ud afNsådan, at hvertNCnhar en lige chance for at blive valgt. - Procedure: Brug en tabel med tilfældige tal, en computer random number generator eller en mekanisk enhed til at vælge prøven.,
en noget opstyltet, hvis nøjagtig, definition. Lad os se, om vi kan gøre det lidt mere virkeligt.

hvordan vælger vi en simpel tilfældig prøve? Lad os antage, at vi gør nogle forskning med en lille service agentur, der ønsker at vurdere kundernes syn på kvaliteten af service i det forløbne år. Først skal vi få samplingsrammen organiseret. For at opnå dette gennemgår vi agenturregistre for at identificere hver klient i løbet af de sidste 12 måneder. Hvis vi er heldige, agenturet har gode nøjagtige edb-poster og kan hurtigt producere en sådan liste., Derefter skal vi faktisk tegne prøven. Beslut om antallet af klienter, du gerne vil have i den endelige prøve. Af hensyn til eksemplet, lad os sige, at du vil vælge 100 klienter, der skal undersøges, og at der var 1000 klienter i løbet af de sidste 12 måneder. Derefter er prøveudtagningsfraktionen f = n/N = 100/1000 = .10 (eller 10%). Nu, for faktisk at tegne prøven, har du flere muligheder. Du kan udskrive listen over 1000 klienter, rive derefter i separate strimler, læg strimlerne i en hat, bland dem rigtig godt, luk øjnene og træk de første 100 ud., Men denne mekaniske procedure ville være kedelig, og kvaliteten af prøven afhænger af, hvor grundigt du blandede dem op, og hvor tilfældigt du nåede ind. Måske en bedre procedure ville være at bruge den slags bold maskine, der er populær hos mange af de statslige lotterier. Du ville har brug for tre sæt af bolde nummereret fra 0 til 9, et sæt til hver af cifre fra 000 til 999 (hvis vi vælger 000 vi vil ringe til, at 1000)., Nummer listen over navne fra 1 til 1000 og brug derefter kuglemaskinen til at vælge de tre cifre, der vælger hver person. Den indlysende ulempe her er, at du skal få boldmaskinerne. (Hvor laver de disse ting alligevel? Er der en bold maskine industri?).
ingen af disse mekaniske procedurer er meget gennemførlige, og med udviklingen af billige computere er der en meget lettere måde. Her er en simpel procedure, der er især nyttig, hvis du har navnene på klienterne allerede på computeren., Mange computerprogrammer kan generere en række tilfældige tal. Lad os antage, at du kan kopiere og indsætte listen over klientnavne i en kolonne i et e .cel-regneark. Derefter, i kolonnen til højre ved siden af indsæt-funktionen =RAND() hvilket er EXCEL ‘ s måde at sætte et tilfældigt tal mellem 0 og 1 i cellerne. Sorter derefter begge kolonner – listen over navne og det tilfældige tal-efter de tilfældige tal. Dette omarrangerer listen i tilfældig rækkefølge fra det laveste til det højeste tilfældige tal., Derefter, alt hvad du skal gøre er at tage de første hundrede navne i denne sorterede liste. ret simpelt. Du kunne sandsynligvis opnå det hele på under et minut.
enkel tilfældig prøveudtagning er enkel at udføre og er let at forklare for andre. Da simpel tilfældig prøveudtagning er en retfærdig måde at vælge en prøve på, er det rimeligt at generalisere resultaterne fra prøven tilbage til befolkningen. Enkel tilfældig prøveudtagning er ikke den mest statistisk effektive metode til prøveudtagning, og du kan, bare på grund af heldet, ikke få en god repræsentation af undergrupper i en befolkning., For at løse disse problemer skal vi henvende os til andre prøveudtagningsmetoder.
