Úvod
Třídění dat znamená, že uspořádá je v určitém pořadí, často v poli-jako datové struktury. Můžete použít různé uspořádání kritérií, nejčastější je řazení čísel od nejmenšího po největší, nebo naopak, nebo třídění řetězce lexikograficky. Můžete dokonce definovat vlastní kritéria a do konce tohoto článku se podíváme na praktické způsoby, jak to udělat.,
Pokud vás zajímá, jak se třídění funguje, budeme pokrývat různé algoritmy, z neefektivní, ale intuitivní řešení, efektivní algoritmy, které jsou skutečně implementovány v jazyce Java a další jazyky.
existují různé algoritmy třídění a nejsou všechny stejně účinné. Budeme analyzovat jejich časovou složitost, abychom je mohli porovnat a zjistit, které z nich jsou nejlepší.,
seznam algoritmů dozvíte zde není v žádném případě vyčerpávající, ale jsme sestavili některé z nejčastějších a nejvíce efektivní ty, které vám pomohou začít:
- Bubble Sort
- Vložení
- Výběr Druhu
- Merge Sort
- Heapsort
- Quicksort
- Třídění v jazyce Java
Poznámka: Tento článek se nebude zabývat souběžné třídění, protože je určen pro začátečníky.
Bubble Sort
vysvětlení
Bubble sort funguje tak, že vymění sousední prvky, pokud nejsou v požadovaném pořadí., Tento proces se opakuje od začátku pole, dokud nejsou všechny prvky v pořádku.
víme, že všechny prvky jsou v pořádku, když se nám podaří udělat celou iteraci bez prohazování vůbec – pak všechny prvky, porovnali jsme byly v požadovaném pořadí s jejich sousední prvky, a potažmo celé pole.
Zde jsou kroky pro třídění pole čísel od nejmenšího po největší:
-
4 2 1 5 3: první dva prvky jsou ve špatném pořadí, takže jsme je vyměnit.
-
2 4 1 5 3: druhé dva prvky jsou také v nesprávném pořadí, takže vyměňujeme.,
-
2 1 4 5 3: tito dva jsou ve správném pořadí, 4 < 5, takže je necháme na pokoji.
-
2 1 4 5 3: další výměna.
-
2 1 4 3 5: Zde je výsledné pole po jedné iteraci.
Protože alespoň jeden swap došlo během první průchod (tam byly vlastně tři), musíme projít celé pole znovu a opakujte stejný postup.
opakováním tohoto procesu, dokud nebudou provedeny žádné další swapy, budeme mít tříděné pole.,
důvodem, proč se tento algoritmus nazývá Bubble Sort, je to, že čísla „bubble up“ na “ povrch.“Pokud znovu projdete naším příkladem, po určitém čísle (4 je skvělý příklad), uvidíte, že se během procesu pomalu pohybuje doprava.
všechna čísla se pohybují na příslušná místa kousek po kousku, zleva doprava, jako bubliny pomalu stoupající z vodního útvaru.
Pokud si chcete přečíst podrobný, vyhrazený článek pro Bubble Sort, máme vás vztahuje!,
implementace
budeme implementovat Bubble Sort podobným způsobem, jakým jsme to vyložili slovy. Naše funkce vstupuje do časové smyčky, ve které prochází celou výměnou pole podle potřeby.
předpokládáme, že pole je seřazeno, ale pokud se při třídění prokážeme špatně (pokud dojde k výměně), projdeme další iterací. While-loop pak dál, dokud se nám podaří projít celé pole bez swapování:
Při použití tohoto algoritmu musíme být opatrní, jak jsme se stát naším odkládací podmínkou.,
například, pokud bych měl použít a >= a mohlo to skončit s nekonečnou smyčku, protože pro stejné prvky tohoto vztahu by vždy být true, a proto vždy vyměnit.
časová složitost
abychom zjistili časovou složitost bublin, musíme se podívat na nejhorší možný scénář. Jaký je maximální počet, kolikrát musíme projít celé pole, než jsme to vyřešil?, Zvažte následující příklad:
5 4 3 2 1V první iteraci, 5 „vyvěrají na povrch,“ ale ostatní prvky by zůstat v sestupném pořadí. Museli bychom udělat jednu iteraci pro každý prvek kromě 1 a pak další iteraci, abychom zkontrolovali, zda je vše v pořádku, takže celkem 5 iterací.
rozbalte to na libovolné polen prvků, a to znamená ,že musíte udělatn iterací., Při pohledu na kód by to znamenalo, že našewhile smyčka může spustit maximumn časy.
každý z těchn krát opakujeme celé pole (For-loop v kódu), což znamená, že nejhorší časová složitost by byla O(n^2).
