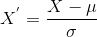Úvod do Funkce Škálování
byl jsem v poslední době pracuje s dataset, který měl více funkcí, zahrnující různé stupně závažnosti, rozsahu a jednotek. To je významná překážka, protože několik algoritmů strojového učení je na tyto funkce vysoce citlivých.
jsem si jistý, že většina z vás musela čelit tomuto problému ve vašich projektech nebo ve vaší vzdělávací cestě., Například jedna funkce je zcela v kilogramech, zatímco druhá je v gramech, další je litr a tak dále. Jak můžeme tyto funkce používat, když se liší tak výrazně, pokud jde o to, co prezentují?
zde jsem se obrátil na koncept škálování funkcí. Je to zásadní část fáze předzpracování dat, ale viděl jsem, že mnoho začátečníků to přehlíží (na úkor jejich modelu strojového učení).,

Tady je to zvláštní věc o funkci měřítka – to zlepšuje (výrazně) výkon některých algoritmů strojového učení a nefunguje vůbec pro ostatní. Co by mohlo být důvodem tohoto vtípku?
jaký je rozdíl mezi normalizací a standardizací? Jedná se o dvě z nejčastěji používaných technik škálování funkcí ve strojovém učení, ale v jejich porozumění existuje míra nejednoznačnosti. Kdy byste měli použít jakou techniku?,
odpovím na tyto otázky a další v tomto článku o škálování funkcí. Implementujeme také škálování funkcí v Pythonu, abychom vám poskytli praktické pochopení toho, jak funguje pro různé algoritmy strojového učení.
Poznámka: předpokládám, že jste obeznámeni s algoritmy Python a core machine learning., Pokud jste se na tento nový, doporučuji jít přes níže uvedené kurzy:
- Python pro Data Science
- Všechny free Machine Learning Kurzy Analytics Vidhya
- Aplikuje Strojového Učení
Obsah
- Proč bychom Měli Používat Funkce Škálování?
- co je normalizace?
- co je standardizace?
- velká otázka-normalizovat nebo standardizovat?,
- Prováděcí Funkce Škálování v Pythonu
- Normalizace pomocí Sklearn
- Standardizace pomocí Sklearn
- Použití Funkce změny Měřítka k Algoritmů Strojového Učení
- K-Nejbližších Sousedů (KNN)
- Podpora Vektorové Regressor
- Rozhodovací Strom
Proč bychom Měli Používat Funkce Škálování?
první otázka, kterou musíme řešit-proč potřebujeme škálovat proměnné v našem datovém souboru? Některé algoritmy strojového učení jsou citlivé na škálování funkcí, zatímco jiné jsou prakticky invariantní., Dovolte mi to vysvětlit podrobněji.
algoritmy založené na gradientu
algoritmy strojového učení, jako je lineární regrese,logistická regrese, neuronová síť atd. že použití gradient sestup jako optimalizační techniky vyžadují data, která mají být zmenšen. Podívejte se na vzorec pro gradientní sestup níže:

přítomnost hodnoty funkce X ve vzorci ovlivní velikost kroku gradientního sestupu. Rozdíl v rozsahu funkcí způsobí různé velikosti kroků pro každou funkci., Aby bylo zajištěno, že gradient sestupu se pohybuje plynule na minima a kroky pro gradientní sestup jsou aktualizovány ve stejné výši pro všechny funkce, jsme rozsahu údajů před krmením do modelu.
S vlastností v podobném rozsahu může pomoci gradientní sestup konvergovat rychleji směrem do minima.
algoritmy založené na vzdálenosti
algoritmy vzdálenosti jako KNN, k-means a SVM jsou nejvíce ovlivněny rozsahem funkcí., Je to proto, že v zákulisí používají vzdálenosti mezi datovými body k určení jejich podobnosti.
například, řekněme, že máme data obsahující vysoké škole CGPA skóre studentů (v rozmezí od 0 do 5) a jejich budoucí příjmy (v tisících Rupií):

