metoda vzorkování pravděpodobnosti je jakákoli metoda odběru vzorků, která využívá nějakou formu náhodného výběru. Chcete-li mít metodu náhodného výběru, musíte nastavit nějaký proces nebo postup, který zajistí, že různé jednotky ve vaší populaci mají stejnou pravděpodobnost výběru. Lidé již dlouho praktikují různé formy náhodného výběru, jako je vybírání jména z klobouku nebo výběr krátké slámy. V těchto dnech, máme tendenci používat počítače jako mechanismus pro generování náhodných čísel jako základ pro náhodný výběr.,
některé definice
než budu moci vysvětlit různé metody pravděpodobnosti, musíme definovat některé základní pojmy. Jsou to:
-
Nje počet případů u vzorků rám -
nje počet případů ve vzorku -
NCn= počet kombinací (podmnožiny)nN -
f = n/Nje vzorkovací zlomek
to je to., S těmito definovanými pojmy můžeme začít definovat různé metody vzorkování pravděpodobnosti.
jednoduchý náhodný odběr
nejjednodušší forma náhodného odběru se nazývá jednoduchý náhodný odběr vzorků. Dost ošemetné, co? Zde je rychlý popis prostý náhodný výběr:
- Cíl: vyberte
njednotkyNNCnmá stejnou šanci být vybrán. - postup: pro výběr vzorku použijte tabulku náhodných čísel, generátor náhodných čísel počítače nebo mechanické zařízení.,
poněkud strnulá, pokud přesná, definice. Uvidíme, jestli to dokážeme udělat trochu reálnější.

Jak vybereme jednoduchý náhodný vzorek? Předpokládejme, že děláme nějaký výzkum s malou servisní agenturou, která si přeje posoudit názory klientů na kvalitu služeb za poslední rok. Nejprve musíme uspořádat vzorkovací rámec. Abychom toho dosáhli, projdeme záznamy agentur, abychom identifikovali každého klienta za posledních 12 měsíců. Pokud budeme mít štěstí, agentura má dobré přesné počítačové záznamy a může takový seznam rychle vytvořit., Pak musíme vzorek skutečně nakreslit. Rozhodněte se o počtu klientů, které byste chtěli mít v konečném vzorku. Pro příklad Řekněme, že chcete vybrat 100 klientů k průzkumu a že za posledních 12 měsíců bylo 1000 klientů. Potom je vzorkovací frakce f = n/N = 100/1000 = .10 (nebo 10%). Nyní, abyste vzorek skutečně nakreslili, máte několik možností. Můžete vytisknout seznam 1000 klientů, roztrhat pak do samostatných proužků, dát proužky do klobouku, promíchat je opravdu dobře, zavřít oči a vytáhnout prvních 100., Ale tento mechanický postup by byl zdlouhavý a kvalita vzorku bude záviset na tom, jak důkladně jsi to popletl a jak náhodně jste dosáhli. Snad lepší postup by bylo použít druh kulového stroje, který je oblíbený u mnoha státních loterií. Budete potřebovat tři sady míčků s čísly 0 až 9, jednu pro každou z číslic od 000 999 (pokud vybereme 000 budeme říkat, že 1000)., Číslo seznamu jmen z 1 1000 a pak použít míč stroj, vyberte tři číslice, které vybere každý člověk. Zjevnou nevýhodou je, že musíte získat míčové stroje. (Kde to vlastně dělají? Existuje průmysl kulových strojů?).
ani jeden z těchto mechanických postupů není velmi proveditelný a při vývoji levných počítačů existuje mnohem jednodušší způsob. Zde je jednoduchý postup, který je zvláště užitečný, pokud máte jména klientů již v počítači., Mnoho počítačových programů může generovat řadu náhodných čísel. Předpokládejme, že můžete zkopírovat a vložit seznam názvů klientů do sloupce v tabulce EXCEL. Pak, ve sloupci přímo vedle něj vložit funkci =RAND() což je EXCEL je způsob, jak dát náhodné číslo mezi 0 1 v buňkách. Poté Seřadit oba sloupce-seznam jmen a náhodné číslo – podle náhodných čísel. Tím se přeskupí seznam v náhodném pořadí od nejnižšího k Nejvyššímu náhodnému číslu., Pak, vše, co musíte udělat, je vzít prvních sto jmen v tomto seřazeném seznamu. docela jednoduché. Pravděpodobně byste to mohli dokončit za méně než minutu.
jednoduchý náhodný vzorkování je jednoduché dosáhnout a je snadné vysvětlit ostatním. Protože jednoduchý náhodný vzorkování je spravedlivý způsob, jak vybrat vzorek, je rozumné zobecnit výsledky ze vzorku zpět do populace. Jednoduchý náhodný odběr vzorků není statisticky nejúčinnější metodou odběru vzorků a můžete, jen kvůli štěstí losování, nedostanete dobrou reprezentaci podskupin v populaci., Abychom se s těmito problémy vypořádali, musíme se obrátit na jiné metody odběru vzorků.