Poznámka: časová složitost by být vždy O(n^2) kdyby to nebylo pro sorted boolean šek, který ukončí algoritmus, jestli tam nejsou nějaké swapy ve vnitřní smyčce – což znamená, že pole je seřazené.,
vložení Sort
vysvětlení
myšlenka vložení Sort rozděluje pole na tříděné a netříděné subarrays.
řazená část má na začátku délku 1 a odpovídá prvnímu (levému) prvku v poli. Iterujeme přes pole a během každé iterace rozšiřujeme tříděnou část pole o jeden prvek.
po rozšíření umístíme nový prvek na jeho správné místo v rámci tříděného subarray. Děláme to posunutím všech prvků doprava, dokud nenarazíme na první prvek, který nemusíme posouvat.,
například, pokud v následujících pole tučná část je řazena ve vzestupném pořadí, stane se následující:
-
3 5 7 8 4 2 1 9 6: vezmeme 4 a pamatujte, že to je to, co potřebujeme chcete-li vložit. Protože 8 > 4, posuneme se.
-
3 5 7 x 8 2 1 9 6: je-li hodnota x není zásadní význam, protože to bude přepsána okamžitě (buď 4, pokud je to vhodné místo, nebo o 7 přesuneme-li). Od 7 > 4 se posuneme.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Po tomto procesu, jsou seřazeny část byla rozšířena o jeden prvek, nyní máme pět, spíše než čtyři prvky. Každá iterace to udělá a na konci budeme mít celé pole seřazeno.
Pokud byste si chtěli přečíst podrobný, vyhrazený článek pro vložení Třídit, máme vás vztahuje!,
implementace
časová složitost
znovu se musíme podívat na nejhorší scénář našeho algoritmu a bude to opět příklad, kdy celé pole sestupuje.
je to proto, že v každé iteraci budeme muset přesunout celý seřazený seznam o jeden, což je O (n). Musíme to udělat pro každý prvek v každém poli, což znamená, že to bude ohraničeno O(n^2).
Selection Sort
vysvětlení
Selection Sort také rozděluje pole na tříděný a netříděný subarray., I když, tentokrát, seřazené pole je tvořen vložením minimální prvek z nesetříděné pole na konci seřazené pole, tím, že vymění:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Realizace
V každé iteraci, můžeme předpokládat, že první netříděného prvek je minimální a iterovat zbytek, jestli tam je menší prvek.,
Jakmile jsme najít aktuální minimum netříděného část pole, vyměníme ho s prvním prvkem a považují to za část seřazené pole:
Doba Složitost
Nalezení minimum je O(n) pro délku pole, protože musíme zkontrolovat všechny prvky. Musíme najít minimum pro každý prvek pole, takže celý proces ohraničený O (n^2).,
Merge Sort
Vysvětlení
Merge Sort používá rekurze vyřešit problém třídění efektivněji než algoritmy dříve prezentovány, a zejména používá rozděl a panuj přístup.
Pomocí obou těchto pojmů, rozbijeme celé pole dolů do dvou subarrays a pak:
- Seřadit levou polovinu pole (rekurzivně)
- Třídění pravá polovina pole (rekurzivně)
- Sloučit řešení
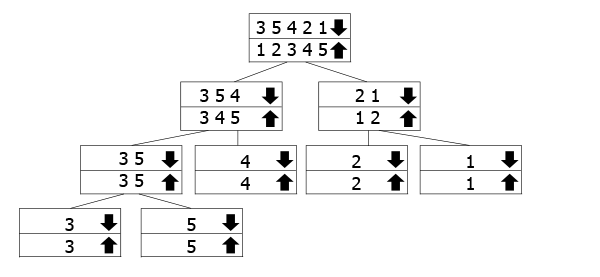
Tento strom je možno reprezentovat jak rekurzivní volání práce., Pole označená šipkou dolů jsou ty, které nazýváme funkcí, zatímco spojujeme šipky nahoru. Takže budete následovat šipku dolů na dno stromu, a pak se vrátit nahoru a sloučit.