Protože obě funkce mají různé váhy, tam je šance, že vyšší weightage je dána funkce s vyšší rozsah. To bude mít vliv na výkon algoritmu strojového učení a samozřejmě nechceme, aby byl náš algoritmus biassed k jedné funkci.,
Proto jsme rozsahu našich dat před upotřebením vzdálenosti na bázi algoritmu tak, aby všechny prvky přispívají stejně k výsledku.,nts a a B a mezi B a C, před a po změně měřítka, jak je uvedeno níže:
- Vzdálenost AB před scaling =>

- Vzdálenost BC před scaling =>

- Vzdálenost AB po scaling =>

- Vzdálenost BC po scaling =>

Škálování přinesl obou funkcí do obrazu a vzdálenosti jsou nyní více srovnatelné, než byly předtím, než jsme aplikovali změnu měřítka.,
stromové algoritmy
stromové algoritmy jsou naopak poměrně necitlivé na měřítko funkcí. Přemýšlejte o tom, rozhodovací strom rozděluje uzel pouze na základě jediné funkce. Rozhodovací strom rozdělí uzel na funkci, která zvyšuje homogenitu uzlu. Toto rozdělení na funkci není ovlivněno jinými funkcemi.
takže na rozdělení prakticky neexistuje žádný účinek zbývajících funkcí. To je to, co z nich dělá invariantní k rozsahu funkcí!
co je normalizace?,
normalizace je technika měřítka, ve které jsou hodnoty posunuty a rescaled tak, že skončí v rozmezí od 0 do 1. To je také známé jako Min-max měřítko.
zde je vzorec pro normalizaci:
zde jsou Xmax a Xmin maximální a minimální hodnoty funkce.,
- Kdy hodnota X je minimální hodnota ve sloupci, v čitateli bude 0, a tedy X‘ je 0,
- Na druhou stranu, když hodnota X je maximální hodnota ve sloupci, čitatel rovná jmenovateli a tedy hodnota X‘ je 1,
- je-Li hodnota X je mezi minimální a maximální hodnotou, pak je hodnota X‘ je mezi 0 a 1
Co je to Standardizace?
standardizace je další škálovací technika, kde jsou hodnoty soustředěny kolem průměru s jednotkovou směrodatnou odchylkou., To znamená, že průměr atributu se stává nulovým a výsledné rozdělení má jednotkovou směrodatnou odchylku.
Tady je vzorec pro standardizaci:
je střední hodnota funkce, hodnoty a
je směrodatná odchylka funkce hodnoty. Všimněte si, že v tomto případě nejsou hodnoty omezeny na určitý rozsah.
nyní musí být velkou otázkou ve vaší mysli, kdy bychom měli používat normalizaci a kdy bychom měli používat standardizaci? Pojďme to zjistit!,
velká otázka-normalizovat nebo standardizovat?
normalizace vs. standardizace je věčnou otázkou mezi nově příchozími strojového učení. Dovolte mi vypracovat odpověď v této části.
- normalizace je dobré použít, když víte, že distribuce vašich dat nesleduje Gaussovu distribuci. To může být užitečné v algoritmech, které nepředpokládají žádné rozdělení dat, jako jsou k-nejbližší sousedé a neuronové sítě.standardizace
