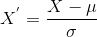Introduktion til Funktionen Skalering
jeg var for nylig arbejdet med et datasæt, der havde flere funktioner, der spænder over forskellige grader af omfang, rækkevidde og enheder. Dette er en betydelig hindring, da nogle få maskinlæringsalgoritmer er meget følsomme over for disse funktioner.
Jeg er sikker på, at de fleste af jer må have været udsat for dette problem i dine projekter eller din læringsrejse., For eksempel er en funktion helt i kilo, mens den anden er i gram, en anden er liter og så videre. Hvordan kan vi bruge disse funktioner, når de varierer så meget med hensyn til, hvad de præsenterer?
det er her jeg vendte mig til begrebet funktionskalering. Det er en afgørende del af data forbehandling fase, men jeg har set en masse begyndere overse det (til skade for deres machine learning model).,

Her er de nysgerrige ting, om funktionen skalering – det forbedrer (væsentligt) udførelsen af nogle af machine learning algoritmer og virker ikke på alle andre. Hvad kunne være årsagen bag denne særhed?
også, hvad er forskellen mellem normalisering og standardisering? Disse er to af de mest almindeligt anvendte funktion skalering teknikker i machine learning, men et niveau af tvetydighed eksisterer i deres forståelse. Hvornår skal du bruge hvilken teknik?,
Jeg vil besvare disse spørgsmål og mere i denne artikel om funktionsskalering. Vi vil også implementere funktionskalering i Python for at give dig en praksisforståelse af, hvordan det fungerer til forskellige maskinlæringsalgoritmer.bemærk: jeg antager, at du er bekendt med Python og core machine learning algoritmer., Hvis du er ny til dette, vil jeg anbefale at gå gennem nedenstående kurser:
- Python for Data Videnskab
- Alle gratis Machine Learning Kurser i Analytics, Vidhya
- Anvendes Machine Learning
Indholdsfortegnelse
- Hvorfor Skal vi Bruge Funktionen Skalering?
- hvad er normalisering?
- hvad er standardisering?
- det store spørgsmål-normalisere eller standardisere?,
- at Gennemføre Funktionen Skalering i Python
- Normalisering ved hjælp af Sklearn
- Standardisering ved hjælp af Sklearn
- Anvende Funktionen Skalering til Machine Learning Algoritmer
- K-Nærmeste Naboer (KNN)
- Support Vektor Regressor
- beslutningstræ
Hvorfor Skal vi Bruge Funktionen Skalering?
det første spørgsmål, vi skal tage fat på – hvorfor skal vi skalere variablerne i vores datasæt? Nogle machine learning algoritmer er følsomme over for funktionen skalering, mens andre er næsten invariant til det., Lad mig forklare det mere detaljeret.
Gradient Nedstigningsbaserede algoritmer
maskinlæringsalgoritmer som lineær regression, logistisk regression, neuralt netværk osv. at bruge gradient nedstigning som en optimering teknik kræver data skaleres. Se på formlen for gradientafstamning nedenfor:

tilstedeværelsen af funktionsværdi.i formlen vil påvirke trinstørrelsen på gradientafstamningen. Forskellen i intervaller af funktioner vil medføre forskellige trinstørrelser for hver funktion., For at sikre, at gradientafstamningen bevæger sig glat mod minima, og at trinnene for gradientafstamningen opdateres med samme hastighed for alle funktionerne, skalerer vi dataene, før vi fodrer dem til modellen.
at have funktioner i en lignende skala kan hjælpe gradientafstamningen med at konvergere hurtigere mod minima.
afstandsbaserede algoritmer
Afstandsalgoritmer som KNN, K-midler og SVM påvirkes mest af række funktioner., Dette skyldes, at de bag kulisserne bruger afstande mellem datapunkter for at bestemme deres lighed.
For eksempel, lad os sige, at vi har data, der indeholder high school CGPA snesevis af studerende (fra 0 til 5) og deres fremtidige indkomster (i tusinde Rupees):

