a jeho implementace v Pythonu
V tomto blogu jsme pokusím se hlouběji do Random Forest Taxonomie. Zde se dozvíme o ensemble learning a pokusíme se jej implementovat pomocí Pythonu.,
kód najdete zde.
jedná se o algoritmus učení založený na stromu. Random Forest Classifier je soubor rozhodovacích stromů z náhodně vybrané podmnožiny tréninkové sady. Shromažďuje hlasy z různých rozhodovacích stromů, aby rozhodl o konečné třídě testovaného objektu.
Ensemble algoritmus:
Ensemble algoritmy jsou ty, které kombinuje více než jeden algoritmy stejného nebo jiného druhu pro klasifikaci objektů. Například běh predikce přes naivní Bayes, SVM a rozhodovací strom a pak při hlasování pro konečné posouzení třídy pro testovací objekt.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., Horizontální a vertikální osy výše uvedených výstupů rozhodovacího stromu lze považovat za funkce x1 a x2. Při určitých hodnotách každé funkce vydává rozhodovací strom klasifikaci „modrá“, „zelená“, „červená“ atd.
Tyto výše uvedené výsledky jsou agregovány, a to prostřednictvím modelu hlasů, nebo v průměru, do jednoho
ensemble model, který skončí překonal žádné individuální rozhodovací strom je výstup.
vlastnosti a výhody náhodného lesa:
- Jedná se o jeden z nejpřesnějších dostupných učebních algoritmů. Pro mnoho datových sad vytváří vysoce přesný klasifikátor.,
- běží efektivně na velkých databázích.
- zvládne tisíce vstupních proměnných bez vymazání proměnné.
- poskytuje odhady toho, jaké proměnné jsou důležité v klasifikaci.
- generuje interní nezaujatý odhad chyby zobecnění, jak postupuje lesní budova.
- má účinnou metodu pro odhad chybějících dat a udržuje přesnost, když chybí velká část dat.,
nevýhody náhodného lesa:
- u některých datových sad s hlučnými klasifikačními / regresními úkoly byly pozorovány náhodné lesy.
- pro data včetně kategorických proměnných s různým počtem úrovní jsou náhodné lesy zaujaté ve prospěch těchto atributů s více úrovněmi. Variabilní skóre důležitosti z náhodného lesa proto není pro tento typ dat spolehlivé.,div>
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
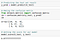
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Podívali jsme se na ensembled učení algoritmus v akci a snažil se pochopit, co dělá Random Forest jinou formu jiných algoritmů strojového učení.