- na druhé straně může být užitečná v případech, kdy data sledují Gaussovu distribuci., To však nemusí být nutně pravda. Také, na rozdíl od normalizace, standardizace nemá ohraničující rozsah. Takže i když máte ve svých datech odlehlé hodnoty, nebudou standardizací ovlivněny.
na konci dne však bude výběr použití normalizace nebo standardizace záviset na vašem problému a algoritmu strojového učení, který používáte. Neexistuje žádné tvrdé a rychlé pravidlo, které by vám řeklo, kdy normalizovat nebo standardizovat vaše data., Vždy můžete začít tím, že přizpůsobíte svůj model surovým, normalizovaným a standardizovaným datům a porovnáte výkon pro dosažení nejlepších výsledků.
je to dobrá praxe, aby se vešly škálovač na tréninkových dat a pak jej použít k transformaci testovacích dat. Tím by se zabránilo úniku dat během procesu testování modelu. Také měřítko cílových hodnot se obecně nevyžaduje.
Prováděcí Funkce Škálování v Pythonu
Nyní přichází zábavná část – uvedení toho, co jsme se naučili do praxe., Budu používat škálování funkcí na několik algoritmů strojového učení na datovém souboru Big Mart, který jsem vzal platformu DataHack.
přeskočím kroky předzpracování, protože jsou mimo rozsah tohoto tutoriálu. Ale najdete je úhledně vysvětlené v tomto článku. Tyto kroky vám umožní dosáhnout vrcholu 20 percentil na žebříčku hackathon, takže stojí za to vyzkoušet!
Takže, pojďme se nejprve rozdělit data do vzdělávání a testování sad:
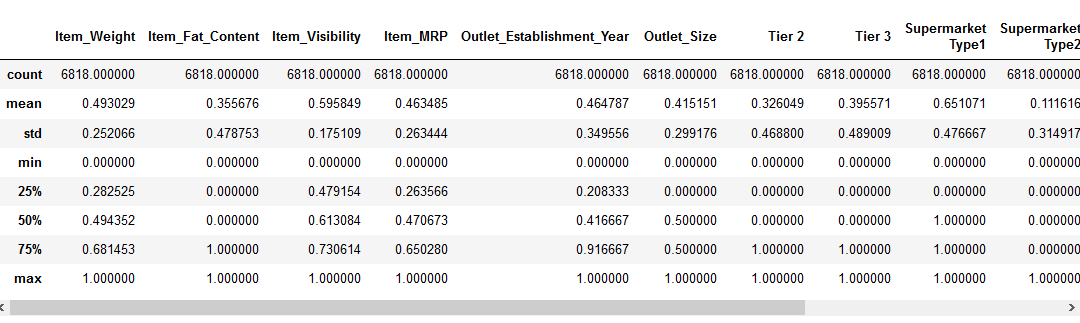
předtím, Než se stěhuje do funkce škálování část, pojďme se podívat na podrobnosti o našich údajů pomocí pd.,popište() metoda:
můžeme vidět, že tam je obrovský rozdíl v rozsahu hodnot přítomných v našem numerické vlastnosti: Item_Visibility, Item_Weight, Item_MRP, a Outlet_Establishment_Year. Zkusme to opravit pomocí škálování funkcí!
Poznámka: záporné hodnoty v Item_Visibility funkce, protože jsem si vzal log-transformace se vypořádat s šikmost ve funkci.
Normalizace pomocí sklearn
K normalizaci dat, musíte importovat MinMaxScalar z sklearn knihovna a aplikovat je na náš dataset., Tak, pojďme na to!
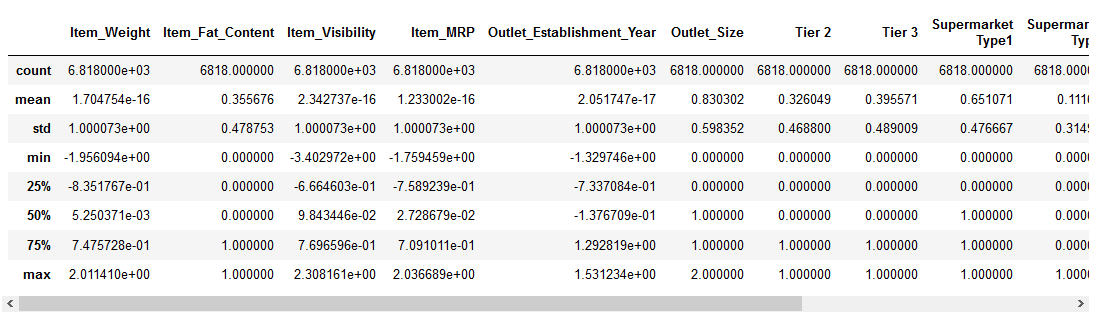
podívejme se, jak normalizace zasáhla náš dataset:
Všechny funkce nyní mají minimální hodnotu 0 a maximální hodnotu 1. Perfektní!
vyzkoušejte výše uvedený kód v okně live coding níže!!
dále se pokusíme standardizovat naše data.
Standardizace pomocí sklearn
standardizovat vaše data, budete muset importovat StandardScalar z sklearn knihovna a aplikovat je na náš dataset., Zde je návod, jak můžete to udělat:
Ty by si všimli, že jsem pouze aplikována standardizace mé číselné sloupce a ne druhý-Horký Zakódované vlastnosti. Standardizace funkcí zakódovaných za tepla by znamenala přiřazení distribuce kategorickým funkcím. To nechceš!
ale proč jsem neudělal totéž při normalizaci dat? Protože funkce zakódované jedním horkem jsou již v rozmezí od 0 do 1. Normalizace by tedy neovlivnila jejich hodnotu.,