Da både de funktioner, har forskellige skalaer, er der en chance for, at højere weightage er givet til funktioner med højere størrelsesorden. Dette vil påvirke udførelsen af maskinindlæringsalgoritmen, og vi ønsker naturligvis ikke, at vores algoritme skal biassed mod en funktion.,
derfor skalerer vi vores data, før vi anvender en afstandsbaseret algoritme, så alle funktioner bidrager lige til resultatet.,nts A og B, og mellem B og C, før og efter skalering, som vist nedenfor:
- Afstanden AB før skalering =>

- Afstand BC før skalering =>

- Afstanden AB efter skalering =>

- Afstand F.KR. efter skalering =>

Skalering har bragt både funktioner ind i billedet, og afstandene er nu mere sammenlignelige, end de var, før vi anvendt skalering.,
træbaserede algoritmer
træbaserede algoritmer er på den anden side temmelig ufølsomme over for omfanget af funktionerne. Tænk over det, et beslutningstræ deler kun en knude baseret på en enkelt funktion. Beslutningstræet opdeler en knude på en funktion, der øger nodens homogenitet. Denne opdeling på en funktion påvirkes ikke af andre funktioner.
så der er næsten ingen effekt af de resterende funktioner på split. Dette er hvad der gør dem invariant til omfanget af funktionerne!
Hvad er normalisering?,
normalisering er en skaleringsteknik, hvor værdier forskydes og omskaleres, så de ender med at ligge mellem 0 og 1. Det er også kendt som Min-Ma.skalering.
Her er formlen for normalisering:
Her er respectivelyma.ogminmin henholdsvis maksimums-og minimumsværdierne for funktionen.,
- Når værdien af X er den mindste værdi i den kolonne, tælleren vil være 0, og dermed X’ er 0
- På den anden side, når værdien af X er den maksimale værdi i den kolonne, tælleren er lig med nævneren og dermed værdien af X’ er 1
- Hvis værdien af X er mellem den minimale og den maksimale værdi, så værdien af X’ er mellem 0 og 1
Hvad er Standardisering?
standardisering er en anden skaleringsteknik, hvor værdierne er centreret omkring gennemsnittet med en enhedsstandardafvigelse., Dette betyder, at gennemsnittet af attributten bliver nul, og den resulterende fordeling har en enhedsstandardafvigelse.
Her er formlen for standardisering:
er middelværdien af funktionen værdier og
er standard afvigelsen af funktionen værdier. Bemærk, at værdierne i dette tilfælde ikke er begrænset til et bestemt interval.
nu skal det store spørgsmål i dit sind være, Hvornår skal vi bruge normalisering, og hvornår skal vi bruge standardisering? Lad os finde ud af det!,
det store spørgsmål – normalisere eller standardisere?
normalisering vs. standardisering er et evigt spørgsmål blandt nybegyndere til maskinlæring. Lad mig uddybe svaret i dette afsnit.
- normalisering er god at bruge, når du ved, at distributionen af dine data ikke følger en Gaussisk distribution. Dette kan være nyttigt i algoritmer, der ikke antager nogen distribution af data som K-nærmeste naboer og neurale netværk.