V našem příkladu, máme pole 3 5 3 2 1, tak jsme je rozdělit do 3 5 4 2 1. Chcete-li je třídit, dále je rozdělíme na jejich součásti. Jakmile dosáhneme dna, začneme se spojovat a třídit je, jak jdeme.,
Pokud si chcete přečíst podrobný, vyhrazený článek pro sloučení Třídit, máme vás vztahuje!
implementace
základní funkce funguje do značné míry tak, jak je uvedeno ve vysvětlení. Jsme jen kolem indexy left right což jsou indexy nejvíce vlevo a nejvíce vpravo prvkem pole budeme chtít třídit. Zpočátku by to mělo být 0 a array.length-1, v závislosti na implementaci.,
základna naší rekurze zajišťuje ukončení, nebo když right a left setkat se navzájem. Najdeme střed mid, a druh subarrays vlevo a vpravo, to rekurzivně, v konečném důsledku sloučení našich řešení.
Pokud si pamatujete naši stromovou grafiku, možná se divíte, proč nevytvoříme dvě nová menší pole a místo toho je předáme. Je to proto, že na opravdu dlouhých polích by to způsobilo obrovskou spotřebu paměti pro něco, co je v podstatě zbytečné.,
sloučení Sort již nefunguje na místě kvůli kroku sloučení, což by sloužilo pouze ke zhoršení jeho účinnosti paměti. Logika našeho stromu rekurze jinak zůstává stejné, i když jsme jen sledovat indexy používáme:
sloučit řazeny subarrays do jednoho, budeme potřebovat pro výpočet délky každého a dočasné pole kopírovat do, takže jsme mohli libovolně měnit naše hlavní pole.
po kopírování projdeme výsledným polem a přiřadíme mu aktuální minimum., Protože naše subarrays jsou řazeny, prostě jsme si vybrali menší ze dvou prvků, které nebyly zvoleny tak daleko, a posunout iterátor na to pole vpřed:
Doba Složitost
chceme-Li odvodit složitosti rekurzivních algoritmů, budeme muset dostat trochu mathy.
hlavní věta se používá k určení časové složitosti rekurzivních algoritmů. Pro non-rekurzivní algoritmy, mohli jsme obvykle psát přesné časové složitosti jako nějaká rovnice, a pak jsme se použít Big-O Notace, seřadit je do tříd podobně se chová algoritmy.,
problém s rekurzivních algoritmů je, že ta samá rovnice bude vypadat nějak takhle:
$$
T(n) = v(\frac{n}{b}) + kn^k
$$
rovnice sama o sobě je rekurzivní! V této rovnici, a nám říká, kolikrát říkáme rekurze, a b nám říká, na kolik částí náš problém je rozdělen. V tomto případě se to může zdát jako nepodstatný rozdíl, protože jsou stejné pro mergesort, ale pro některé problémy nemusí být.,
zbytek rovnice je složitost sloučení všech těchto řešení do jednoho na konci., Master Theorem řeší tuto rovnici:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Pokud T(n) je runtime algoritmu při třídění pole o délce n, Merge Sort by běžet dvakrát pro pole, které jsou poloviční délky původního pole.,
takže pokud máme a=2, b=2. Krok sloučení vyžaduje paměť O(n), takže k=1. To znamená, že rovnice pro Sloučení Třídění bude vypadat takto:
$$
T(n) = 2T(\frac{n}{2})+cn
$$
Pokud použijeme Master Theorem, uvidíme, že náš případ je ten, kde a=b^k protože jsme 2=2^1. To znamená, že naše složitost je O (nlog n). Jedná se o velmi dobrou časovou složitost algoritmu třídění, protože bylo prokázáno, že pole nelze třídit rychleji než o(nlog n).,
zatímco verze, kterou jsme předvedli, je náročná na paměť, existují složitější verze sloučení, které zabírají pouze o(1) místo.