Dobře, pojďme se podívat na to, jak standardizace, změnil naše údaje:
číselné funkce jsou nyní soustředil na mysli s jednotkovou směrodatnou odchylkou. Úžasné!
porovnání nezfalšovaných, normalizovaných a standardizovaných dat
je vždy skvělé vizualizovat vaše data, abyste pochopili přítomnou distribuci. Můžeme vidět srovnání mezi našimi nezfalšovanými a škálovanými daty pomocí boxplots.
více o vizualizaci dat se dozvíte zde.,
můžete si všimnout, jak škálování funkcí přináší vše do perspektivy. Funkce jsou nyní srovnatelnější a budou mít podobný účinek na modely učení.
Použití Škálování Algoritmů Strojového Učení
nyní je čas, aby se vlak některých algoritmů strojového učení na naše data k porovnání účinků různých škálovacích technik na výkon algoritmu. Chci vidět vliv škálování zejména na tři algoritmy: k-nejbližší sousedé, Support Vector Regressor a Decision Tree.,
k-nejbližší sousedé
jak jsme viděli dříve, KNN je algoritmus založený na vzdálenosti, který je ovlivněn rozsahem funkcí. Podívejme se, jak to funguje na našich datech, před a po škálování:
můžete vidět, že škálování funkcí snížilo skóre RMSE našeho modelu KNN. Konkrétně normalizovaná data jsou o něco lepší než standardizovaná data.
Poznámka: měřím zde RMSE, protože tato soutěž hodnotí RMSE.
Support Vector Regressor
SVR je další algoritmus založený na vzdálenosti., Pojďme se tedy podívat, zda funguje lépe s normalizací nebo standardizací:
vidíme, že škálování funkcí snižuje skóre RMSE. A standardizovaná data fungovala lépe než normalizovaná data. Proč si myslíte, že tomu tak je?
dokumentace sklearn uvádí, že SVM s jádrem RBF předpokládá, že všechny funkce jsou soustředěny kolem nuly a rozptyl je stejného pořadí. Je to proto, že funkce s rozptylem větším než ostatní brání odhadci učit se ze všech funkcí., Skvělé!
rozhodovací strom
již víme, že rozhodovací strom je invariantní pro škálování funkcí. Ale já jsem chtěl ukázat praktický příklad, jak se to provádí na data:
můžete vidět, že RMSE skóre se ani nepohnula na škálování funkce. Takže buďte ujištěni, když používáte stromové algoritmy na vašich datech!,
Poznámky
Tento návod se vztahuje význam pomocí funkce škálování na vaše data a jak normalizace a standardizace mají různé účinky na fungování algoritmů strojového učení
Mějte na paměti, že neexistuje žádná správná odpověď na to, kdy použít normalizaci v průběhu standardizace a vice-versa. Vše závisí na vašich datech a algoritmu, který používáte.
jako další krok vám doporučuji vyzkoušet škálování funkcí s jinými algoritmy a zjistit, co funguje nejlépe – normalizace nebo standardizace?, Doporučuji použít data prodeje BigMart pro tento účel k udržení kontinuity s tímto článkem. A nezapomeňte se podělit o své postřehy v sekci komentáře níže!
tento článek si můžete také přečíst v naší mobilní aplikaci