- standardisering kan på den anden side være nyttig i tilfælde, hvor dataene følger en Gaussisk distribution., Dette behøver dog ikke nødvendigvis at være sandt. I modsætning til normalisering har standardisering heller ikke et afgrænsningsområde. Så selvom du har outliers i dine data, vil de ikke blive påvirket af standardisering.
men i slutningen af dagen afhænger valget af at bruge normalisering eller standardisering af dit problem og den maskinindlæringsalgoritme, du bruger. Der er ingen hård og hurtig regel til at fortælle dig, hvornår du skal normalisere eller standardisere dine data., Du kan altid starte med at montere din model til rå, normaliserede og standardiserede data og sammenligne ydeevnen for de bedste resultater.
det er en god praksis at passe skaleren på træningsdataene og derefter bruge den til at transformere testdataene. Dette ville undgå data lækage under model testprocessen. Skalering af målværdier er generelt ikke påkrævet.
implementering af Funktionskalering i Python
nu kommer den sjove del – at sætte det, vi har lært, i praksis., Jeg vil anvende funktionskalering til et par maskinlæringsalgoritmer på Big Mart-datasættet, jeg har taget DataHack-platformen.
Jeg vil springe over forbehandlingstrinnene, da de er uden for rammerne af denne tutorial. Men du kan finde dem pænt forklaret i denne artikel. Disse trin vil gøre det muligt for dig at nå toppen 20 percentil på hackathon leaderboard, så det er værd at tjekke ud!
så lad os først opdele vores data i Trænings-og testsæt:
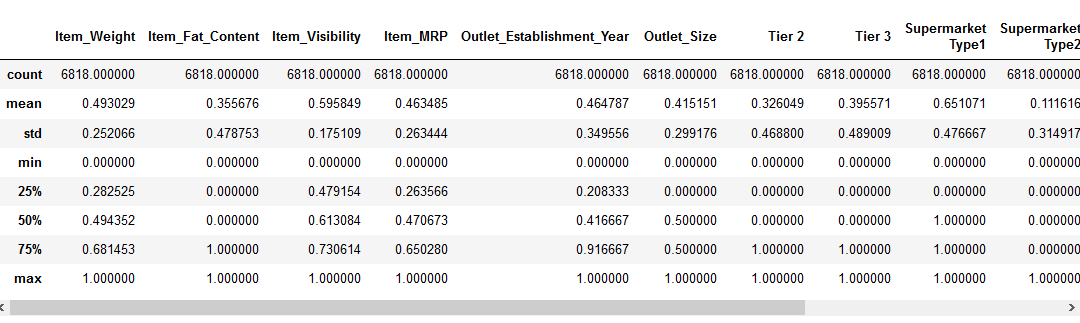
før vi flytter til funktionen skalering del, lad os se på detaljerne om vores data ved hjælp af pd.,beskrive () – metoden:
Vi kan se, at der er en enorm forskel i de forskellige værdier til stede i vores numeriske funktioner: Item_Visibility, Item_Weight, Item_MRP, og Outlet_Establishment_Year. Lad os prøve at løse det ved hjælp af funktionskalering!Bemærk: Du vil bemærke negative værdier i Item_Visibility-funktionen, fordi jeg har taget log-transformation for at håndtere skævheden i funktionen.
normalisering ved hjælp af sklearn
for at normalisere dine data skal du importere Minma .scalar fra sklearn-biblioteket og anvende det på vores datasæt., Så lad os gøre det!
lad os se, hvordan normalisering har påvirket vores datasæt:
alle funktioner har nu en minimumsværdi på 0 og en maksimal værdi på 1. Perfekt!
prøv ovenstående kode i live kodningsvinduet nedenfor!!
lad os derefter prøve at standardisere vores data.
standardisering ved hjælp af sklearn
for at standardisere dine data skal du importere StandardScalar fra sklearn-biblioteket og anvende det på vores datasæt., Sådan kan du gøre det:
du ville have bemærket, at jeg kun anvendte standardisering til mine numeriske kolonner og ikke den anden-Hot-kodede funktioner. Standardisere One-Hot kodede funktioner ville betyde at tildele en fordeling til kategoriske funktioner. Det vil du ikke!
men hvorfor gjorde jeg ikke det samme, mens jeg normaliserede dataene? Fordi One-Hot kodede funktioner er allerede i området mellem 0 til 1. Så normalisering ville ikke påvirke deres værdi.,
højre, lad os se på, hvordan standardisering har transformeret vores data:
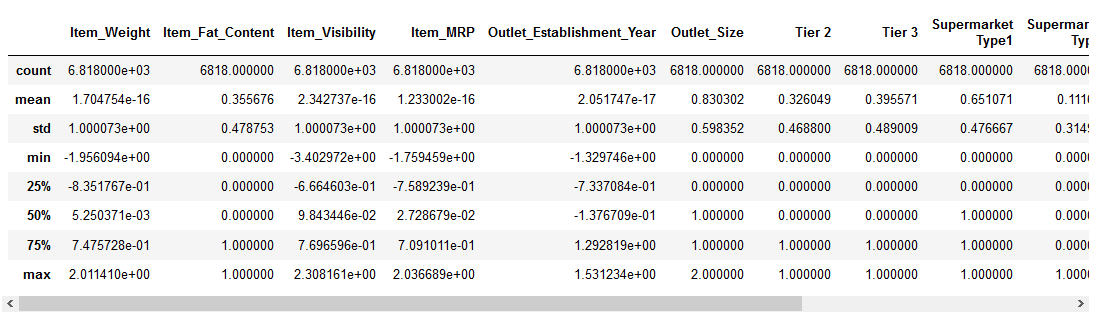
de numeriske funktioner er nu centreret om gennemsnittet med en enhedsstandardafvigelse. Fedt!
sammenligning af uskalerede, normaliserede og standardiserede data
det er altid dejligt at visualisere dine data for at forstå den nuværende distribution. Vi kan se sammenligningen mellem vores unscaled og skalerede data ved hjælp af Bo .plots.
Du kan lære mere om datavisualisering her.,
Du kan se, hvordan skalering af funktionerne bringer alt i perspektiv. Funktionerne er nu mere sammenlignelige og vil have en lignende effekt på læringsmodellerne.
anvendelse af skalering til maskinlæringsalgoritmer
det er nu tid til at træne nogle maskinlæringsalgoritmer på vores data for at sammenligne virkningerne af forskellige skaleringsteknikker på algoritmens ydeevne. Jeg ønsker at se effekten af skalering på tre algoritmer i særdeleshed: K-nærmeste naboer, støtte vektor Regressor, og beslutning træ.,
K-nærmeste naboer
som vi så før, er KNN en afstandsbaseret algoritme, der påvirkes af rækkevidden af funktioner. Lad os se, hvordan det fungerer på vores data, før og efter skalering:
Du kan se, at skalering de funktioner, der er bragt ned RMSE score på vores KNN model. Specifikt udfører de normaliserede data En smule bedre end de standardiserede data.
Bemærk: jeg måler RMSE her, fordi denne konkurrence evaluerer RMSE.
Support Vector Regressor
SVR er en anden afstandsbaseret algoritme., Så lad os se, om det fungerer bedre med normalisering eller standardisering:
Vi kan se, at skalering funktioner ikke bringe ned RMSE score. Og de standardiserede data har fungeret bedre end de normaliserede data. Hvorfor tror du, det er tilfældet?
sklearn-dokumentationen angiver, at SVM med RBF-kerne antager, at alle funktionerne er centreret omkring nul, og variansen er af samme rækkefølge. Dette skyldes, at en funktion med en varians, der er større end andres, forhindrer estimatoren i at lære af alle funktionerne., Fedt!
beslutningstræ
Vi ved allerede, at et beslutningstræ er invariant at have skalering. Men jeg ville vise et praktisk eksempel på, hvordan det fungerer på dataene:
Du kan se, at RMSE-score ikke har flyttet en tomme på skalering af funktionerne. Så vær sikker på, når du bruger træbaserede algoritmer på dine data!,
Afslut Noter
Denne tutorial, der er omfattet relevansen af at bruge funktionen skalering på dine data, og hvordan normalisering og standardisering har forskellige virkninger på bearbejdning af machine learning algoritmer
husk, at der ikke er nogen rigtige svar til, når at bruge normalisering over standardisering og vice-versa. Det hele afhænger af dine data og den algoritme, du bruger.som et næste trin opfordrer jeg dig til at prøve funktionsskalering med andre algoritmer og finde ud af, hvad der fungerer bedst – normalisering eller standardisering?, Jeg anbefaler, at du bruger BigMart salgsdata til dette formål for at opretholde kontinuiteten med denne artikel. Og glem ikke at dele din indsigt i kommentarfeltet nedenfor!
Du kan også læse denne artikel på vores mobilapp