Stratifikovaný Náhodný výběr
Stratifikovaný Náhodný výběr, někdy se také nazývá proporcionální nebo kvóty náhodný výběr, spočívá v rozdělení populace do homogenních podskupin a pak s jednoduchý náhodný vzorek v každé podskupině. Ve více formálních termínech:
existuje několik hlavních důvodů, proč byste mohli upřednostňovat stratifikovaný vzorkování před jednoduchým náhodným vzorkováním., Za prvé, ujišťuje, že budete schopni zastupovat nejen celkovou populaci, ale také klíčové podskupiny obyvatelstva, zejména malé menšinové skupiny. Pokud chcete být schopni mluvit o podskupinách, může to být jediný způsob, jak efektivně zajistit, že budete moci. Pokud je podskupina je velmi malý, můžete použít různé vzorkovací frakce (f) v rámci jednotlivých vrstev náhodně přes-vzorek malé skupiny (i když potom budete mít k hmotnosti v rámci skupiny odhaduje pomocí odběru vzorků frakce, kdykoli budete chtít, celkové odhady počtu obyvatel)., Při použití stejné vzorkovací frakce ve vrstvách provádíme přiměřený stratifikovaný náhodný odběr vzorků. Když používáme různé vzorkovací frakce ve vrstvách, nazýváme tento nepřiměřený stratifikovaný náhodný odběr vzorků. Za druhé, stratifikovaný náhodný odběr vzorků bude mít obecně větší statistickou přesnost než jednoduchý náhodný odběr vzorků. To platí pouze v případě, že vrstvy nebo skupiny jsou homogenní. Pokud ano, očekáváme, že variabilita uvnitř skupin je nižší než variabilita populace jako celku. Stratifikovaný vzorkování těží z této skutečnosti.,
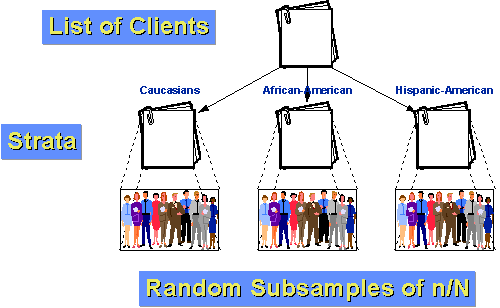
například, řekněme, že populace klientů pro naši agenturu je možné rozdělit do tří skupin: Běloch, Afro-Americké a Hispánské Americké. Dále předpokládejme, že afroameričané i Hispánci jsou relativně malými menšinami klientely (10% a 5%)., Pokud jsme právě udělali jednoduchý náhodný vzorek n=100 s vzorkovací část 10%, očekávali bychom, že náhodou sám, že bychom dostali pouze 10 a 5 osob z každé ze dvou menších skupin. A náhodou bychom mohli dostat méně než to! Pokud se stratifikujeme, můžeme to udělat lépe. Nejprve zjistíme, kolik lidí chceme mít v každé skupině. Řekněme, že stále chceme odebrat vzorek 100 z populace 1000 klientů za poslední rok. Myslíme si však, že k tomu, abychom mohli říci něco o podskupinách, budeme potřebovat alespoň 25 případů v každé skupině., Takže pojďme ochutnat 50 bělochů, 25 Afroameričanů a 25 hispánských Američanů. Víme, že 10% populace, nebo 100 klientů, jsou afroameričané. Pokud náhodně odebereme 25 z nich, máme vzorkovací frakci uvnitř vrstvy 25/100 = 25%. Podobně víme, že 5% nebo 50 klientů jsou Hispánsko-Američtí. Takže naše vzorkovací frakce uvnitř vrstvy bude 25/50 = 50%. Nakonec odečtením víme, že existuje 850 kavkazských klientů. Naše vzorkovací frakce uvnitř vrstvy pro ně je 50/850 = about 5.88%., Vzhledem k tomu, že skupiny jsou homogennější uvnitř skupiny než v celé populaci jako celku, můžeme očekávat větší statistickou přesnost (menší rozptyl). A protože jsme stratifikovali, víme, že budeme mít dostatek případů z každé skupiny, abychom mohli učinit smysluplné závěry podskupin.,e jsou kroky, které musíte dodržovat, aby bylo možné dosáhnout systematického náhodného vzorku:
- počet jednotek v populaci od
1N - rozhodněte o
n(velikost vzorku) že chcete nebo potřebujete, -
k = N/n= interval velikosti - náhodně vybrat číslo mezi
1k - pak každý
kthjednotka

tohle Všechno bude mnohem jasnější na příkladu., Předpokládejme, že máme populaci, která má v sobě pouze N=100 lidí a že chcete vzít vzorek n=20. Pro použití systematického odběru vzorků musí být populace uvedena v náhodném pořadí. Vzorkovací frakce by byla f = 20/100 = 20%. v tomto případě se velikost intervalu k rovná N/n = 100/20 = 5. Nyní vyberte náhodné celé číslo z 1 to 5. V našem příkladu si představte, že jste vybrali 4., Chcete – li vybrat vzorek, začněte v seznamu jednotkou 4th a vezměte každou jednotku k-th (každé 5., protože k=5). Byli byste vzorkovacími jednotkami 4, 9, 14, 19 a tak dále na 100 a skončili byste s 20 jednotkami ve vzorku.