stratificeret tilfældig prøveudtagning
stratificeret tilfældig prøveudtagning, også undertiden kaldet proportional eller kvote tilfældig prøveudtagning, indebærer at opdele din population i homogene undergrupper og derefter tage en simpel tilfældig prøve i hver undergruppe. Mere formelt:
Der er flere hovedårsager til, at du måske foretrækker stratificeret prøveudtagning frem for simpel tilfældig prøveudtagning., For det første sikrer det, at du ikke kun vil repræsentere den samlede befolkning, men også centrale undergrupper af befolkningen, især små minoritetsgrupper. Hvis du vil være i stand til at tale om undergrupper, kan dette være den eneste måde at effektivt forsikre dig om, at du kan. Hvis undergruppen er ekstremt lille, kan du bruge forskellige prøveudtagningsfraktioner (f) inden for de forskellige lag til tilfældigt at overprøve den lille gruppe (selvom du derefter skal vægte estimaterne inden for gruppen ved hjælp af prøveudtagningsfraktionen, når du vil have samlede befolkningsestimater)., Når vi bruger den samme prøveudtagningsfraktion inden for lag, foretager vi forholdsmæssigt stratificeret stikprøveudtagning. Når vi bruger forskellige prøveudtagningsfraktioner i lagene, kalder vi denne uforholdsmæssige stratificerede stikprøveudtagning. For det andet vil stratificeret stikprøveudtagning generelt have mere statistisk præcision end simpel stikprøveudtagning. Dette vil kun være tilfældet, hvis lagene eller grupperne er homogene. Hvis de er, forventer vi, at variabiliteten inden for grupper er lavere end variabiliteten for befolkningen som helhed. Stratificeret prøveudtagning udnytter denne kendsgerning.,
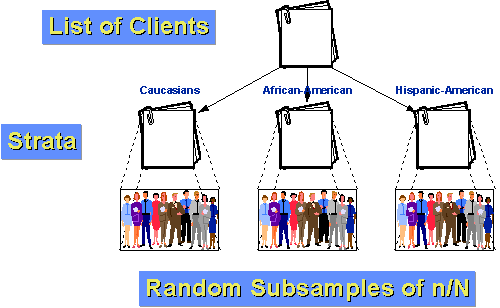
lad os for eksempel sige, at befolkningen af klienter til vores agentur kan opdeles i tre grupper: kaukasisk, afroamerikansk og latinamerikansk-Amerikansk. Lad os desuden antage, at både afroamerikanere og latinamerikanske amerikanere er relativt små minoriteter af klientellet (10% og5% henholdsvis)., Hvis vi bare en simpel tilfældig stikprøve af n=100 med en sampling brøkdel af 10%, som vi ville forvente ved en tilfældighed alene, at vi kun ville få 10 og 5 personer fra hver af vores to mindre grupper. Og ved en tilfældighed kunne vi få færre end det! Hvis vi stratificerer, kan vi gøre det bedre. Lad os først bestemme, hvor mange mennesker vi vil have i hver gruppe. Lad os sige, at vi stadig ønsker at tage en stikprøve på 100 fra befolkningen på 1000 klienter i det forløbne år. Men vi mener, at for at sige noget om undergrupper, har vi brug for mindst 25 tilfælde i hver gruppe., Så lad os prøve 50 kaukasiere, 25 afroamerikanere og 25 latinamerikanske amerikanere. Vi ved, at 10% af befolkningen, eller 100 kunder, er afroamerikanske. Hvis vi tilfældigt prøver 25 af disse, har vi en prøveudtagningsfraktion inden for stratum på 25/100 = 25%. Tilsvarende ved vi, at 5% eller 50 kunder er spansktalende-Amerikanske. Så vores prøvetagningsfraktion inden for stratum vil være 25/50 = 50%. Endelig ved subtraktion ved vi, at der er 850 kaukasiske klienter. Vores prøveudtagningsfraktion inden for stratum for dem er 50/850 = about 5.88%., Fordi grupperne er mere homogene inden for gruppen end på tværs af befolkningen som helhed, kan vi forvente større statistisk præcision (mindre varians). Og, fordi vi stratificeret, vi ved, at vi vil have nok sager fra hver gruppe til at gøre meningsfulde undergruppe slutninger.,e er de trin, du skal følge for at opnå en systematisk stikprøve:
- antallet af enheder i populationen fra
1tilN - træffe afgørelse om
n(stikprøve) at du ønsker eller har brug for -
k = N/n= intervallet størrelse - tilfældigt vælge et heltal mellem
1tilk - tag derefter hvert
kthenhed

Alt dette vil være meget tydeligere med et eksempel., Lad os antage, at vi har en befolkning, der kun har n=100 mennesker i det, og at du vil tage en prøve af n=20. For at anvende systematisk prøveudtagning skal befolkningen opføres i tilfældig rækkefølge. Prøveudtagningsfraktionen ville være f = 20/100 = 20%. i dette tilfælde er intervallstørrelsen, k, lig med N/n = 100/20 = 5. Vælg nu et tilfældigt heltal fra 1 to 5. Forestil dig i vores eksempel, at du valgte 4., Nu, for at vælge den prøve, der starter med 4th enhed på listen, og tage hvert k-th enhed (hver 5., fordi k=5). Du ville være sampling enheder 4, 9, 14, 19, og så videre til 100, og du ville ende med 20 enheder i din prøve.