kromě toho je algoritmus velmi snadno rovnoběžný, protože rekurzivní hovory z jednoho uzlu lze spustit zcela nezávisle na samostatných větvích. I když se nebudeme zabývat tím, jak a proč, protože je to nad rámec tohoto článku, stojí za to mít na paměti výhody použití tohoto konkrétního algoritmu.,
Heapsort
vysvětlení
abyste správně pochopili, proč Heapsort funguje, musíte nejprve pochopit strukturu, na které je založen – haldu. Budeme mluvit konkrétně o binární haldě, ale většinu z toho můžete zobecnit i na jiné struktury haldy.
halda je strom, který splňuje vlastnost haldy, což znamená, že pro každý uzel jsou všechny jeho děti v daném vztahu k němu. Kromě toho musí být hromada téměř kompletní., Téměř úplný binární strom hloubky d má podstrom hloubky d-1 se stejným kořenem, který je kompletní, a ve kterém každý uzel s levým potomkem má kompletní levý podstrom. Jinými slovy, při přidávání uzlu vždy jdeme na pozici vlevo v nejvyšší neúplné úrovni.
Pokud je halda max-halda, pak jsou všechny děti menší než rodič, a pokud je to Min-halda, všechny jsou větší.,
jinými slovy, když se pohybujete po stromu, dostanete se k menším a menším číslům (min-halda) nebo větším a větším číslům (max-halda). Zde je příklad na max-haldy:
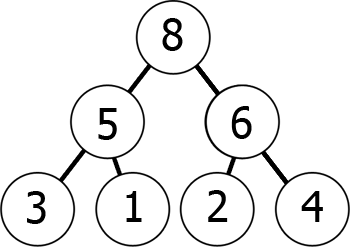
můžeme reprezentovat tohle max-haldy v paměti jako pole, a to následujícím způsobem:
8 5 6 3 1 2 4můžete Si to představit jako čtení z grafu úroveň podle úrovně, zleva doprava., To, čeho jsme dosáhli je to, že pokud budeme mít kth prvek v poli, jeho děti jsou pozice 2*k+1 2*k+2 (za předpokladu, že indexování začíná na 0). Můžete to zkontrolovat sami.
naopak pro prvekkth je pozice rodiče vždy (k-1)/2.
s tímto vědomím můžete snadno „max-heapify“ libovolné pole. U každého prvku zkontrolujte, zda je některé z jeho dětí menší než to., Pokud ano, vyměňte jeden z nich s rodičem a rekurzivně opakujte tento krok s rodičem (protože nový velký prvek může být stále větší než jeho druhé dítě).
Listy nemají žádné děti, takže jsou triviálně max-haldy jejich vlastní:
-
6 1 8 3 5 2 4: Obě děti jsou menší než rodiče, takže vše zůstane stejné.
-
6 1 8 3 5 2 4: Protože 5 > 1, vyměníme je. Rekurzivně heapify pro 5 Nyní.
-
6 5 8 3 1 2 4: obě děti jsou menší, takže se nic neděje.,
-
6 5 8 3 1 2 4: Protože 8 > 6, vyměníme je.
-
8 5 6 3 1 2 4: Máme haldu nahoře!
jakmile jsme se naučili heapify pole, zbytek je docela jednoduchý. Vyměníme kořen haldy s koncem pole a zkrátíme pole o jeden.,
Jsme heapify zkrácené pole znovu, a opakujte postup:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: vyměnil
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: vyměnil
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: vyměnil
A tak dále, jsem si jistý, můžete vidět vzor rozvíjející se.
Realizace
Doba Složitost
Když se podíváme na heapify() funkce, všechno se zdá být provedeno v O(1), ale pak je tu ten otravný rekurzivní volání.,
kolikrát to bude voláno, v nejhorším případě? V nejhorším případě se bude šířit až na vrchol hromady. Udělá to tak, že skočí na nadřazený uzel každého uzlu, takže kolem pozice i/2. to znamená, že bude dělat v nejhorším log n skoky před tím, než dosáhne vrcholu, takže složitost je O(log n).
, Protože heapSort() je zjevně O(n) vzhledem k pro-smyčky iterace přes celé pole, tím by se celková složitost Heapsort O(nlog n).,
Heapsort je in-place druh, což znamená, že to trvá O (1) další prostor, na rozdíl od sloučení třídění, ale má některé nevýhody, stejně, jako je obtížné paralelizovat.