aby to fungovalo, je nezbytné, aby jednotky v populaci byly náhodně uspořádány, alespoň pokud jde o vlastnosti, které měříte. Proč byste někdy chtěli použít systematický náhodný odběr vzorků? Pro jednu věc je to docela snadné. Chcete-li začít, musíte vybrat pouze jedno náhodné číslo., Může být také přesnější než jednoduchý náhodný odběr vzorků. A konečně, v některých situacích prostě neexistuje jednodušší způsob, jak provést náhodný odběr vzorků. Například, jednou jsem musel udělat studii, která zahrnovala odběr vzorků ze všech knih v knihovně. Po výběru bych musel jít na polici, najít knihu a zaznamenat, až bude naposledy v oběhu. Věděl jsem, že mám poměrně dobrý vzorkovací rámeček ve formě seznamu polic (což je katalog karet, kde jsou položky uspořádány v pořadí, v jakém se vyskytují na polici)., Udělat jednoduchý náhodný vzorek, mohl jsem odhadl celkový počet knih a generované náhodné čísla pro odběr vzorku; ale jak bych najít knihy #74,329 snadno, pokud to je číslo, které jsem vybrala? Nemohl jsem moc dobře počítat karty, dokud jsem přišel na 74,329! Stratifikace by tento problém také nevyřešil. Mohl jsem například rozvrstvit zásuvku katalogu karet a nakreslit jednoduchý náhodný vzorek v každé zásuvce. Ale stejně bych se zasekl v počítání karet. Místo toho jsem provedl systematický náhodný vzorek. Odhadl jsem počet knih v celé sbírce. Představme si, že to bylo 100 000., Rozhodl jsem se, že chci odebrat vzorek 1000 pro vzorkovací zlomek 1000/100,000 = 1%. Chcete-li získat interval odběru vzorků k, rozdělil jsem N/n = 100,000/1000 = 100. Pak jsem vybral náhodné celé číslo mezi 1 a 100. Řekněme, že mám 57.
dále jsem udělal malou boční studii, abych zjistil, jak silná je tisíc karet v katalogu karet (s přihlédnutím k různému věku karet)., Řekněme, že v průměru jsem zjistil, že dvě karty, které byly odděleny pomocí 100 karty byly o .75 palce od sebe v katalogu šuplíku. Tato informace mi dala vše, co jsem potřeboval k tomu vzorku. Počítal jsem do 57. ruky a zaznamenal informace o knize. Pak jsem vzal kompas. (Vzpomínáte si na ty z vaší středoškolské třídy matematiky? Jsou to legrační malé kovové nástroje s ostrým kolíkem na jednom konci a tužkou na druhém, které jste použili k kreslení kruhů ve třídě geometrie.,) Pak jsem nastavit kompas na .75", uvízl pin end v na 57 kartu a ukázal s tužkou end na další kartu (cca 100 knih). Tímto způsobem jsem aproximoval výběr 157., 257., 357. a tak dále. Byl jsem schopen provést celý výběrové řízení ve velmi krátkém čase pomocí tohoto systematického náhodného vzorkování přístupu. Pravděpodobně bych tam stále počítal karty, kdybych vyzkoušel jinou náhodnou metodu vzorkování. (Dobře, takže nemám život. Dostal jsem kompenzaci pěkně, nevadí mi to říct, za to, že jsem přišel s tímto schématem.,)
Clusteru (Oblastní) Náhodný výběr
problém s náhodným výběrem metody, když máme na vzorku populace, která je vyplacena v široké geografické oblasti je, že budete muset pokrýt hodně prostoru geograficky, aby se dostat do každé z jednotek zařazených do vzorku. Představte si, že vezmete jednoduchý náhodný vzorek všech obyvatel státu New York, abyste mohli provádět osobní rozhovory. Při štěstí losování skončíte s respondenty, kteří pocházejí z celého státu. Vaši tazatelé budou muset hodně cestovat., Právě pro tento problém byl vynalezen náhodný výběr clusteru nebo oblasti.