for at dette skal fungere, er det vigtigt, at enhederne i befolkningen bestilles tilfældigt, i det mindste med hensyn til de egenskaber, du måler. Hvorfor vil du nogensinde bruge systematisk tilfældig prøveudtagning? For det første er det ret nemt at gøre. Du skal kun vælge et enkelt tilfældigt tal for at starte tingene., Det kan også være mere præcist end simpel stikprøveudtagning. Endelig er der i nogle situationer simpelthen ingen nemmere måde at gøre tilfældig prøveudtagning på. For eksempel var jeg engang nødt til at lave en undersøgelse, der involverede prøveudtagning fra alle bøgerne i et bibliotek. Når det er valgt, bliver jeg nødt til at gå til hylden, finde bogen og registrere, hvornår den sidst cirkulerede. Jeg vidste, at jeg havde en ret god samplingsramme i form af hyldelisten (som er et kortkatalog, hvor posterne er arrangeret i den rækkefølge, de forekommer på hylden)., For at lave en simpel tilfældig prøve kunne jeg have estimeret det samlede antal bøger og genereret tilfældige tal for at tegne prøven; men hvordan ville jeg finde bog #74,329 let, hvis det er det nummer, jeg valgte? Jeg kunne ikke så godt tælle kortene, før jeg kom til 74,329! Stratificering ville heller ikke løse dette problem. For eksempel kunne jeg have stratificeret ved kortkatalogskuffe og tegnet en simpel tilfældig prøve inden for hver skuffe. Men jeg ville stadig sidde fast med at tælle kort. I stedet lavede jeg en systematisk tilfældig prøve. Jeg estimerede antallet af bøger i hele samlingen. Lad os forestille os, at det var 100.000., Jeg besluttede, at jeg ville tage en prøve på 1000 for en prøveudtagningsfraktion af 1000/100,000 = 1%. For at få samplingsintervallet k, delte jeg N/n = 100,000/1000 = 100. Derefter valgte jeg et tilfældigt heltal mellem 1 og 100. Lad os sige, at jeg fik 57.
dernæst lavede jeg en lille sideundersøgelse for at bestemme, hvor tyk tusind kort er i kortkataloget (under hensyntagen til kortets forskellige aldre)., Lad os sige, at jeg i gennemsnit fandt, at to kort, der blev adskilt af 100 kort var omkring .75 tommer fra hinanden i katalogskuffen. Disse oplysninger gav mig alt, hvad jeg havde brug for for at tegne prøven. Jeg tællede til den 57. for hånd og registrerede bogoplysningerne. Så tog jeg et kompas. (Husk dem fra din gymnasium matematik klasse? De er de sjove små metalinstrumenter med en skarp pin i den ene ende og en blyant på den anden, som du plejede at tegne cirkler i geometri klasse.,) Derefter satte jeg kompasset på .75", stak stiften i på det 57. kort og pegede med blyantenden til det næste kort (cirka 100 bøger væk). På denne måde tilnærmede jeg valget af 157., 257., 357. og så videre. Jeg var i stand til at udføre hele udvælgelsesproceduren på meget lidt tid ved hjælp af denne systematiske tilfældige prøveudtagningsmetode. Jeg ville nok stadig være der tælle kort, hvis jeg havde prøvet en anden tilfældig prøveudtagningsmetode. (Okay, så jeg har ikke noget liv. Jeg fik kompenseret pænt, jeg har ikke noget imod at sige, for at komme med denne ordning.,)
klynge (område) tilfældig prøveudtagning
problemet med tilfældige prøveudtagningsmetoder, når vi skal prøve en befolkning, der udbetales i en bred geografisk region, er, at du bliver nødt til at dække en masse jord geografisk for at komme til hver af de enheder, du samplede. Forestil dig at tage en simpel tilfældig prøve af alle beboere i Ne.York State for at gennemføre personlige intervie .s. Ved held i lodtrækningen vil du ende med respondenter, der kommer fra hele staten. Dine intervie .ere vil have en masse rejser at gøre., Det er netop for dette problem, at klynge eller område tilfældig prøveudtagning blev opfundet.