Quicksort
vysvětlení
Quicksort je další algoritmus dělení a dobývání. Vybírá jeden prvek pole jako otočný čep a třídí všechny ostatní prvky kolem něj, například menší prvky vlevo a větší vpravo.
to zaručuje, že pivot je po procesu na správném místě., Pak algoritmus rekurzivně dělá totéž pro levou a pravou část pole.
Realizace
Doba Složitost
časová složitost Quicksort může být vyjádřena pomocí následující rovnice:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
nejhorší scénář je, když největší nebo nejmenší prvek je vždy vybral pro pivot. Rovnice by pak vypadala takto:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
To se ukázalo být O(n^2).,
to může znít špatně, protože jsme se již naučili více algoritmů, které běží v O (nlog n) čas jako jejich nejhorší případ, ale Quicksort je ve skutečnosti velmi široce používán.
je to proto, že má opravdu dobrý Průměrný runtime, také ohraničený O (nlog n), A je velmi efektivní pro velkou část možných vstupů.
Jedním z důvodů, proč je výhodné, aby Merge Sort je, že nezabere žádné místo navíc, všechny třídění je provedeno v místě, a tam je žádné drahé alokace a dealokace hovory.,
porovnání výkonu
to vše bylo řečeno, je často užitečné spustit všechny tyto algoritmy na vašem počítači několikrát, abyste získali představu o tom, jak fungují.
budou fungovat odlišně s různými sbírkami, které jsou samozřejmě seřazeny, ale i s ohledem na to byste si měli být schopni všimnout některých trendů.
Pojďme spustit všechny implementace, jeden po druhém, každý na kopii zamíchány pole 10 000 čísel:
můžeme zřejmě vidět, že Bublinkové Třídění je nejhorší, když jde o výkon., Nepoužívejte jej ve výrobě, pokud nemůžete zaručit, že zvládne pouze malé sbírky a aplikaci nezastaví.
HeapSort a QuickSort jsou nejlepší výkon-moudrý. I když jsou výstup podobné výsledky, QuickSort má tendenci být o něco lepší a důslednější – což se kontroluje.
Třídění v jazyce Java
Srovnatelné Rozhraní
Pokud máte vlastní typy, to může dostat těžkopádné provádění samostatné třídění algoritmus pro každou z nich. To je důvod, proč Java poskytuje rozhraní, které vám umožní používat Collections.sort() na svých vlastních třídách.,
K tomu, vaše třídy musí implementovat Comparable<T> rozhraní, kde T je váš typ, a přepsat metodu nazvanou .compareTo().
Tato metoda vrátí záporné číslo, pokud this je menší než argument prvek, 0 pokud jsou stejné, a kladné číslo, pokud this je větší.
V našem příkladu jsme udělali class Student, a každý student je identifikován pomocí id a o rok začali své studium.,
chceme, aby třídit je především tím, že generace, ale také sekundárně tím, že IDs:
A tady je, jak jej používat v aplikaci:
Výstup:
Rozhraní Comparator
chtěli Bychom nějak naše objekty v neortodoxní způsobem, pro konkrétní účel, ale nechceme realizovat, že jako výchozí chování naší třídy, nebo bychom mohli být třídění kolekce vestavěný typ v non-default.
k tomu můžeme použít rozhraní Comparator., Například, pojďme se náš Student třídy, a třídit pouze podle ID:
Pokud bychom nahradit druh volání v hlavním následující:
Arrays.sort(a, new SortByID());Výstup:
Jak to Funguje
Collection.sort() pracuje tím, že volá hlubších Arrays.sort() metoda, při třídění sám používá Insertion Sort pro pole kratší než 47, a Quicksort pro zbytek.,
je To založeno na konkrétní dva-otočné provedení Quicksort, který zajišťuje, že se vyhýbá většině typických příčin rozkladu na kvadratické výkon, podle JDK10 dokumentace.
Závěr
Třídění je velmi běžné operace se soubory dat, zda je analyzovat dále, zrychlit vyhledávání pomocí efektivnější algoritmy, které se spoléhají na data třídit, filtrovat data, atd.
třídění je podporováno mnoha jazyky a rozhraní často zakrývají to, co se programátorovi skutečně děje., Zatímco tato abstrakce je vítaná a nutná pro efektivní práci, to někdy může být smrtící pro účinnost, a je dobré vědět, jak realizovat různé algoritmy a být obeznámeni s jejich klady a zápory, stejně jako, jak snadno přístup k vestavěné implementace.