V clusteru odběry, postupujte takto:
- rozdělit populaci do skupin (obvykle podél zeměpisné hranice)
- náhodně shluky
- změřit všechny jednotky ve vzorku shluky
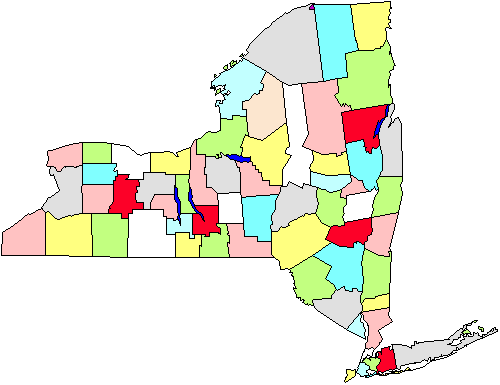
například, na obrázku vidíme mapu krajů ve Státě New York. Řekněme, že musíme udělat průzkum městských vlád, který bude vyžadovat, abychom šli do měst osobně., Pokud uděláme jednoduchý náhodný vzorek po celém státě, budeme muset geograficky pokrýt celý stát. Místo toho se rozhodneme udělat vzorkování clusteru pěti krajů (na obrázku je červeně označeno). Jakmile jsou vybrány, jdeme do každé městské vlády v pěti oblastech. Je zřejmé, že tato strategie nám pomůže ušetřit na našich najetých kilometrech. Vzorkování clusteru nebo oblasti je tedy užitečné v takových situacích a provádí se především pro efektivitu správy., Všimněte si také, že jsme pravděpodobně nebudete muset starat o použití tohoto přístupu, pokud provádíme mail nebo telefonický průzkum, protože nezáleží na tom, jak moc (nebo dražší, nebo zvýšit neefektivnost), kde jsme volat nebo posílat dopisy.
vícestupňový vzorkování
čtyři metody, které jsme dosud pokryli-jednoduché, stratifikované, systematické a cluster – jsou nejjednodušší strategie náhodného odběru vzorků. Ve většině skutečných aplikovaných sociálních výzkumů bychom použili metody odběru vzorků, které jsou podstatně složitější než tyto jednoduché varianty., Nejdůležitějším principem je, že můžeme kombinovat jednoduché metody popsané dříve různými užitečnými způsoby, které nám pomáhají řešit naše potřeby odběru vzorků co nejúčinnějším a nejúčinnějším způsobem. Když kombinujeme metody odběru vzorků, nazýváme tento vícestupňový vzorkování.
například zvažte myšlenku odběru vzorků obyvatel státu New York pro osobní rozhovory. Je zřejmé, že bychom chtěli udělat nějaký typ vzorkování clusteru jako první fázi procesu. Mohli bychom ochutnat černošské čtvrti nebo sčítací plochy po celém státě., Ale při výběru clusteru bychom pak pokračovali v měření všech v klastrech, které vybereme. I když jsme vzorkování sčítacích traktů nemusí být schopen měřit každý, kdo je v sčítacím traktu. Můžeme tedy vytvořit stratifikovaný proces odběru vzorků v rámci klastrů. V tomto případě bychom měli dvoustupňový proces odběru vzorků s rozvrstvenými vzorky ve vzorcích clusteru. Nebo zvážit problém vzorkování studentů na základních školách. Můžeme začít s národním vzorkem školních obvodů rozvrstvených ekonomikou a úrovní vzdělání., V rámci vybraných okresů bychom mohli udělat jednoduchý náhodný vzorek škol. V rámci škol bychom mohli udělat jednoduchý náhodný vzorek tříd nebo tříd. A, v rámci tříd, můžeme dokonce udělat jednoduchý náhodný vzorek studentů. V tomto případě máme tři nebo čtyři fáze procesu odběru vzorků a používáme jak stratifikovaný, tak jednoduchý náhodný odběr vzorků. Kombinací různých metod odběru vzorků jsme schopni dosáhnout bohaté škály pravděpodobnostních vzorkovacích metod, které lze použít v široké škále kontextů sociálního výzkumu.