cluster sampling, vi ved at følge disse trin:
- opdele populationen i klynger (som regel sammen geografiske grænser)
- tilfældigt udsnit klynger
- måle alle enheder i stikprøven klynger
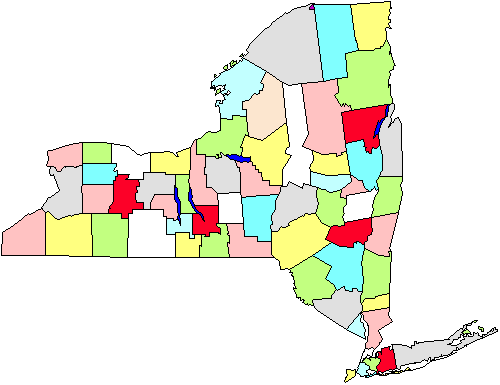
For eksempel, i figuren ser vi et kort af amter i Staten New York. Lad os sige, at vi er nødt til at foretage en undersøgelse af byregeringer, der kræver, at vi personligt går til byerne., Hvis vi laver en simpel tilfældig stikprøve, skal vi dække hele staten geografisk. I stedet, vi beslutter at gøre en klynge prøveudtagning af fem amter (markeret med rødt i figuren). Når disse er valgt, vi går til hver By regering i de fem områder. Det er klart, at denne strategi vil hjælpe os med at spare på vores kilometertal. Klynge-eller områdeudtagning er derefter nyttig i situationer som denne og udføres primært for effektiviteten af administrationen., Bemærk også, at vi sandsynligvis ikke behøver at bekymre os om at bruge denne tilgang, hvis vi udfører en mail-eller telefonundersøgelse, fordi det ikke betyder noget så meget (eller koster mere eller øger ineffektiviteten), hvor vi ringer eller sender breve til.
Flertrinsprøvetagning
de fire metoder, vi hidtil har dækket-enkle, stratificerede, systematiske og klynge – er de enkleste stikprøvestrategier. I de fleste virkelige anvendt social forskning, vi ville bruge prøveudtagningsmetoder, der er betydeligt mere komplekse end disse enkle variationer., Det vigtigste princip her er, at vi kan kombinere de enkle metoder, der er beskrevet tidligere på en række nyttige måder, der hjælper os med at imødekomme vores prøveudtagningsbehov på den mest effektive og effektive måde. Når vi kombinerer prøveudtagningsmetoder, kalder vi denne flertrinsprøveudtagning.for eksempel overveje ideen om at prøve ne.York State beboere til ansigt til ansigt intervie .s. Det er klart, at vi ønsker at gøre en form for klynge prøveudtagning som den første fase af processen. Vi kan prøve to .nships eller folketællinger i hele staten., Men i klynge sampling vi ville derefter gå på at måle alle i klynger, vi vælger. Selv hvis vi prøver folketællingskanaler, er vi muligvis ikke i stand til at måle alle, der er i folketællingskanalen. Så vi kan oprette en stratificeret prøveudtagningsproces inden for klyngerne. I dette tilfælde ville vi have en to-trins prøveudtagningsproces med stratificerede prøver inden for klyngeprøver. Eller overvej problemet med prøveudtagning af studerende i klasseskoler. Vi kan begynde med en national prøve af skoledistrikter stratificeret af økonomi og uddannelsesniveau., Inden for udvalgte distrikter kan vi lave en simpel tilfældig stikprøve af skoler. Inden skoler, vi kan gøre en simpel tilfældig prøve af klasser eller kvaliteter. Og inden for klasser kan vi endda lave en simpel tilfældig prøve af studerende. I dette tilfælde har vi tre eller fire faser i prøveudtagningsprocessen, og vi bruger både stratificeret og simpel tilfældig prøveudtagning. Ved at kombinere forskellige prøveudtagningsmetoder er vi i stand til at opnå et stort udvalg af probabilistiske prøveudtagningsmetoder, der kan bruges i en lang række sociale forskningssammenhænge.